LLM in a flash: Efficient Large Language Model Inference with Limited Memory
Keivan Alizadeh, Iman Mirzadeh*, Dmitry Belenko*, S. Karen Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, Mehrdad Farajtabar Apple †
摘要
大型语言模型 (LLMs) 是现代自然语言处理的核心,在各种任务中提供了卓越的性能。然而,它们巨大的计算和内存需求带来了挑战,特别是对于 DRAM 容量有限的设备。本文解决了在超过可用 DRAM 容量的情况下高效运行 LLM 的挑战,方法是将模型参数存储在闪存中,并按需将其调入 DRAM。我们的方法包括构建一个考虑闪存特性的推理成本模型,指导我们在两个关键领域进行优化:减少从闪存传输的数据量,以及以更大、更连续的块读取数据。在这个硬件感知框架内,我们引入了两种主要技术。首先,“窗口化”(windowing)通过重用先前激活的神经元来策略性地减少数据传输;其次,“行列捆绑”(row-column bundling)针对闪存的顺序数据访问优势进行了定制,增加了从闪存读取的数据块大小。这些方法共同使得运行模型的大小可达可用 DRAM 的两倍,与 CPU 和 GPU 上的原始加载方法相比,推理速度分别提高了 4 倍和 20 倍。我们将稀疏性感知、上下文自适应加载和面向硬件的设计集成在一起,为在内存受限的设备上进行有效的 LLM 推理铺平了道路。
1 引言
近年来,大型语言模型 (LLMs) 在广泛的自然语言任务中表现出了强大的性能 (Brown et al., 2020; Chowdhery et al., 2022; Touvron et al., 2023a; Jiang et al., 2023; Gemini Team, 2023)。
然而,这些模型前所未有的能力带来了巨大的计算和内存推理需求。LLMs 可以包含数千亿甚至数万亿个参数,这使得它们难以高效加载和运行,尤其是在个人设备上。
目前,推理的标准方法是将整个模型加载到 DRAM(动态随机存取存储器)中 (Rajbhandari et al., 2021; Aminabadi et al., 2022)。然而,这严重限制了可以运行的最大模型大小。例如,一个 70 亿参数的模型仅以半精度浮点格式加载参数就需要超过 14GB 的内存,这超过了大多数个人设备(如智能手机)的能力。虽然可以使用量化等技术来减小模型大小,但这仍然无法解决将整个模型加载到 DRAM 中的主要限制。
为了解决这一限制,我们建议将模型参数存储在闪存中,其容量至少比 DRAM 大一个数量级。然后,在推理过程中,我们直接从闪存加载所需的参数子集,从而避免了将整个模型放入 DRAM 的需求。为此,我们的工作做出了以下贡献:
- 首先,我们研究了存储系统(例如闪存、DRAM)的硬件特性。我们表明,容量和带宽限制等硬件约束在设计从闪存服务 LLM 的高效算法时具有重要的考量因素(第 2 节)。
- 受我们的发现启发,我们提出了几种技术,可以帮助 (i) 减少所需的数据传输,(ii) 提高传输吞吐量,以及 (iii) 在 DRAM 中高效管理已加载的参数(第 3 节)。
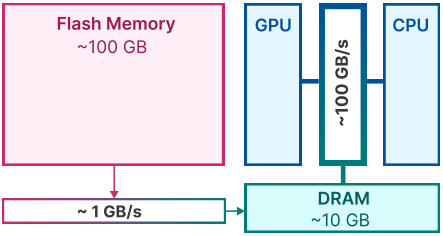
- 最后,正如在图 1 中部分展示的那样,我们证明了我们提出的优化成本模型和按需选择性加载参数的技术,使我们能够运行比设备 DRAM 容量大 2 倍的模型,并与 CPU、Metal 和 NVIDIA GPU 后端上的原始实现相比,推理速度分别提高了 4 倍、7 倍和 20 倍(第 4 节)。
2 闪存与 LLM 推理
在本节中,我们探讨存储系统(例如闪存、DRAM)的特性及其对大型语言模型 (LLM) 推理的影响。我们旨在了解算法设计中必不可少的挑战和特定于硬件的考量因素,特别是在优化使用闪存时的推理方面。
2.1 带宽和能量约束
虽然现代 NAND 闪存提供高带宽和低延迟,但在延迟和吞吐量方面都远未达到 DRAM(动态随机存取存储器)的性能水平。图 2a 说明了这些差异。一种依赖 NAND 闪存的原始推理实现可能需要在每次前向传递时重新加载整个模型。这个过程不仅耗时,通常即使对于压缩模型也需要几秒钟,而且它消耗的能量也比从 DRAM 传输数据到 CPU 或 GPU 的内部内存消耗的能量更多。
即使在传统的 DRAM 常驻设置中,模型加载时间也可能是一个问题,因为权重不会部分重新加载——模型的初始完整加载仍然会产生惩罚,特别是在需要快速响应第一个 token 的情况下。我们的方法利用 LLM 中的激活稀疏性,通过实现模型权重的选择性读取来解决这些挑战,从而减少响应延迟。
2.2 读取吞吐量
闪存系统在进行大块顺序读取时表现最佳。例如,在配备 1TB 闪存的 Apple MacBook M1 Max 上进行的基准测试表明,对于 1GiB 未缓存文件的线性读取,速度超过 6 GiB/s。然而,由于这些读取固有的多阶段性质(包括操作系统、驱动程序、中断处理和闪存控制器等),这种高带宽无法用于较小的随机读取。每个阶段都会引入延迟,不成比例地影响较小的读取。
为了规避这些限制,我们提倡两种主要策略,可以联合使用。第一种涉及读取更大的数据块。对于较小的块,大部分总读取时间都花在等待数据传输开始上。这通常被称为“首字节延迟”(latency to first byte)。这种延迟大大降低了每次读取操作的总吞吐量,因为总的测量吞吐量不仅要考虑传输开始后的速度,还要考虑开始前的延迟,这会惩罚小块读取。这意味着,如果我们合并 FFN 矩阵的行和列的读取,我们可以在两个矩阵中为任何给定的行/列对仅支付一次延迟成本,从而实现更高的吞吐量。这一原则在图 2b 中得到了体现。一个反直觉但有趣的观察是,在某些情况下,读取比需要更多的内容(但以更大的块)然后丢弃,比仅读取严格必要的部分但以较小的块读取更值得。第二种策略利用并行读取,利用存储堆栈和闪存控制器内的固有并行性。我们的结果表明,在现代硬件上,使用 32KiB 或更大的跨多个线程的随机读取,可以实现适合稀疏 LLM 推理的吞吐量。
受本节所述挑战的启发,在第 3 节中,我们提出了优化数据传输量和提高读取吞吐量的方法,以显著提高推理速度。
