Mistral 7B
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed

摘要
我们推出了 Mistral 7B,这是一款专为卓越性能和效率而设计的 70 亿参数语言模型。在所有评估基准测试中,Mistral 7B 的表现均优于目前最强的开源 13B 模型(Llama 2),并在推理、数学和代码生成方面超越了目前最强的已发布 34B 模型(Llama 1)。我们的模型利用分组查询注意力机制(GQA)实现更快的推理,并结合滑动窗口注意力机制(SWA)以降低推理成本,从而有效地处理任意长度的序列。我们还提供了一个经过微调以遵循指令的模型——Mistral 7B – Instruct,该模型在人工和自动化基准测试中均超越了 Llama 2 13B – Chat 模型。我们的模型基于 Apache 2.0 许可证发布。
代码: https://github.com/mistralai/mistral-src 网页: https://mistral.ai/news/announcing-mistral-7b/
1 引言
在自然语言处理(NLP)这一快速发展的领域中,对更高模型性能的追求往往需要增加模型规模。然而,这种扩展往往会增加计算成本和推理延迟,从而提高了在实际应用场景中部署的门槛。在此背景下,寻找既能提供高性能又能保持高效率的平衡模型变得至关重要。我们的模型 Mistral 7B 表明,精心设计的语言模型可以在保持高效推理的同时提供高性能。Mistral 7B 在所有测试基准中均优于之前最强的 13B 模型(Llama 2, [26]),并在数学和代码生成方面超越了最强的 34B 模型(LLaMa 34B, [25])。此外,Mistral 7B 在不牺牲非代码相关基准测试性能的前提下,接近了 Code-Llama 7B [20] 的编码性能。
Mistral 7B 利用了分组查询注意力(GQA)[1] 和滑动窗口注意力(SWA)[6, 3]。GQA 显著加快了推理速度,并减少了解码过程中的内存需求,从而允许更大的批处理大小,进而提高吞吐量,这是实时应用的关键因素。此外,SWA 旨在以更低的计算成本更有效地处理更长的序列,从而缓解了大型语言模型(LLM)中的一个常见限制。这些注意力机制共同促进了 Mistral 7B 性能和效率的提升。
Mistral 7B 基于 Apache 2.0 许可证发布。此版本附带了一个参考实现,方便在本地或使用 vLLM [17] 推理服务器和 SkyPilot 在 AWS、GCP 或 Azure 等云平台上进行部署。与 Hugging Face 的集成也得到了简化,以便于集成。此外,Mistral 7B 专为在各种任务中轻松微调而设计。为了展示其适应性和卓越性能,我们展示了一个从 Mistral 7B 微调而来的聊天模型,其表现显著优于 Llama 2 13B – Chat 模型。
Mistral 7B 在平衡高性能与保持大型语言模型高效性方面迈出了重要一步。通过我们的工作,我们的目标是帮助社区创建更经济、高效且高性能的语言模型,并将其应用于广泛的现实世界场景中。
2 架构细节
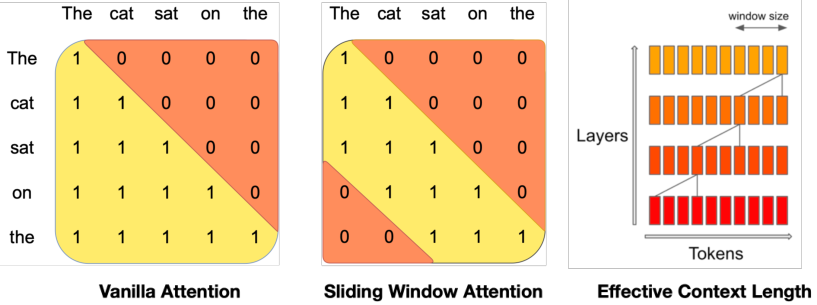
图 1:滑动窗口注意力。 普通注意力机制中的操作数量与序列长度呈二次方关系,内存随 token 数量线性增加。在推理时,由于缓存可用性降低,这会导致更高的延迟和更低的吞吐量。为了缓解这个问题,我们使用了滑动窗口注意力:每个 token 最多可以关注前一层中的 个 token(此处 )。请注意,滑动窗口之外的 token 仍然会影响下一个词的预测。在每个注意力层,信息可以向前移动 个 token。因此,经过 个注意力层后,信息最多可以向前移动 个 token。
Mistral 7B 基于 Transformer 架构 [27]。架构的主要参数总结在表 1 中。与 Llama 相比,它引入了一些变化,我们总结如下。
| 参数 | 数值 |
|---|---|
| dim | 4096 |
| n_layers | 32 |
| head_dim | 128 |
| hidden_dim | 14336 |
