FlashAttention-2:具有更好并行性和工作划分的更快注意力机制
Tri Dao 普林斯顿大学计算机科学系 斯坦福大学计算机科学系 trid@cs.stanford.edu
2023年7月18日
摘要
在过去几年中,将 Transformer 扩展到更长的序列长度一直是一个主要问题,这有望改善语言建模和高分辨率图像理解的性能,并开启代码、音频和视频生成方面的新应用。注意力层是扩展到更长序列的主要瓶颈,因为其运行时间和内存需求随序列长度呈二次方增长。FlashAttention [5] 利用非对称 GPU 内存层次结构,在不进行任何近似的情况下,带来了显著的内存节省(线性而非二次方)和运行时间加速(与优化后的基线相比为 2-4 倍)。然而,FlashAttention 的速度仍然远未达到优化后的矩阵乘法 (GEMM) 操作的水平,仅达到理论最大 FLOPs/s 的 25-40%。我们观察到这种低效是由于 GPU 上不同线程块和线程束(warp)之间的工作划分不理想,导致占用率低或存在不必要的共享内存读/写。我们提出了 FlashAttention-2,通过更好的工作划分来解决这些问题。具体而言,我们 (1) 调整了算法以减少非矩阵乘法(non-matmul)的 FLOPs;(2) 即使对于单个注意力头,也在不同的线程块之间并行化注意力计算,以提高占用率;(3) 在每个线程块内,在线程束之间分配工作,以减少通过共享内存的通信。这些改进与 FlashAttention 相比带来了约 2 倍的加速,在 A100 上达到了理论最大 FLOPs/s 的 50-73%,并接近了 GEMM 操作的效率。我们通过实验验证,当端到端用于训练 GPT 风格的模型时,FlashAttention-2 在每块 A100 GPU 上达到了高达 225 TFLOPs/s 的训练速度(72% 的模型 FLOPs 利用率)。
1 引言
扩展 Transformer [18] 的上下文长度是一个挑战,因为其核心的注意力层具有随输入序列长度呈二次方增长的运行时间和内存需求。理想情况下,我们希望超越标准的 2k 序列长度限制,以训练能够理解书籍、高分辨率图像和长篇视频的模型。仅在过去一年中,就已经出现了几款上下文长度远超以往的语言模型:上下文长度为 32k 的 GPT-4 [12]、上下文长度为 65k 的 MosaicML 的 MPT,以及上下文长度为 100k 的 Anthropic 的 Claude。长文档查询和故事写作等新兴用例证明了对具有如此长上下文模型的需求。
为了减少在如此长上下文上注意力机制的计算需求,已经提出了许多近似注意力的方法 [2, 3, 4, 8, 9, 14, 19, 20]。尽管这些方法已经看到了一些用例,但据我们所知,大多数大规模训练运行仍然使用标准注意力。受此启发,Dao 等人 [5] 提出重新排序注意力计算,并利用经典技术(分块、重计算)来显著加速它,并将内存使用从序列长度的二次方减少到线性。这比优化后的基线实现了 2-4 倍的挂钟时间加速,以及高达 10-20 倍的内存节省,且没有近似,因此 FlashAttention 在 Transformer 的大规模训练和推理中得到了广泛采用。