3 从闪存加载
本节解决了在可用 DRAM 远小于模型大小的设备上进行推理的挑战。这需要将完整的模型权重存储在闪存中。我们评估各种闪存加载策略的主要指标是延迟,将其分解为三个不同的组成部分:从闪存加载的 I/O 成本、管理新加载数据的内存开销以及推理操作的计算成本。
我们提出的减少内存约束下延迟的解决方案分为以下几个领域:
- 减少数据加载:旨在通过加载更少的数据来减少与闪存 I/O 操作相关的延迟。
- 优化数据块大小:通过增加加载的数据块大小来增强闪存吞吐量,从而减轻延迟。
- 高效管理已加载数据:简化数据加载到内存后的管理,以最大限度地减少开销。
需要注意的是,我们的重点不在于优化计算,因为它与我们工作的核心关注点是正交的。相反,我们专注于优化闪存交互和内存管理,以在内存受限的设备上实现高效推理。我们将在实验设置部分详细阐述这些策略的实现细节。
3.1 减少数据传输
我们的方法利用了前人研究中记录的 Feed-Forward Network (FFN) 模型中固有的激活稀疏性。例如,OPT 6.7B 模型在其 FFN 层内表现出显著的 97% 稀疏性。同样,Falcon 7B 模型也通过微调进行了适配,这涉及将其激活函数交换为 ReLU,从而在保持相似精度的同时实现了 95% 的稀疏性 (Mirzadeh et al., 2023)。通过 FATReLU 替换 Llama 2 模型 (Touvron et al., 2023b) 的激活函数并进行微调,可以实现 90% 的稀疏性 (Song et al., 2024)。鉴于此信息,我们的方法涉及在推理过程中仅将权重的必要动态子集从闪存迭代传输到 DRAM 进行处理。
选择性持久化策略。我们选择将 transformer 注意力机制中的嵌入和矩阵持续保留在 DRAM 中。对于 Feed-Forward Network (FFN) 部分,仅根据需要将非稀疏段动态加载到 DRAM 中。将约占模型大小三分之一的注意力权重保留在内存中,允许更高效的计算和更快的访问,从而在无需完整模型加载的情况下增强推理性能。
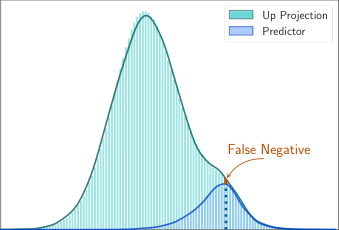
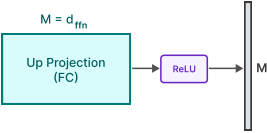
预期 ReLU 稀疏性。ReLU 激活函数自然会在 FFN 的中间输出中诱导超过 90% 的稀疏性,这减少了利用这些稀疏输出的后续层的内存占用。然而,前一层,即上投影(up project),必须完全存在于内存中。
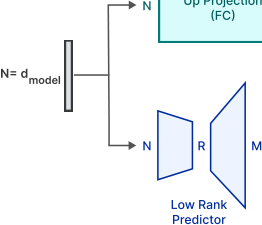
为了避免加载整个上投影矩阵,我们遵循 Liu et al. (2023b),并采用低秩预测器来识别被 ReLU 置零的元素(见图 3b)。我们对每一层的负样本和正样本使用了平衡损失。与他们的工作相比,我们的预测器只需要当前层注意力模块的输出,而不需要前一层的 FFN 模块。我们观察到,将预测推迟到当前层对于硬件感知权重加载算法设计是足够的,并且由于延迟输入而导致更准确的结果。我们使用了来自 C4 训练数据集的 10000 个样本进行了 2 个 epoch 的训练。在 A100 GPU 上训练每个预测器花费了 4 小时。
因此,我们仅加载预测器指示的元素,如图 3a 所示。此外,如表 1 所示,使用预测器不会对模型在 0-shot 任务中的性能产生不利影响。更多详细信息请参考附录 B。
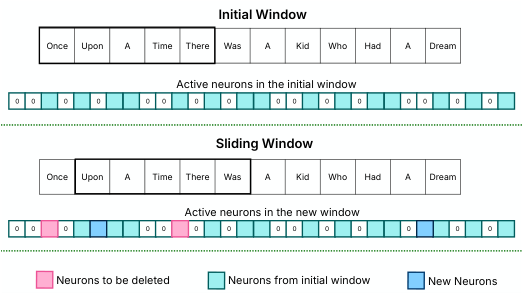
滑动窗口技术。在我们的研究中,我们将“活跃神经元”定义为在我们的低秩预测器模型中产生正输出的神经元。我们的方法专注于通过采用“滑动窗口技术”来管理神经元数据。该技术需要维护一个 DRAM 缓存,其中仅包含预测为最近输入 token 子集所需的权重行。该技术的关键方面是增量加载当前输入 token 与其直接前驱之间不同的神经元数据。这种策略允许高效的内存利用,因为它释放了先前分配给滑动窗口内不再需要的 token 所需的缓存权重所占用的内存资源(如图 4b 所示)。
从数学角度来看,令 表示跨 个输入 token 序列的神经元数据的累积使用量。我们的内存架构旨在在 DRAM 中存储 的平均值。当我们处理每个新 token 时,数学上表示为 的增量神经元数据会从闪存加载到 DRAM 中。这种做法基于观察到的聚合神经元使用量随时间减少的趋势。因此,较大的 值会导致每个新 token 加载的数据量较少(参考图 4a),而较小的 值有助于节省用于存储缓存权重的 DRAM。在确定滑动窗口大小时,目标是在可用内存容量施加的约束内最大化它。
3.2 增加传输吞吐量
为了增加从闪存读取的数据吞吐量,关键是以更大的块读取数据,最好是底层存储池块大小的倍数。在本节中,我们详细介绍了我们为增加块大小以实现更高效的闪存读取而采用的策略。
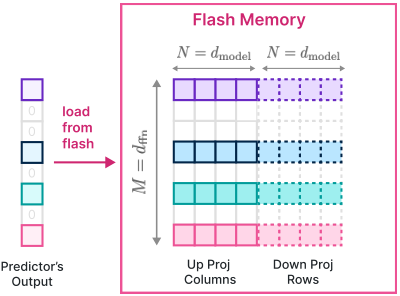
捆绑列和行。注意,在 FFN 层中,来自上投影的第 列和来自下投影的第 行的使用与第 个中间神经元的激活相吻合。因此,通过将这些对应的列和行存储在闪存中,我们可以将数据合并为更大的块进行读取。参考图 5 以获取此捆绑方法的说明。如果网络的每个权重元素存储在 num_bytes 中,这种捆绑将块大小从 加倍到 ,如图 5 所示。我们的分析和实验表明,这增加了模型的吞吐量。
基于共激活的捆绑。我们假设神经元可能表现出高度相关的活动模式,从而实现捆绑。通过分析 C4 验证数据集上的激活,我们发现了共激活的幂律分布。然而,将神经元与其最高共激活神经元(最亲密的朋友)捆绑在一起,导致了高活跃神经元的多次加载,抵消了我们的目标。这一结果表明,非常活跃的神经元是许多其他神经元的“最亲密朋友”。我们展示这个负面结果是为了激发未来关于有效神经元捆绑以实现高效推理的研究。请参考附录 D 了解详情。
值得注意的是,通过“数据”,我们通常指的是神经网络的权重。然而,正如 Sheng et al. (2023) 所建议的那样,我们开发的技术可以轻松推广到为 LLM 推理传输和使用的其他数据类型,例如激活或 KV 缓存。

| 零样本任务 | OPT 6.7B | 带预测器 |
|---|---|---|