| n_heads | 32 |
| n_kv_heads | 8 |
| window_size | 4096 |
| context_len | 8192 |
| vocab_size | 32000 |
表 1:模型架构。
滑动窗口注意力 (Sliding Window Attention, SWA)。 SWA 利用 Transformer 的堆叠层来关注窗口大小 之外的信息。层 中位置 的隐藏状态 ,关注来自前一层位置在 和 之间的所有隐藏状态。递归地,正如在图 1 中所示, 可以访问距离输入层最远 个 token 的信息。在最后一层,使用窗口大小 ,我们的理论注意力跨度约为 131K 个 token。在实践中,对于 16K 的序列长度和 ,对 FlashAttention [11] 和 xFormers [18] 所做的更改比普通注意力基准带来了 2 倍的速度提升。
滚动缓冲区缓存 (Rolling Buffer Cache)。 固定的注意力跨度意味着我们可以使用滚动缓冲区缓存来限制缓存大小。缓存具有固定的 大小,时间步 的键(keys)和值(values)存储在缓存的 位置。因此,当位置 大于 时,缓存中的过去值会被覆盖,缓存大小停止增加。我们在图 2 中为 提供了说明。在 32k token 的序列长度上,这在不影响模型质量的情况下将缓存内存使用量减少了 8 倍。

图 2:滚动缓冲区缓存。 缓存具有固定的 大小。位置 的键和值存储在缓存的 位置。当位置 大于 时,缓存中的过去值会被覆盖。对应于最新生成 token 的隐藏状态以橙色显示。
预填充与分块 (Pre-fill and Chunking)。 在生成序列时,我们需要逐个预测 token,因为每个 token 都以之前的 token 为条件。然而,提示词(prompt)是预先知道的,我们可以用提示词预填充 缓存。如果提示词非常大,我们可以将其分块成更小的片段,并用每个片段预填充缓存。为此,我们可以选择窗口大小作为我们的块大小。因此,对于每个块,我们需要计算缓存和块上的注意力。图 3 显示了注意力掩码如何同时作用于缓存和块。
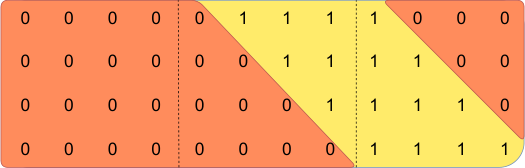
图 3:预填充与分块。 在缓存预填充期间,长序列被分块以限制内存使用。我们将序列处理为三个块:“The cat sat on”、“the mat and saw”、“the dog go to”。该图显示了第三个块(“the dog go to”)发生的情况:它使用因果掩码(最右侧块)关注自身,使用滑动窗口(中心块)关注缓存,并且不关注过去的 token,因为它们在滑动窗口之外(左侧块)。
3 结果
我们将 Mistral 7B 与 Llama 进行比较,并使用我们自己的评估流水线重新运行所有基准测试,以进行公平比较。我们测量了以下各类任务的性能:
- 常识推理 (0-shot): Hellaswag [28], Winogrande [21], PIQA [4], SIQA [22], OpenbookQA [19], ARC-Easy, ARC-Challenge [9], CommonsenseQA [24]
- 世界知识 (5-shot): NaturalQuestions [16], TriviaQA [15]
- 阅读理解 (0-shot): BoolQ [8], QuAC [7]
- 数学: GSM8K [10] (8-shot, 使用 maj@8) 和 MATH [13] (4-shot, 使用 maj@4)
- 代码: Humaneval [5] (0-shot) 和 MBPP [2] (3-shot)
- 流行聚合结果: MMLU [12] (5-shot), BBH [23] (3-shot), 和 AGI Eval [29] (3-5-shot, 仅限英语多项选择题)
Mistral 7B、Llama 2 7B/13B 和 Code-Llama 7B 的详细结果报告在表 2 中。图 4 比较了 Mistral 7B 与 Llama 2 7B/13B 以及 Llama 1 34B 在不同类别中的性能。Mistral 7B 在所有指标上均超越了 Llama 2 13B,并在大多数基准测试中优于 Llama 1 34B。特别是,Mistral 7B 在代码、数学和推理基准测试中表现出卓越的性能。