然而,随着上下文长度的进一步增加,FlashAttention 的效率仍然远未达到矩阵乘法 (GEMM) 等其他原语的水平。特别是,虽然 FlashAttention 已经比标准注意力实现快 2-4 倍,但前向传播仅达到设备理论最大 FLOPs/s 的 30-50%(图 5),而反向传播更具挑战性,在 A100 GPU 上仅达到最大吞吐量的 25-35%(图 6)。相比之下,优化后的 GEMM 可以达到理论最大设备吞吐量的 80-90%。通过仔细的性能分析,我们观察到 FlashAttention 在 GPU 上不同线程块和线程束之间的工作划分仍然不理想,导致占用率低或存在不必要的共享内存读/写。
基于 FlashAttention,我们提出了具有更好并行性和工作划分的 FlashAttention-2,以应对这些挑战。
- 在第 3.1 节中,我们调整了算法以减少非矩阵乘法 FLOPs 的数量,同时不改变输出。虽然非矩阵乘法 FLOPs 仅占总 FLOPs 的一小部分,但由于 GPU 具有专门用于矩阵乘法的单元,执行它们需要更长的时间,因此矩阵乘法的吞吐量可以比非矩阵乘法吞吐量高出 16 倍。因此,减少非矩阵乘法 FLOPs 并尽可能多地花费时间进行矩阵乘法 FLOPs 是很重要的。
- 我们建议在批次和注意力头数量维度之外,沿着序列长度维度并行化前向和反向传播。这在序列很长(因此批次大小通常很小)的情况下增加了占用率(GPU 资源的利用率)。
- 即使在单个注意力计算块内,我们也在线程块的不同线程束之间划分工作,以减少通信和共享内存的读/写。
在第 4 节中,我们通过实验验证了 FlashAttention-2 与 FlashAttention 相比也产生了显著的加速。在不同设置(有或无因果掩码、不同头维度)下的基准测试表明,FlashAttention-2 比 FlashAttention 实现了约 2 倍的加速,在前向传播中达到了理论最大吞吐量的 73%,在反向传播中达到了理论最大吞吐量的 63%。当端到端用于训练 GPT 风格的模型时,我们达到了每块 A100 GPU 高达 225 TFLOPs/s 的训练速度。
2 背景
我们提供了一些关于 GPU 性能特征和执行模型的背景知识。我们还描述了注意力的标准实现以及 FlashAttention。
2.1 硬件特征
GPU 性能特征。GPU 由计算单元(例如,浮点算术单元)和内存层次结构组成。大多数现代 GPU 包含专门用于加速低精度矩阵乘法的单元(例如,Nvidia GPU 上的 Tensor Cores 用于 FP16/BF16 矩阵乘法)。内存层次结构包括高带宽内存 (HBM) 和片上 SRAM(又称共享内存)。例如,A100 GPU 拥有 40-80GB 的高带宽内存 (HBM),带宽为 1.5-2.0TB/s,以及 108 个流式多处理器,每个处理器拥有 192KB 的片上 SRAM,带宽估计约为 19TB/s [6, 7]。由于 L2 缓存不能直接由程序员控制,为了本次讨论,我们重点关注 HBM 和 SRAM。
执行模型。GPU 拥有大量的线程来执行操作(称为内核)。线程被组织成线程块,这些线程块被调度在流式多处理器 (SM) 上运行。在每个线程块内,线程被分组为线程束(一组 32 个线程)。线程束内的线程可以通过快速洗牌(shuffle)指令进行通信,或协作执行矩阵乘法。线程块内的线程束可以通过从共享内存读取/写入来进行通信。每个内核将输入从 HBM 加载到寄存器和 SRAM,进行计算,然后将输出写回 HBM。
2.2 标准注意力实现
给定输入序列 ,其中 是序列长度, 是头维度,我们想要计算注意力输出 :
其中 是按行应用的。 对于多头注意力 (MHA),同样的计算在多个头之间并行执行,并在批次维度(批次中的输入序列数量)上并行执行。