| Arc Easy | 66.1 | 66.2 |
| Arc Challenge | 30.6 | 30.6 |
| HellaSwag | 50.3 | 49.8 |
3.3 DRAM 中的优化数据管理
尽管 DRAM 内的数据传输比访问闪存更高效,但它仍然产生不可忽略的成本。当引入新神经元的数据时,重新分配矩阵和附加新矩阵会导致显著的开销,因为需要重写 DRAM 中现有的神经元数据。当 DRAM 中 Feed-Forward Networks (FFNs) 的很大一部分(约 25%)需要重写时,这一点尤其昂贵。为了解决这个问题,我们采用了一种替代的内存管理策略。这涉及预分配所有必要的内存并建立相应的数据结构以进行高效管理。该数据结构包含如图 6 所示的指针、矩阵、偏置、num_used 和 last_k_active 等元素。
矩阵中的每一行代表一个神经元的“上投影”行和“下投影”列的串联。指针向量指示矩阵中每一行对应的原始神经元索引。原始模型中“上投影”的偏置由相应的偏置元素表示。num_used 参数跟踪矩阵中当前利用的行数,初始设置为零。第 层的矩阵预分配大小为 ,其中 表示 C4 验证集子集中指定窗口大小所需的最大神经元数量。通过提前为每一层分配足够的内存,我们最大限度地减少了重新分配的需求。最后,last_k_active 组件识别原始模型中最近使用最后 个 token 激活的神经元。以下操作可以按照图 6 所示进行:
- 删除神经元:利用关联的
last_k_active值和当前预测,在线性时间内高效识别不再需要的神经元。这些冗余神经元的矩阵、指针和标量被最近的元素替换,并且它们的计数从num_rows中减去。对于要删除的 个神经元,需要 数量级的内存重写。 - 引入新神经元:从闪存中检索所需的权重。从 DRAM 中读取相应的指针和标量,然后将这些行插入矩阵中,从
num_row扩展到num_row + num_new。这种方法消除了在 DRAM 中重新分配内存和复制现有数据的需求,从而减少了推理延迟。 - 推理过程:对于推理操作,矩阵
matrix[:num_rows,:d_model]的前半部分用作“上投影”,转置的后半部分matrix[:num_rows,d_model:].transpose()用作“下投影”。这种配置是可能的,因为 FFN 中间输出中神经元的顺序不会改变最终输出,从而允许简化的推理过程。
这些步骤共同确保了推理过程中的高效内存管理,优化了神经网络的性能和资源利用率。
4 实验与结果
我们通过简要讨论我们的实验设置和实现细节来开始本节。接下来,我们展示第 3 节中介绍的技术可以显著改善不同模型和运行时平台上的推理延迟。我们将一些细节推迟到附录部分:我们训练的低秩预测器的性能(附录 B)。
4.1 实验设置
我们的工作主要受优化个人设备上的推理效率的驱动。为此,在我们的实验中,我们单独处理序列,一次只运行一个序列。这种方法允许我们为 Key-Value (KV) 缓存分配 DRAM 的特定部分,同时主要关注模型大小。对于我们推理过程的实现,我们利用 HuggingFace Transformers 库 (Wolf et al., 2019) 和 PyTorch (Paszke et al., 2019)。此设置在 DRAM 中大约有模型大小的一半可用的条件下进行测试。虽然通过不同水平的稀疏性或采用量化,可以在更小的可用 DRAM 容量下工作,但这些优化与我们提出的方法是正交的。
模型。我们主要使用 OPT 6.7B (Zhang et al., 2022b) 和稀疏化 Falcon 7B (Mirzadeh et al., 2023) 模型进行评估,但我们还额外报告了 Phi-2 (Gunasekar et al., 2023)、Persimmon 8B (Elsen et al., 2023) 和 Llama 2 (Touvron et al., 2023b) 的结果,后者使用 FATReLU (Song et al., 2024) 进行了稀疏化。请注意,本工作中介绍的技术在很大程度上与架构无关。
数据。我们使用 C4 验证数据集的一个小子集进行延迟测量。我们取每个示例的前 128 个 token 作为提示,并生成 256 个新 token。
硬件配置。我们的模型在三种硬件设置上进行了评估。第一种包括配备 1TB SSD 的 Apple M1 Max。第二种具有配备 2TB SSD 的 Apple M2 Ultra。在 MacBooks 上,我们在带有 float32 的 CPU 或带有 Metal 和 float16 的 GPU 上运行模型。第三种设置使用带有 24GB NVIDIA RTX 4090 的 Linux 机器,其中 GPU 计算利用 bfloat16 模型。在所有设置中,我们假设大约一半的总内存(DRAM 和 GPU)分配给模型计算。
基线。我们将我们的模型与在进行前向传递时按需加载模型的原始基线进行了比较。我们还与我们的混合加载方法作为次要基线进行了比较,其中一半模型保留在内存中,另一半在生成每个 token 时按需加载,而不使用稀疏性。我们为每种方法的 IO 延迟使用了最佳理论可能数字,以进行公平比较,实际数字可能会更高。对于不采用稀疏性或权重共享的方法,在前向传递期间必须从闪存传输至少一半的模型。这种必要性产生是因为最初只有一半的模型在 DRAM 中可用,但随着前向传递的进行,整个模型容量被利用。因此,开始时不存在的任何数据必须至少传输一次。因此,最高效的理论基线涉及将一半的模型大小从闪存加载到 DRAM 中。这种最优的 I/O 场景作为我们的主要基线。鉴于我们设置的性质(即有限的可用 DRAM 或 GPU 内存),我们不知道有任何其他方法可以超越这种理论上的 I/O 效率。
实现细节。为了优化从闪存加载数据,我们的系统采用了跨 32 个线程并行化的读取。这种多线程方法旨在通过不按顺序等待每次读取来更好地摊销首字节延迟,并通过一次读取多个流来最大化读取吞吐量(图 2b)。为了更好地评估实际吞吐量,我们在没有操作系统缓存辅助的情况下进行了基准测试,从而获得了更准确的测量结果。
| 配置 | 性能指标 | ||||||
|---|---|---|---|---|---|---|---|
| 混合 | 预测器 | 窗口化 | 捆绑 | DRAM (GB) | 闪存→DRAM (GB) | 吞吐量 (GB/s) | I/O 延迟 (ms) |