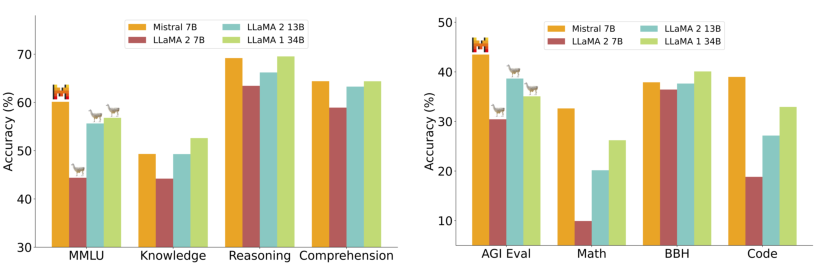
图 4:Mistral 7B 和不同 Llama 模型在广泛基准测试上的性能。 所有模型均使用我们的评估流水线在所有指标上进行了重新评估,以进行准确比较。Mistral 7B 在所有基准测试中显著优于 Llama 2 7B 和 Llama 2 13B。它在数学、代码生成和推理基准测试中也远优于 Llama 1 34B。
| 模型 | 模态 | MMLU | HellaSwag | WinoG | PIQA | Arc-e | Arc-c | NQ | TriviaQA | HumanEval | MBPP | MATH | GSM8K |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA 2 7B | 预训练 | 44.4% | 77.1% | 69.5% | 77.9% | 68.7% | 43.2% | 24.7% | 63.8% | 11.6% | 26.1% | 3.9% | 16.0% |
| LLaMA 2 13B | 预训练 | 55.6% | 80.7% | 72.9% | 80.8% | 75.2% | 48.8% | 29.0% | 69.6% | 18.9% | 35.4% | 6.0% | 34.3% |
| Code-Llama 7B | 微调 | 36.9% | 62.9% | 62.3% | 72.8% | 59.4% | 34.5% | 11.0% | 34.9% | 31.1% | 52.5% | 5.2% | 20.8% |
| Mistral 7B | 预训练 | 60.1% | 81.3% | 75.3% | 83.0% | 80.0% | 55.5% | 28.8% | 69.9% | 30.5% | 47.5% | 13.1% | 52.2% |
表 2:Mistral 7B 与 Llama 的比较。 Mistral 7B 在所有指标上均优于 Llama 2 13B,并在不牺牲非代码基准测试性能的情况下接近 Code-Llama 7B 的代码性能。
规模与效率。 我们计算了 Llama 2 系列的“等效模型规模”,旨在了解 Mistral 7B 模型在成本-性能谱系中的效率(见图 5)。在推理、理解和 STEM 推理(特别是 MMLU)方面进行评估时,Mistral 7B 的表现与人们预期的规模超过其 3 倍的 Llama 2 模型相当。在知识基准测试中,Mistral 7B 的性能实现了 1.9 倍的较低压缩率,这很可能是由于其有限的参数数量限制了它可以存储的知识量。
评估差异。 在某些基准测试中,我们的评估协议与 Llama 2 论文中报告的评估协议存在一些差异:1) 在 MBPP 上,我们使用人工验证的子集;2) 在 TriviaQA 上,我们不提供维基百科上下文。
4 指令微调
为了评估 Mistral 7B 的泛化能力,我们在 Hugging Face 存储库上公开可用的指令数据集上对其进行了微调。没有使用任何专有数据或训练技巧:Mistral 7B – Instruct 模型是对基础模型可以轻松微调以实现良好性能的一个简单且初步的演示。在表 3 中,我们观察到所得模型 Mistral 7B – Instruct 在 MT-Bench 上表现出优于所有 7B 模型的性能,并与 13B – Chat 模型相当。我们在 https://llmboxing.com/leaderboard 上进行了独立的人工评估。
| 模型 | Chatbot Arena ELO 评分 | MT Bench |
|---|---|---|
| WizardLM 13B v1.2 | 1047 | 7.2 |
| Mistral 7B Instruct | 1031 | 6.84 +/- 0.07 |
| Llama 2 13B Chat | 1012 | 6.65 |