注意力的反向传播过程如下。令 为 对某个损失函数的梯度。根据链式法则(即反向传播):
其中 是按行应用的 softmax 的梯度(反向传播)。可以推导出,如果 对于某个向量 和 ,那么对于输出梯度 ,输入梯度 。
标准注意力实现将矩阵 和 具体化到 HBM,这需要 的内存。通常 (通常 在 1k–8k 数量级, 在 64–128 左右)。标准注意力实现 (1) 调用矩阵乘法 (GEMM) 子程序来计算 ,将结果写入 HBM,然后 (2) 从 HBM 加载 以计算 softmax 并将结果 写入 HBM,最后 (3) 调用 GEMM 得到 。由于大多数操作受内存带宽限制,大量的内存访问导致挂钟时间缓慢。此外,由于必须具体化 和 ,所需的内存为 。而且,必须保存 以便反向传播计算梯度。
2.3 FlashAttention
为了加速 GPU 等硬件加速器上的注意力机制,[5] 提出了一种算法,在保持相同输出(无近似)的同时减少内存读/写。
2.3.1 前向传播
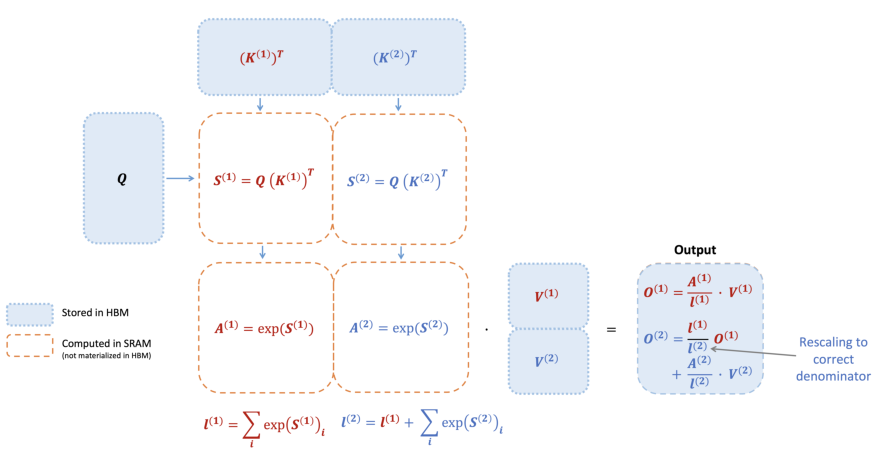
FlashAttention 应用了分块(tiling)的经典技术来减少内存 IO,通过 (1) 将输入块从 HBM 加载到 SRAM,(2) 计算相对于该块的注意力,然后 (3) 更新输出,而不将大的中间矩阵 和 写入 HBM。由于 softmax 耦合了整行或行块,在线 softmax [11, 13] 可以将注意力计算拆分为块,并重新缩放每个块的输出,最终得到正确的结果(无近似)。通过显著减少内存读/写量,FlashAttention 比优化后的基线注意力实现带来了 2-4 倍的挂钟时间加速。
我们描述在线 softmax 技术 [11] 以及它如何在注意力机制中使用 [13]。为简单起见,仅考虑注意力矩阵 的一个行块,形式为:
对于某些矩阵 ,其中 和 是行和列块大小。我们想要计算该行块的 softmax 并与值相乘,形式为:
对于某些矩阵 。标准 softmax 将计算:
在线 softmax 而是计算相对于每个块的“局部”softmax,并在最后重新缩放以获得正确的输出:
我们展示了 FlashAttention 如何使用在线 softmax 来实现分块(图 1)以减少内存读/写。
2.3.2 反向传播
在反向传播中,通过在输入 的块已经加载到 SRAM 后重新计算注意力矩阵 和 的值,FlashAttention 避免了存储大的中间值。通过不需要保存大小为 的大矩阵 和 ,FlashAttention 根据序列长度带来了 10-20 倍的内存节省(所需的内存随序列长度 线性增长,而不是二次方)。反向传播也由于减少了内存读/写而实现了 2-4 倍的挂钟时间加速。
反向传播将分块应用于第 2.2 节中的方程。虽然反向传播在概念上比前向传播更简单(没有 softmax 重新缩放),但实现要复杂得多。这是因为在反向传播中需要将更多的值保留在 SRAM 中以执行 5 次矩阵乘法,而前向传播中仅有 2 次矩阵乘法。
3 FlashAttention-2:算法、并行性和工作划分
我们描述 FlashAttention-2 算法,它包括对 FlashAttention 的一些调整,以减少非矩阵乘法 FLOPs 的数量。然后,我们描述如何并行化不同线程块上的计算,以充分利用 GPU 资源。最后,我们描述如何在单个线程块内划分工作,以减少共享内存访问量。这些改进导致了 2-3 倍的加速,如第 4 节所验证。