| ✗ | ✗ | ✗ | ✗ | 0 | 13.4 GB | 6.10 GB/s | 2196 ms |
| ✓ | ✗ | ✗ | ✗ | 6.7 | 6.7 GB | 6.10 GB/s | 1090 ms |
| ✓ | ✓ | ✗ | ✗ | 4.8 | 0.9 GB | 1.25 GB/s | 738 ms |
| ✓ | ✓ | ✓ | ✗ | 6.5 | 0.2 GB | 1.25 GB/s | 164 ms |
| ✓ | ✓ | ✓ | ✓ | 6.5 | 0.2 GB | 2.25 GB/s | 87 ms |
4.2 更快的从闪存加载
我们在表 2 中的第一个结果证明了我们在第 3 节中介绍的技术的有效性,其中 I/O 延迟取决于从闪存传输到 DRAM 的数据量,以及决定吞吐量的块大小。例如,通过使用低秩预测器,我们显著减少了数据传输,并且可以使用我们提出的窗口化技术进一步减少这种流量。与长、连续的读取相比,分散的读取必然会导致更低的吞吐量(例如 1.25 GiB/s 稀疏 vs 6.1 GiB/s 密集),但这通过捆绑上投影和下投影权重得到了部分缓解。稀疏读取的整体效果仍然非常有利,因为在每次迭代中仅增量加载整体权重的一小部分,并且仅加载所需权重子集的负载花费的时间更少,占用的 DRAM 也更少。
此外,我们在表 3 中检查了各种设置下的端到端延迟。我们为 OPT、Falcon、Persimmon 和 Llama 2 分配了大约 50% 的模型大小。对于明显更小的 Phi-2 模型,我们观察到稀疏率更低,促使我们将此限制设置为 65%。我们观察到所有模型在加载效率上都比原始和混合方法有显著改善。此外,我们展示了当与推测性解码结合时,GPU 后端的结果进一步改善。
| 模型 | 方法 | 后端 | I/O | Mem | 计算 | 总计 |
|---|---|---|---|---|---|---|
| OPT 6.7B | 原始 | CPU | 2196 | 0 | 986 | 3182 |
| OPT 6.7B | All | CPU | 105 | 58 | 506 | 669 |
| OPT 6.7B | 原始 | Metal M1 | 2196 | 0 | 193 | 2389 |
| OPT 6.7B | All | Metal M1 | 92 | 35 | 438 | 565 |
| OPT 6.7B | 原始 | Metal M2 | 2145 | 0 | 125 | 2270 |
| OPT 6.7B | All | Metal M2 | 26 | 8 | 271 | 305 |
| OPT 6.7B | 原始 | GPU | 2196 | 0 | 22 | 2218 |
| OPT 6.7B | All | GPU | 30 | 34 | 20 | 84 |
| OPT 6.7B | 推测性 | GPU | 38.5 | 9.5 | 12 | 60 |
| Falcon 7B | 原始 | CPU | 2295 | 0 | 800 | 3095 |
| Falcon 7B | 混合 | CPU | 1147 | 0 | 800 | 1947 |
| Falcon 7B | All | CPU | 161 | 92 | 453 | 706 |
| Persimmon 8B | 原始 | CPU | 2622 | 0 | 1184 | 3806 |
| Persimmon 8B | 混合 | CPU | 1311 | 0 | 1184 | 2495 |
| Persimmon 8B | All | CPU | 283 | 98 | 660 | 1041 |
| Phi-2 2.7B | 原始 | CPU | 885 | 0 | 402 | 1287 |
| Phi-2 2.7B | 混合 | CPU | 309 | 0 | 402 | 711 |
| Phi-2 2.7B | All | CPU | 211 | 76 | 259 | 546 |
| Llama 2 7B | 原始 | CPU | 2166 | 0 | 929 | 3095 |
| Llama 2 7B | 混合 | CPU | 974 | 0 | 929 | 1903 |
| Llama 2 7B | All | CPU | 279 | 152 | 563 | 994 |
4.3 内存-延迟权衡
到目前为止,我们主要在可用 DRAM 大约为我们模型大小的一半的假设下工作。然而,我们注意到这不是一个硬性约束,我们可以放宽这个约束。
为此,我们研究了窗口大小对内存使用量以及随之而来的延迟的影响。通过增加窗口大小,我们增加了保留在 DRAM 中的模型参数的百分比。因此,我们需要带入更少的参数,从而可以以使用更高 DRAM 为代价来减少延迟,如图 7 所示。
5 消融分析
5.1 更长生成的冲击
在之前的实验结果中,我们使用了短到中等长度(256 个 token)的生成来进行基准测试。对于更长的 token 生成,SSD 可能会启用热节流并降低性能。然而,图 8 显示并非如此,即使我们在 GPU 上为 OPT 6.7B 模型生成 1000 个 token。此外,我们展示了平均闪存延迟不会随着生成的深入而增加。相反,前几个 token 的闪存延迟更高,因为 DRAM 中分配的内存是空的,需要填充神经元,并且对于前几个 token,我们需要更多的数据传输。
也可以认为非贪婪采样方法(如 Nucleus 采样 (Holtzman et al., 2020))可能导致更多样化的激活,从而对我们的方法不太有利。我们发现对于长 token 生成也不是这种情况。Nucleus 采样在 CPU 或 GPU 上的长生成中都不会导致性能下降。
5.2 推测性解码
为了进一步展示我们方法的强度和对其他解码策略的适应性,我们将推测性解码应用于 OPT 6.7B 模型。进行推测性解码的挑战是 DRAM 内可用的内存有限。给定来自草稿模型的 个 token,大模型验证它们,并将为每一层保留一个大小为 的窗口。模型应该在验证完成之前决定保留哪些 token 的神经元在内存中。如果模型在内存中保留了 个 token 中的最后 个 token,并且其中大多数被拒绝,那么下一次前向传递的神经元重用将非常少。我们推测,如果接受率为 ,则在 DRAM 中保留以 个 token 结尾的最后 个 token 是最优的。我们使用了 ,并能够将解码速度提高 1.4 倍,如表 5 所示,这接近推测性解码原始的 1.58 倍加速。