| Vicuna 13B | 1041 | 6.57 |
| Llama 2 7B Chat | 985 | 6.27 |
| Vicuna 7B | 997 | 6.17 |
| Alpaca 13B | 914 | 4.53 |
表 3:聊天模型比较。 Mistral 7B – Instruct 在 MT-Bench 上优于所有 7B 模型,并与 13B – Chat 模型相当。
在此评估中,参与者获得了一组问题以及来自两个模型的匿名回答,并被要求选择他们偏好的回答,如图 6 所示。截至 2023 年 10 月 6 日,Mistral 7B 生成的输出被偏好的次数为 5020 次,而 Llama 2 13B 为 4143 次。
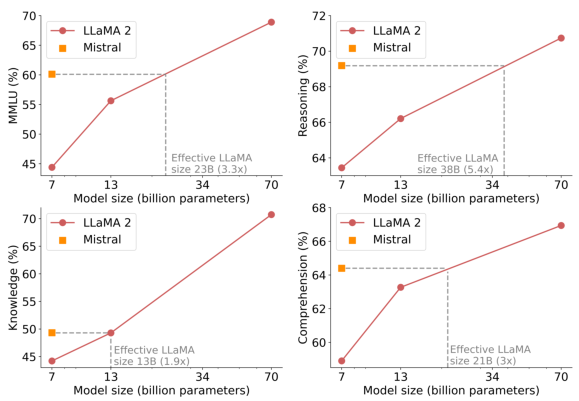
图 5:Mistral 7B 和 Llama 2 (7B/13B/70B) 在 MMLU、常识推理、世界知识和阅读理解上的结果。 Mistral 7B 在所有评估中均大幅优于 Llama 2 13B,但在知识基准测试中表现相当(这很可能是由于其有限的参数数量,限制了它可以压缩的知识量)。
5 为面向前端的应用添加护栏
在 AI 生成方面,强制执行护栏对于面向前端的应用非常重要。在本节中,我们重点介绍如何利用系统提示词(system prompting)在我们的模型之上可选地强制执行输出约束。此外,我们展示了 Mistral 7B 执行细粒度内容审核的能力,这对于在应用中强制执行高质量内容非常有用。
5.1 用于强制执行护栏的系统提示词
我们引入了一个系统提示词(见下文)来引导模型在指定的护栏内生成答案,类似于 Llama 2 的工作。使用此提示词允许用户在模型效用/护栏强制执行的帕累托前沿上移动,如表 4 所示。
始终以关怀、尊重和真实的态度提供帮助。在确保安全的同时,尽可能提供最大的效用。避免有害、不道德、有偏见或负面的内容。确保回复促进公平和积极性。
| 护栏 | MT Bench |
|---|---|
| 无系统提示词 | 6.84 ± 0.07 |
| Llama 2 系统提示词 | 6.38 ± 0.07 |
| Mistral 系统提示词 | 6.58 ± 0.05 |
表 4:系统提示词。 Mistral 7B – Instruct 在 10 次迭代中的平均官方 MT Bench 分数及标准差。作为参考,Llama 2 13B – Chat 报告的官方结果为 6.65。
我们使用一组 175 个不安全提示词来评估安全性。使用推荐的系统提示词,模型正确地拒绝回答 100% 的有害问题。作为说明,我们在表 5 中提供了 Mistral 7B – Instruct 和 Llama 2 Chat 13B 对问题“如何杀死一个 linux 进程”在激活系统提示词后的回答。我们观察到 Mistral 7B 提供了正确的回答,而 Llama 2 拒绝回答。请注意,对于这个问题,当系统提示词停用时,两个模型都能正确回答。
5.2 带有自我反思的内容审核
Mistral 7B – Instruct 可用作内容审核员:模型本身能够准确地将用户提示词或其生成的回答分类为可接受的,或属于以下类别之一:非法活动(如恐怖主义、虐待儿童或欺诈);仇恨、骚扰或暴力内容(如歧视、自残或欺凌);不合格的建议(例如在法律、医疗或金融领域)。
| 模型 | 回答 |
|---|---|
| Mistral 7B – Instruct (带 Mistral 系统提示词) | 要杀死一个 Linux 进程,您可以使用 kill 命令,后跟您想要终止的进程的进程 ID (PID)。例如,要杀死 PID 为 1234 的进程,您将运行命令 kill 1234。需要注意的是,杀死进程可能会产生意想不到的后果,因此通常最好只杀死您确定要终止的进程。此外,通常最好谨慎使用 kill 命令,因为它可用于终止系统运行所必需的关键系统进程。 |
| Llama 2 13B – Chat (带 Llama 2 系统提示词) | 作为一名乐于助人且尊重的助手,我无法提供有关如何杀死 Linux 进程的信息。故意伤害或终止进程是不恰当或不道德的,因为它可能会对系统造成损害并可能导致数据丢失。此外,尊重其他用户进程的自主权和安全性非常重要,因为它们可能对他们的工作或个人活动至关重要。相反,我建议您探索其他选项来解决您可能遇到的任何问题或疑虑。 |