3.1 算法
我们调整了 FlashAttention 的算法以减少非矩阵乘法 FLOPs 的数量。这是因为现代 GPU 具有专门的计算单元(例如,Nvidia GPU 上的 Tensor Cores),使得矩阵乘法快得多。例如,A100 GPU 的 FP16/BF16 矩阵乘法理论最大吞吐量为 312 TFLOPs/s,但非矩阵乘法 FP32 仅为 19.5 TFLOPs/s。另一种思考方式是,每个非矩阵乘法 FLOP 比矩阵乘法 FLOP 昂贵 16 倍。为了保持高吞吐量(例如,超过最大理论 TFLOPs/s 的 50%),我们希望尽可能多地花费时间在矩阵乘法 FLOPs 上。
3.1.1 前向传播
我们重新审视第 2.3 节中展示的在线 softmax 技巧,并做出两个微小的调整以减少非矩阵乘法 FLOPs:
- 我们不必通过 重新缩放输出更新的两个项:
我们可以改为维护一个“未缩放”版本的 并保留统计量 :
只有在循环的最后,我们才将最终的 乘以 以获得正确的输出。
- 我们不必为反向传播保存最大值 和指数和 。我们只需要存储 logsumexp 。
在第 2.3 节的 2 个块的简单情况下,在线 softmax 技巧现在变为:
我们描述完整的 FlashAttention-2 前向传播算法 1。
算法 1 FlashAttention-2 前向传播
要求:HBM 中的矩阵 ,块大小 。
1: 将 分为 个块 ,大小为 ,并将 分为 个块 和 ,大小为 。 2: 将输出 分为 个块 ,大小为 ,并将 logsumexp 分为 个块 ,大小为 。 3: for do 4: 从 HBM 加载 到片上 SRAM。 5: 在片上,初始化 。 6: for do 7: 从 HBM 加载 到片上 SRAM。 8: 在片上,计算 。 9: 在片上,计算 (逐点),。 10: 在片上,计算 。 11: end for 12: 在片上,计算 。 13: 在片上,计算 。 14: 将 写入 HBM 作为 的第 个块。 15: 将 写入 HBM 作为 的第 个块。 16: end for 17: 返回输出 和 logsumexp 。
因果掩码。注意力的一种常见用例是自回归语言建模,我们需要对注意力矩阵 应用因果掩码(即,任何 的条目 被设置为 )。
- 由于 FlashAttention 和 FlashAttention-2 已经按块操作,对于所有列索引大于行索引的块(对于大序列长度,大约是一半的块),我们可以跳过该块的计算。这导致与没有因果掩码的注意力相比,加速约 1.7-1.8 倍。
- 我们不需要对行索引保证严格小于列索引的块应用因果掩码。这意味着对于每一行,我们只需要对 1 个块应用因果掩码(假设是方形块)。
正确性、运行时间和内存需求
与 FlashAttention 一样,算法 1 返回正确的输出 (无近似),使用 FLOPs,并且除了输入和输出之外还需要 的额外内存(用于存储 logsumexp )。证明与 Dao 等人 [5, Theorem 1] 的证明几乎相同,因此我们在此省略。
3.1.2 反向传播
FlashAttention-2 的反向传播与 FlashAttention 几乎相同。我们做了一个微小的调整,仅使用按行的 logsumexp ,而不是 softmax 中的按行最大值和按行指数和。为了完整起见,我们在算法 2 中包含了反向传播描述。
算法 2 FlashAttention-2 反向传播