5.3 关于功耗的说明
在评估我们方法的效率时,我们将我们稀疏模型方法的功耗与使用类似大小的密集模型生成 token 的功耗进行了比较。虽然稀疏模型的功耗(单位时间的能量)低于密集模型,但 token 生成所需的延长持续时间导致稀疏模型具有更高的总能耗。这将在绘制稀疏模型与密集模型随时间变化的功率曲线时,反映在更大的曲线下面积中。对精确功耗模式的系统和定量评估留作未来工作。
6 相关工作
随着 LLMs 规模的增长,减少其推理的计算和内存需求已成为一个活跃的研究领域。方法大致分为两类:模型压缩技术,如剪枝和量化 (Han et al., 2016b; Sun et al., 2023; Jaiswal et al., 2023; Xia et al., 2023; Zhang et al., 2022a; Xu et al., 2023; Shao et al., 2023; Lin et al., 2023; Hoang et al., 2023; Zhao et al., 2023; Ahmadian et al., 2023; Li et al., 2023),以及选择性执行,如稀疏激活 (Liu et al., 2023b; Mirzadeh et al., 2023) 或条件计算 (Graves, 2016; Baykal et al., 2023)。我们的工作与这些方向是正交的,主要专注于在推理过程中最小化从闪存的数据传输。
与我们工作最相关的是关于选择性权重加载的文献。Dejavu (Liu et al., 2023b) 利用激活稀疏性为每一层加载权重子集。然而,它仍然需要从 GPU 内存加载。FlexGen (Sheng et al., 2023) 将权重和 KV 缓存从 GPU 内存卸载到 DRAM,再从 DRAM 卸载到闪存。相比之下,我们仅考虑完整模型无法驻留在边缘设备上的整个 DRAM 和 GPU 内存中的情况。值得注意的是,在这种场景下,FlexGen 在理论上仍然受到闪存到 DRAM 缓慢吞吐量的限制。相关工作的扩展讨论推迟到附录 E。
总体而言,文献中的主要假设是模型可以完全驻留在 GPU 内存或系统 DRAM 中。然而,考虑到个人设备上可用的有限资源,我们在本工作中不共享此假设。相反,我们专注于探索如何更高效地在闪存上存储和加载参数,旨在提高推理效率。
7 讨论
在本研究中,我们解决了在内存容量受限的设备上运行大型语言模型 (LLMs) 的重大挑战。我们的方法深深植根于对闪存和 DRAM 特性的理解,代表了硬件感知策略和机器学习的一种新颖融合。通过开发一种与这些硬件约束相一致的推理成本模型,我们引入了两种新技术:“窗口化”和“行列捆绑”。
我们研究的实际成果是值得注意的。我们证明了运行高达可用 DRAM 两倍大小的 LLMs 的能力。例如,在 OPT 模型上,与 CPU 中的传统加载方法相比,我们实现了 4-5 倍的推理速度加速,在 GPU 中实现了 20-25 倍的加速。这对于在资源受限的环境中部署 LLMs 尤为关键,从而扩展了它们的适用性和可访问性。
虽然在这项工作中我们研究了从闪存服务 LLMs 这一此前未探索的问题,但我们注意到这项工作只是朝着这个方向迈出的第一步,并且有几个局限性,我们将在下一节中讨论,我们相信在未来的工作中还有几个有趣的问题有待探索。例如,从算法角度来看,可以设计更优化的权重捆绑和数据结构技术,而从工程角度来看,特定硬件平台的特性可以为构建更高效的推理堆栈的工作提供信息。
8 局限性
我们的研究代表了在追求民主化大型语言模型 (LLM) 推理方面的一项初步努力,使其能够被更广泛的个人和设备所访问。我们认识到这一早期努力的局限性,这反过来又为未来的研究开辟了引人注目的途径。未来探索的一个关键方面是对我们提出的方法中固有的功耗和热限制进行系统分析,特别是在设备端部署方面。
目前,我们的研究仅限于单批次推理。我们提供了一些关于将我们提出的想法与推测性解码相结合的初步结果,然而,将其扩展到包括提示处理和多批次推理在内的更复杂场景是进一步研究的有价值领域。
在我们的初步概念验证中,我们是在内存可用性为模型大小一半的假设下运行的。探索使用不同内存大小(更大和更小)的动态特性,引入了延迟和准确性之间迷人的平衡,是一个引人注目的未来探索领域。
总之,我们的方法建立在稀疏化网络的基础上。尽管如此,其基本概念在更广泛的应用中具有潜力。它可以被调整为选择性地加载非稀疏网络中的权重,或者从闪存存储中动态检索模型权重。这种调整将取决于输入提示或提供的上下文参数的具体要求。这种方法提出了一种管理模型权重的通用策略,并根据输入的性质优化性能,从而增强了所提出方案在处理大型语言模型 (LLMs) 的各种场景中的效率、实用性和适用性。
致谢
我们要感谢 Itay Sagron、Lailin Chen、Chenfan (Frank) Sun、Hanieh Hashemi、Mahyar Najibi、Qichen Fu、Moin Nabi、Peter Zatloukal、Arsalan Farooq、Sachin Mehta、Mohammad Samragh、Matt Johnson、Etai Zaltsman、Lin Chang、Dominic Giampaolo、Tal Uliel、Hadi Pouransari、Fartash Faghri、Oncel Tuzel、Samy Bengio、Ruoming Pang、Chong Wang、Ronan Collobert、David Grangier 和 Aftab Munshi 的宝贵讨论。
参考文献
Arash Ahmadian, Saurabh Dash, Hongyu Chen, Bharat Venkitesh, Stephen Gou, Phil Blunsom, A. Ustun, and Sara Hooker. 2023. Intriguing properties of quantization at scale. ArXiv, abs/2305.19268.
Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Maitha Alhammadi, Mazzotta Daniele, Daniel Heslow, Julien Launay, Quentin Malartic, Badreddine Noune, Baptiste Pannier, and Guilherme Penedo. 2023. The falcon series of language models: Towards open frontier models.
Reza Yazdani Aminabadi, Samyam Rajbhandari, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Olatunji Ruwase, Shaden Smith, Minjia Zhang, Jeff Rasley, et al. 2022. Deepspeed-inference: enabling efficient inference of transformer models at unprecedented scale. In SC22: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–15. IEEE.
Sangmin Bae, Jongwoo Ko, Hwanjun Song, and Se-Young Yun. 2023. Fast and robust early exiting framework for autoregressive language models with synchronized parallel decoding. ArXiv, abs/2310.05424.
Cenk Baykal, Dylan Cutler, Nishanth Dikkala, Nikhil Ghosh, Rina Panigrahy, and Xin Wang. 2023. Alternating updates for efficient transformers. ArXiv, abs/2301.13310.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
Yew Ken Chia, Pengfei Hong, Lidong Bing, and Soujanya Poria. 2023. Instructeval: Towards holistic evaluation of instruction-tuned large language models.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
Han Dai, Yi Zhang, Ziyu Gong, Nanqing Yang, Wei Dai, Eric Song, and Qiankun Xie. 2021. Spatten: Efficient sparse attention architecture with cascade token and head pruning. In Advances in Neural Information Processing Systems, volume 34.
Erich Elsen, Augustus Odena, Maxwell Nye, Sagnak Ta¸sırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, and Arushi Somani. 2023. Releasing Persimmon-8B.
Trevor Gale, Matei Zaharia, Cliff Young, and Erich Elsen. 2020. Sparse gpu kernels for deep learning.
Mingyu Gao, Jie Yu, Wentai Li, Michael C Dai, Nam Sung Kim, and Krste Asanovic. 2022. computedram: In-memory compute using off-the-shelf dram. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, pages 1065–1079.
Google Gemini Team. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
Alex Graves. 2016. Adaptive computation time for recurrent neural networks. In International Conference on Machine Learning, pages 3500–3509. PMLR.
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee, and Yuanzhi Li. 2023. Textbooks are all you need. CoRR, abs/2306.11644.
Jongmin Ham, Jinha Kim, Jinwoong Choi, Cheolwoo Cho, Seulki Hong, Kyeongsu Han, and Taejoo Chung. 2016. Graphssd: a high performance flash-based storage system for large-scale graph processing. In 2016 USENIX Annual Technical Conference (USENIXATC 16), pages 243–256.
Song Han, Xingyu Liu, Huizi Mao, Jing Pu, Ardavan Pedram, Mark A Horowitz, and William J Dally. 2016a. Eie: efficient inference engine on compressed deep neural network. arXiv preprint arXiv:1602.01528.
Song Han, Huizi Mao, and William J Dally. 2016b. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. In International Conference on Learning Representations (ICLR).
Awni Hannun, Jagrit Digani, Angelos Katharopoulos, and Ronan Collobert. 2023. MLX: Efficient and flexible machine learning on apple silicon.
Zhenyu He, Zexuan Zhong, Tianle Cai, Jason D Lee, and Di He. 2023. Rest: Retrieval-based speculative decoding. ArXiv, abs/2311.08252.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net.
Duc Nien Hoang, Minsik Cho, Thomas Merth, Mohammad Rastegari, and Zhangyang Wang. 2023. (dynamic) prompting might be all you need to repair compressed llms. ArXiv, abs/2310.00867.
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
Ajay Jaiswal, Zhe Gan, Xianzhi Du, Bowen Zhang, Zhangyang Wang, and Yinfei Yang. 2023. Compressing llms: The truth is rarely pure and never simple. ArXiv, abs/2310.01382.
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b. CoRR, abs/2310.06825.
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2022. Fast inference from transformers via speculative decoding.
Liang Li, Qingyuan Li, Bo Zhang, and Xiangxiang Chu. 2023. Norm tweaking: High-performance low-bit quantization of large language models. ArXiv, abs/2309.02784.
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. 2023. Awq: Activation-aware weight quantization for llm compression and acceleration. ArXiv, abs/2306.00978.
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. 2023a. Llm-qat: Data-free quantization aware training for large language models. CoRR.
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. 2023b. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pages 22137–22176. PMLR.
Moinuddin K Meswani, Sergey Blagodurov, David Roberts, John Slice, Mike Ignatowski, and Gabriel Loh. 2015. Neural cache: Bit-serial in-cache acceleration of deep neural networks. In 2015 48th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 383–394. IEEE.
Iman Mirzadeh, Keivan Alizadeh, Sachin Mehta, Carlo C Del Mundo, Oncel Tuzel, Golnoosh Samei, Mohammad Rastegari, and Mehrdad Farajtabar. 2023. Relu strikes back: Exploiting activation sparsity in large language models.
Angshuman Parashar, Minsoo Rhu, Anurag Mukkara, Antonio Puglielli, Rangharajan Venkatesan, Brucek Khailany, Joel Emer, Stephen W Keckler, and William J Dally. 2017. Timeloop: A systematic approach to dnn accelerator evaluation. In 2017 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pages 241–251. IEEE.
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Z. Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 8024–8035.
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. 2021. Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. In SC21: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–14.
Minsoo Rhu, Natalia Gimelshein, Jason Clemons, Arslan Zulfiqar, and Stephen W Keckler. 2013. vdnn: Virtualized deep neural networks for scalable, memory-efficient neural network design. In 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), page Article 13. IEEE Computer Society.
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqiang Li, Kaipeng Zhang, Peng Gao, Yu Jiao Qiao, and Ping Luo. 2023. Omniquant: Omnidirectionally calibrated quantization for large language models. ArXiv, abs/2308.13137.
Yifan Shao, Mengjiao Li, Wenhao Cai, Qi Wang, Dhananjay Narayanan, and Parthasarathy Ranganathan. 2022. Hotpot: Warmed-up gigascale inference with tightly-coupled compute and reuse in flash. In Proceedings of the 55th Annual IEEE/ACM International Symposium on Microarchitecture, pages 335–349.
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. 2023. Flexgen: High-throughput generative inference of large language models with a single GPU. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pages 31094–31116. PMLR.
Chenyang Song, Xu Han, Zhengyan Zhang, Shengding Hu, Xiyu Shi, Kuai Li, Chen Chen, Zhiyuan Liu, Guangli Li, Tao Yang, and Maosong Sun. 2024. Prosparse: Introducing and enhancing intrinsic activation sparsity within large language models.