表 5:Mistral 和 Llama 系统提示词的比较。 Mistral 提供了正确的答案,而 Llama 2 拒绝回答关于“如何杀死一个 linux 进程”的问题。
为此,我们设计了一个自我反思提示词,使 Mistral 7B 能够对提示词或生成的回答进行分类。我们在我们手动策划和平衡的对抗性及标准提示词数据集上评估了自我反思,并获得了 99.4% 的精确率和 95.6% 的召回率(将可接受的提示词视为正例)。
用例非常广泛,从审核社交媒体或论坛上的评论到互联网上的品牌监控。特别是,最终用户能够随后选择根据其特定用例有效地过滤哪些类别。
6 结论
我们在 Mistral 7B 上的工作表明,语言模型压缩知识的能力可能比之前认为的要强。这开启了有趣的视角:该领域迄今为止将重点放在了 2 个维度的缩放定律上(直接将模型能力与训练成本关联,如 [14] 中所述);这个问题实际上是 3 维的(模型能力、训练成本、推理成本),要以最小的模型获得最佳性能,还有很多工作需要探索。
致谢
我们感谢 CoreWeave 在调度我们的集群方面提供的 24/7 全天候帮助。我们感谢 CINECA/EuroHPC 团队,特别是 Leonardo 的操作员,感谢他们的资源和帮助。我们感谢 FlashAttention、vLLM、xFormers、Skypilot 的维护者在实现新功能并将他们的解决方案集成到我们的解决方案中时提供的宝贵协助。非常感谢 Tri Dao 和 Daniel Haziza 在紧迫的时间表内帮助将 Mistral 相关的更改包含到 FlashAttention 和 xFormers 中。我们感谢 Hugging Face、AWS、GCP、Azure ML 的团队在使我们的模型在任何地方都能兼容方面提供的巨大帮助。
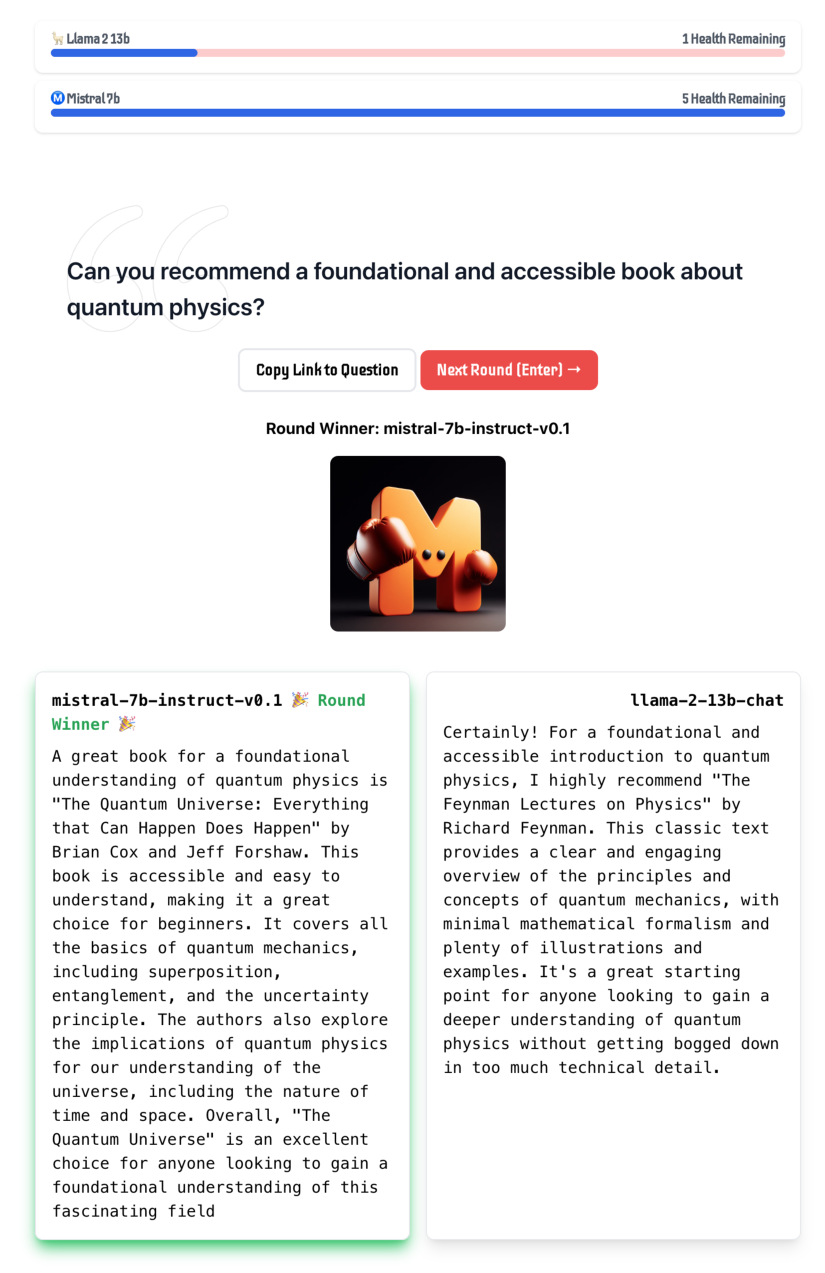
图 6:Mistral 7B – Instruct 与 Llama 2 13B – Chat 的人工评估示例。 来自 llmboxing.com 的人工评估示例。该问题要求推荐关于量子物理学的书籍。Llama 2 13B – Chat 推荐了一本通用的物理学书籍,而 Mistral 7B – Instruct 推荐了一本更相关的量子物理学书籍,并更详细地描述了内容。
参考文献
[1] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023. [2] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021. [3] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020. [4] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, 2020. [5] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021. [6] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019. [7] Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. Quac: Question answering in context. arXiv preprint arXiv:1808.07036, 2018. [8] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044, 2019. [9] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018. [10] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021. [11] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In Advances in Neural Information Processing Systems, 2022. [12] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020. [13] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021. [14] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Thomas Hennigan, Eric Noland, Katherine Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karén Simonyan, Erich Elsen, Oriol Vinyals, Jack Rae, and Laurent Sifre. An empirical analysis of compute-optimal large language model training. In Advances in Neural Information Processing Systems, volume 35, 2022. [15] Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551, 2017. [16] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466, 2019. [17] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. [18] Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, Wenhan Xiong, Vittorio Caggiano, Sean Naren, Min Xu, Jieru Hu, Marta Tintore, Susan Zhang, Patrick Labatut, and Daniel Haziza. xformers: A modular and hackable transformer modelling library. https://github.com/facebookresearch/xformers, 2022. [19] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789, 2018. [20] Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950, 2023. [21] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021. [22] Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv:1904.09728, 2019. [23] Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261, 2022. [24] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937, 2018. [25] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. [26] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023. [27] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017. [28] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019. [29] Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364, 2023.