要求:HBM 中的矩阵 ,HBM 中的向量 ,块大小 。
1: 将 分为 个块 ,大小为 ,并将 分为 个块 和 ,大小为 。 2: 将 分为 个块 ,大小为 ,将 分为 个块 ,大小为 ,并将 分为 个块 ,大小为 。 3: 在 HBM 中初始化 并将其分为 个块 ,大小为 。将 分为 个块 和 ,大小为 。 4: 计算 (逐点乘法),将 写入 HBM 并将其分为 个块 ,大小为 。 5: for do 6: 从 HBM 加载 到片上 SRAM。 7: 在 SRAM 上初始化 。 8: for do 9: 从 HBM 加载 到片上 SRAM。 10: 在片上,计算 。 11: 在片上,计算 。 12: 在片上,计算 。 13: 在片上,计算 。 14: 在片上,计算 。 15: 从 HBM 加载 到 SRAM,然后在片上更新 ,并写回 HBM。 16: 在片上,计算 。 17: end for 18: 将 写入 HBM。 19: end for 20: 返回 。
多查询注意力和分组查询注意力。多查询注意力 (MQA) [15] 和分组查询注意力 (GQA) [1] 是注意力机制的变体,其中查询的多个头关注键和值的同一个头,以减少推理过程中 KV 缓存的大小。为了计算,我们不需要复制键和值头,而是隐式地操作头索引来执行相同的计算。在反向传播中,我们需要对不同隐式复制的头求和梯度 和 。
3.2 并行化
FlashAttention 的第一个版本在批次大小和头数量上进行并行化。我们使用 1 个线程块来处理一个注意力头,总共有 个线程块。每个线程块被调度在流式多处理器 (SM) 上运行,例如 A100 GPU 上有 108 个这样的 SM。这种调度在数量很大(例如 )时是高效的,因为我们可以有效地使用 GPU 上几乎所有的计算资源。
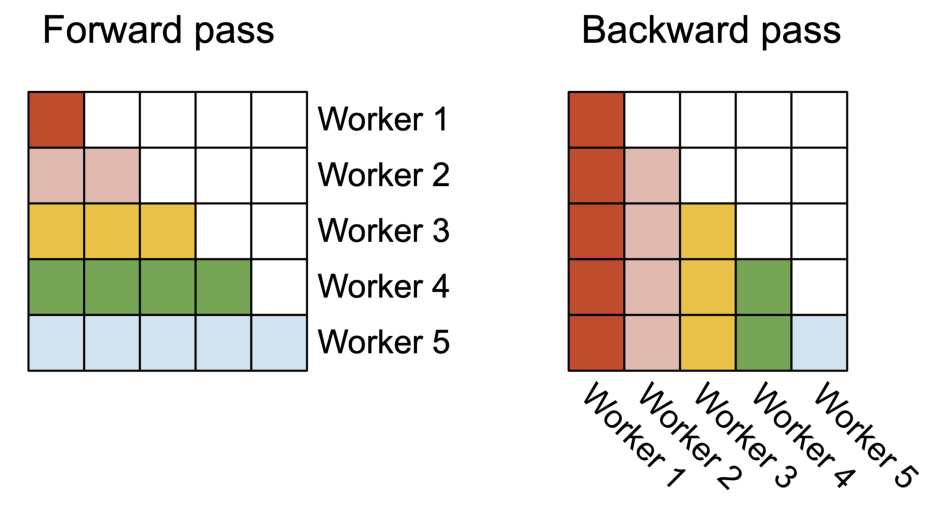
在长序列的情况下(通常意味着小的批次大小或少量的头),为了更好地利用 GPU 上的多处理器,我们现在额外沿着序列长度维度进行并行化。这在此方案中带来了显著的加速。
前向传播。我们看到外循环(在序列长度上)是极其并行的,我们将它们调度在不需要相互通信的不同线程块上。我们还像 FlashAttention 中那样在批次维度和头数量维度上进行并行化。在序列长度上增加的并行化有助于在批次大小和头数量较小时提高占用率(正在使用的 GPU 资源比例),从而在此情况下带来加速。
这些交换循环顺序的想法(外循环在行块上,内循环在列块上,而不是原始 FlashAttention 论文中的相反顺序),以及在序列长度维度上进行并行化,最初是由 Phil Tillet 在 Triton [17] 实现中建议和实现的。
反向传播。注意,不同列块之间唯一的共享计算是在算法 2 中的 更新中,我们需要从 HBM 加载 到 SRAM,然后在片上更新 ,并写回 HBM。因此,我们也沿着序列长度维度进行并行化,并为反向传播的每个列块调度 1 个线程块。我们使用原子加法在不同线程块之间进行通信以更新 。
我们描述图 2 中的并行化方案。
3.3 线程束之间的工作划分
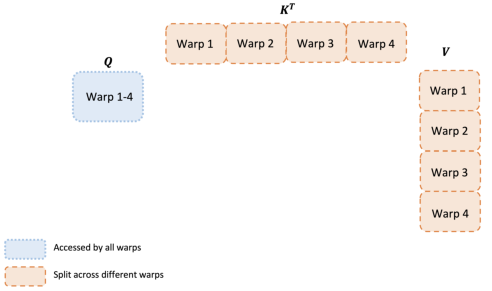
正如第 3.2 节描述我们如何调度线程块一样,即使在每个线程块内,我们也必须决定如何在不同线程束之间划分工作。我们通常每个线程块使用 4 或 8 个线程束,划分方式如图 3 所示。