Vedant Subramani, Marios Savvides, Li Ping, and Sharan Narang. 2022. Adapt: Parameter adaptive token-wise inference for vision transformers. In Proceedings of the 55th Annual IEEE/ACM International Symposium on Microarchitecture.
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. 2023. A simple and effective pruning approach for large language models. ArXiv, abs/2306.11695.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023a. Llama: Open and efficient foundation language models. CoRR, abs/2302.13971.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. 2019. Huggingface’s transformers: State-of-the-art natural language processing. CoRR, abs/1910.03771.
Haojun Xia, Zhen Zheng, Yuchao Li, Donglin Zhuang, Zhongzhu Zhou, Xiafei Qiu, Yong Li, Wei Lin, and Shuaiwen Leon Song. 2023. Flash-llm: Enabling low-cost and highly-efficient large generative model inference with unstructured sparsity. Proc. VLDB Endow., 17:211–224.
Zhaozhuo Xu, Zirui Liu, Beidi Chen, Yuxin Tang, Jue Wang, Kaixiong Zhou, Xia Hu, and Anshumali Shrivastava. 2023. Compress, then prompt: Improving accuracy-efficiency trade-off of llm inference with transferable prompt. ArXiv, abs/2305.11186.
Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, and Mengwei Xu. 2023. Edgemoe: Fast on-device inference of moe-based large language models. ArXiv, abs/2308.14352.
Hengrui Zhang, August Ning, Rohan Prabhakar, and David Wentzlaff. 2023a. A hardware evaluation framework for large language model inference.
Jinchao Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. 2023b. Draft & verify: Lossless large language model acceleration via self-speculative decoding. ArXiv, abs/2309.08168.
Shizhao Zhang, Han Dai, Tian Sheng, Jiawei Zhang, Xiaoyong Li, Qun Xu, Mengjia Dai, Yunsong Xiao, Chao Ma, Rui Tang, et al. 2022a. Llm quantization: Quantization-aware training for large language models. In Advances in Neural Information Processing Systems, volume 35.
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona T. Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022b. OPT: open pre-trained transformer language models. CoRR, abs/2205.01068.
Zhengyan Zhang, Yixin Song, Guanghui Yu, Xu Han, Yankai Lin, Chaojun Xiao, Chenyang Song, Zhiyuan Liu, Zeyu Mi, and Maosong Sun. 2024. Relu wins: Discovering efficient activation functions for sparse llms.
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. 2023. Atom: Low-bit quantization for efficient and accurate llm serving. ArXiv, abs/2310.19102.
A 附录概览
附录结构如下:
- 在附录 B 中,我们提供了第 3 节中介绍的低秩预测器的更多详细信息。我们从准确性(即它们对模型准确性的影响)和效率(即它们预测将被激活的额外神经元)的角度评估了我们训练的预测器。
- 附录 C 提供了我们实验设置和第 4 节中进行的实验实现的更详细描述。
- 在附录 D 中,我们讨论了关于将神经元基于共激活进行捆绑作为增加块大小的潜在方法的负面结果(参见第 3.2 节)。我们特意包含了这个负面结果,因为我们相信它可能会激发未来关于有效神经元捆绑及其在高效推理中利用的研究。
- 在附录 E 中,我们深入研究了文献中相关工作的回顾。
- 在附录 F 中,我们探讨了在转向更小设备时 LLM 在闪存中的影响。
- 最后,附录 G 比较了基础模型生成的文本与我们利用预测器的模型生成的文本。
B 低秩激活预测器:附加结果
B.1 预测器的稀疏性模式
预测为活跃的神经元数量将决定我们算法的效率,预测的激活越不稀疏,需要从闪存加载的权重就越多。我们评估了 C4 验证数据集上 100 个随机样本的稀疏性模式。在图 9 中,我们可以看到 OPT、Persimmon 和 Phi 的稀疏性模式。在 OPT 中,预测器预测的活跃神经元数量是密集推理情况下观察到的实际稀疏性的 3 倍。在 Persimmon 中,它大约相同——是所需神经元的 3 倍,而在 Phi-2 中,它大约是原始模型中被预测器激活的所需神经元的 2 倍。被模型激活但未被预测器激活的神经元是假阴性。预测器和模型中都活跃的神经元与仅在模型中活跃的神经元之间的差距在所有三个模型中都非常窄,因此假阴性仅占预测的一小部分。为了减少假阴性,预测器必须“过度预测”,这导致加载了冗余的神经元,即那些将具有零激活且对结果没有影响的神经元。这项工作的一个有趣的未来方向是提高预测器的准确性,以便能够加载更少的神经元。我们在 OPT 和 Persimmon 中观察到的一个现象是,后面的层有更多的活跃神经元,这可以在图 9d 中看到。
B.2 使用预测器的模型准确性