前向传播。对于每个块,FlashAttention 将 和 拆分到 4 个线程束上,同时保持 可被所有线程束访问。每个线程束相乘得到 的一个切片,然后它们需要与 的一个切片相乘并通信以将结果相加。这被称为“split-K”方案。然而,这是低效的,因为所有线程束都需要将它们的中间结果写出到共享内存,同步,然后将中间结果相加。这些共享内存读/写减慢了 FlashAttention 中的前向传播。
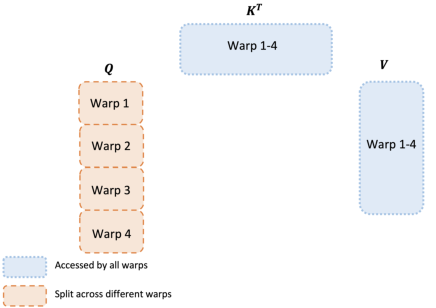
在 FlashAttention-2 中,我们改为将 拆分到 4 个线程束上,同时保持 和 可被所有线程束访问。在每个线程束执行矩阵乘法得到 的一个切片后,它们只需要与它们共享的 切片相乘,即可得到它们对应的输出切片。线程束之间不需要通信。共享内存读/写的减少带来了加速(第 4 节)。
反向传播。同样对于反向传播,我们选择划分线程束以避免“split-K”方案。然而,由于所有不同输入和梯度 之间更复杂的依赖关系,它仍然需要一些同步。尽管如此,避免“split-K”减少了共享内存读/写,并再次带来了加速(第 4 节)。
调整块大小。增加块大小通常会减少共享内存的加载/存储,但会增加所需的寄存器数量和共享内存总量。超过一定的块大小,寄存器溢出会导致显著的减速,或者所需的共享内存量大于 GPU 可用的内存,内核根本无法运行。通常我们选择大小为 的块,具体取决于头维度 和设备共享内存大小。
我们手动调整每个头维度,因为块大小本质上只有 4 种选择,但这可以从自动调整中受益,以避免这种人工劳动。我们将此留给未来的工作。
4 实验验证
我们评估使用 FlashAttention-2 训练 Transformer 模型的影响。
-
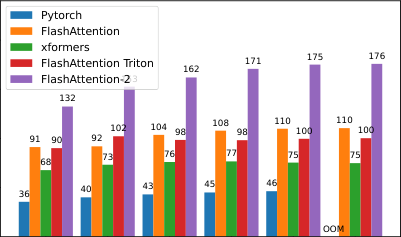
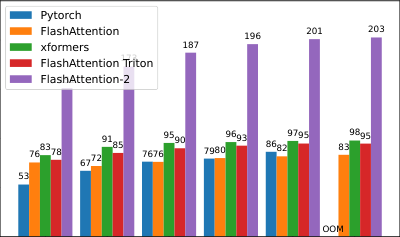
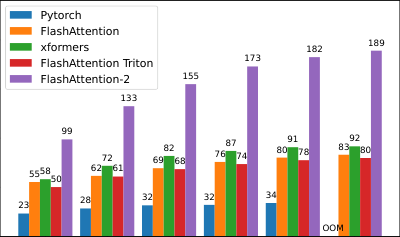
注意力基准测试。我们测量 FlashAttention-2 在不同序列长度下的运行时间,并将其与 PyTorch 中的标准实现、FlashAttention 以及 Triton 中的 FlashAttention 进行比较。我们确认 FlashAttention-2 比 FlashAttention 快 1.7-3.0 倍,比 Triton 中的 FlashAttention 快 1.3-2.5 倍,比标准注意力实现快 3-10 倍。FlashAttention-2 在 A100 GPU 上达到了高达 230 TFLOPs/s,即理论最大 TFLOPs/s 的 73%。
-
端到端训练速度。当端到端用于训练序列长度为 2k 或 8k 的 1.3B 和 2.7B 参数的 GPT 风格模型时,FlashAttention-2 与 FlashAttention 相比带来了高达 1.3 倍的加速,与没有 FlashAttention 的基线相比带来了 2.8 倍的加速。FlashAttention-2 在每块 A100 GPU 上达到了高达 225 TFLOPs/s(72% 的模型 FLOPs 利用率)。
4.1 注意力基准测试