我们评估了在应用预测器的情况下模型在公共基准测试上的准确性。在表 4 中可以看出,模型的零样本准确性没有下降。此外,我们可以看到,增加 Persimmon 和 Falcon 最后 4 层的预测器大小可以提高零样本指标。我们也评估了 MMLU (Hendrycks et al., 2021) 基准测试上的模型。我们使用了 InstructEval 的实现 (Chia et al., 2023) 来评估 MMLU。在图 10a 中,我们可以看到当最后 4 层使用更高秩的预测器时,Persimmon 的 MMLU 没有下降,但对于较低秩的预测器则不然。Phi2 的 MMLU 会从 relufied 模型下降 2.3 个点,但仍保持在 52,如图 10b 所示。通过增加低秩预测器的阈值,我们可以减少数据加载量,这在表 4 中针对 Persimmon 模型的不同阈值可以看到,零样本指标有轻微的下降。我们对 Persimmon 使用了阈值=0.7。
B.3 预测器的开销
OPT-6.7B 中预测器的平均秩为 240,这将导致少于 2.4% 的非嵌入权重和 FLOPs。在 M1 Max CPU 实验中,这占推理时间的 2.75%,在 RTX GPU 中占 4.8%,这是可以忽略不计的。对于 Falcon 7B,预测器占模型大小和 CPU 计算的 4%。对于 Persimmon,它在 CPU 上占推理时间的 2.85%。对于 Llama 2 7B,它在 CPU 上占推理时间的 3.92%。
C 扩展结果
实验设置:我们的实验旨在优化个人设备上的推理效率。为此,我们单独处理序列,一次只运行一个序列。这种方法允许我们为 Key-Value (KV) 缓存分配 DRAM 的特定部分,同时主要关注模型大小。此策略在处理一次一个序列/查询时特别有效。
对于我们推理过程的实现,我们利用 HuggingFace Transformers 和 KV 缓存。此设置在 DRAM 中大约有模型大小的一半可用的条件下进行测试。我们选择此数量作为在闪存中托管 LLM 的想法的展示。通过不同水平的稀疏性或采用量化,可以在更小的可用 DRAM 容量下工作,或者可选地使用更大的模型。这种配置证明了以更低的内存占用执行推理的实用性。
系统性能优化:我们实验的主要目标是 Apple macOS 14.3 操作系统。对于高性能推理,大多数现有的深度学习框架要求权重和中间结果的形状在计算中保持静态。特别是,PyTorch 的 Metal Performance Shaders (MPS) 后端在计算图中存在任何形状动态时表现出相当陡峭的性能悬崖。为了构建高性能实现,我们选择从 Apple 的开源 MLX 深度学习框架 (Hannun et al., 2023) 中借用自定义的、对动态友好的 Metal 内核。此外,我们利用了 Apple 系统上可用的统一内存架构,我们通过创建使用 MTLStorageModeShared 分配模式的张量,利用 GPU 分配器来维护权重缓存。此模式允许 CPU 和 GPU 直接访问相同的内存缓冲区,而无需冗余副本。我们观察到前馈网络的输入和输出具有静态形状,因此通过将动态隐藏在二进制扩展中并在内部处理形状动态和内存管理,我们能够实现 PyTorch MPS 后端本身无法实现的性能水平,同时保持模型的其余部分不变。
从闪存加载数据的缓存考量。当从闪存读取数据时,操作系统通常会在块缓存中缓存块,以预期未来的重用。然而,这种缓存机制消耗了 DRAM 中超出为模型分配的内存之外的额外内存。为了准确评估在有限 DRAM 条件下闪存的实际吞吐量,基准测试应在不依赖缓存的情况下进行。实际系统可能会或可能不会依赖文件系统缓存,具体取决于要求。
为了在本研究中进行硬件基准测试,我们故意并显著地降低了我们的 NVMe 吞吐量测量值。在 macOS 和 iOS 上,我们使用 fcntl() 函数的 F_NOCACHE 标志,而在 Linux 上,我们使用 DirectIO。此外,在 macOS 上,我们在启动基准测试之前使用 purge 命令清除任何驻留缓冲区。这种方法在不允许缓存的场景中提供了吞吐量的保守下限,并使基准测试可重复。值得注意的是,如果允许推理代码或操作系统缓存部分权重,这些数字可以得到改善。
虽然 OS 级缓冲区缓存对于具有高缓存命中率的通用应用程序是有利的,但它缺乏对每个进程或应用程序级缓冲区驱逐的细粒度控制。在设备端内存约束和大模型大小的背景下,这可能导致文件系统级缓存无济于事的情况,因为为了评估后面的层,前面的层必须以滚动模式被驱逐,因此有效的缓存命中率接近于零。除了效率低下之外,由于内存分配压力和转换后备缓冲区 (TLB) 抖动,这还可能导致与其他进程的共存问题。
C.1 OPT 6.7B 模型的结果
本节介绍了 OPT 6.7B 模型的结果,特别是在 DRAM 中为模型分配的内存大约是其基线需求的一半的条件下。
预测器。对于 OPT 6.7B 模型的前 28 层,我们训练秩为 的预测器。为了减少假阴性的发生,最后四层采用了秩为 的更高秩预测器。这些预测器在 OPT 6.7B 模型中实现了平均 5% 的假阴性和 7% 的假阳性。如图 3a 所示,我们的预测器准确地识别了大多数活跃神经元,同时偶尔错误地识别了值接近零的非活跃神经元。值得注意的是,这些假阴性由于接近零,在被排除时不会显著改变最终输出。此外,如表 1 所示,这种预测准确性水平不会对模型在 0-shot 任务中的性能产生不利影响。
OPT 6.7B 模型中的窗口化。在 OPT 6.7B 模型中利用 的窗口化方法显著减少了对新鲜数据加载的需求。使用预测器的活跃神经元平均需要约 10% 的 DRAM 内存容量;然而,使用我们的方法,它下降到 2.4%。此过程涉及为过去 5 个 token 的窗口保留 DRAM 内存,这反过来增加了 Feed Forward Network (FFN) 的 DRAM 需求至 24%。
模型在 DRAM 中保留的总内存包含几个组件:嵌入、注意力模型、预测器和已加载的前馈层。预测器占模型大小的 1.25%,而嵌入占 3%。注意力模型的权重占 32.3%,FFN 占用 15.5%(计算为 )。将这些加起来,总 DRAM 内存使用量占模型大小的 52.1%。
延迟分析:使用大小为 4 的窗口,每个 token 需要访问 2.4% 的 Feed Forward Network (FFN) 神经元。对于 32 位模型,每次读取的数据块大小为 字节 = 32 KiB,因为它涉及串联的行和列。在 M1 Max 上,这导致从闪存加载的平均延迟为每个 token 105ms,内存管理(涉及神经元删除和添加)为 57ms。因此,总的内存相关延迟小于每个 token 162ms(参考图 1)。相比之下,基线方法以 6.1GB/s 的速度加载 13.4GB 数据,导致每个 token 的延迟约为 2196ms。因此,我们的方法代表了对基线的实质性改进。
对于 GPU 机器上的 16 位模型,闪存加载时间减少到 30.5ms,内存管理需要 35ms,由于从 CPU 到 GPU 传输数据的额外开销,略高一些。尽管如此,基线方法的 I/O 时间仍然保持在 2000 毫秒以上。
每种方法如何影响性能的详细比较在表 2 中提供。
C.2 Falcon 7B 模型的结果
为了验证我们的发现不仅限于 OPT 模型,我们还将 LLM in flash 的想法应用于 Falcon 模型 (Almazrouei et al., 2023)。由于原始 Falcon 模型不是稀疏的,我们使用了性能与基础版本几乎相同的稀疏化(relufied)版本 (Mirzadeh et al., 2023)。与上一节类似,我们展示了在 DRAM 中大约有一半模型大小可用的条件下获得的结果。
预测器。在 Falcon 7B 模型中,秩为 的预测器用于前 28 层,秩为 的预测器用于最后四层。
窗口配置。我们的模型为包含最后 4 个 token 的窗口保留内存。此设置利用了 33% 的 Feed Forward Net-
对于上下文长度为 2048 的 OPT 6.7B 模型,KV 缓存需要 个元素,这仅占模型大小的 8%。此外,KV 缓存本身也可以保存在闪存中。