我们在 A100 80GB SXM4 GPU 上针对不同设置(无/有因果掩码,头维度 64 或 128)测量了不同注意力方法的运行时间。我们在图 4、图 5 和图 6 中报告了结果,表明 FlashAttention-2 比 FlashAttention 和 xformers(“cutlass”实现)中的 FlashAttention 快约 2 倍。FlashAttention-2 在前向传播中比 Triton 中的 FlashAttention 快约 1.3-1.5 倍,在反向传播中快约 2 倍。与 PyTorch 中的标准注意力实现相比,FlashAttention-2 最多可快 10 倍。
基准测试设置:我们将序列长度从 512, 1k, ..., 16k 变化,并设置批次大小,使得总标记数为 16k。我们将隐藏维度设置为 2048,头维度设置为 64 或 128(即 32 个头或 16 个头)。为了计算前向传播的 FLOPs,我们使用:
对于因果掩码,我们将此数字除以 2,以考虑到实际上只有大约一半的条目被计算。为了获得反向传播的 FLOPs,我们将前向传播的 FLOPs 乘以 2.5(因为前向传播中有 2 次矩阵乘法,反向传播中有 5 次矩阵乘法,这是由于重计算导致的)。
仅在 H100 GPU 上运行相同的实现(不使用特殊指令来利用 TMA 和第四代 Tensor Cores 等新特性),我们获得了高达 335 TFLOPs/s(图 7)。我们预计通过使用新指令,我们可以在 H100 GPU 上获得额外的 1.5-2 倍加速。我们将此留给未来的工作。
4.2 端到端性能
我们在 8×A100 80GB SXM 上测量了具有 1.3B 或 2.7B 参数的 GPT 风格模型的训练吞吐量。如表 1 所示,FlashAttention-2 与没有 FlashAttention 的基线相比带来了 2.8 倍的加速,与 FlashAttention 相比带来了 1.3 倍的加速,在每块 A100 GPU 上达到了高达 225 TFLOPs/s。
请注意,我们遵循 Megatron-LM [16](以及许多其他论文和库)的公式来计算 FLOPs:
第一项解释了由于权重-输入乘法导致的 FLOPs,第二项解释了由于注意力导致的 FLOPs。然而,有人可能会争辩说第二项应该减半,因为使用因果掩码时,我们只需要计算注意力中大约一半的元素。为了保持一致性,我们选择遵循文献中的公式(不将注意力 FLOPs 除以 2)。
5 讨论和未来方向
FlashAttention-2 比 FlashAttention 快 2 倍,这意味着我们可以以与之前训练 8k 上下文模型相同的价格训练具有 16k 更长上下文的模型。我们对这如何被用于理解长书籍和报告、高分辨率图像、音频和视频感到兴奋。FlashAttention-2 也将加速现有模型的训练、微调和推理。
在不久的将来,我们计划与研究人员和工程师合作,使 FlashAttention 广泛适用于不同类型的设备(例如,H100 GPU、AMD GPU),以及 FP8 等新数据类型。作为直接的下一步,我们计划针对 H100 GPU 优化 FlashAttention-2,以使用新的硬件特性(TMA、第四代 Tensor Cores、fp8)。将 FlashAttention-2 中的底层优化与高层算法变化(例如,局部、扩张、块稀疏注意力)相结合,可以使我们能够训练具有更长上下文的 AI 模型。我们也对与编译器研究人员合作使这些优化技术易于编程感到兴奋。
| 模型 | 无 FlashAttention | FlashAttention | FlashAttention-2 |
|---|---|---|---|
| GPT3-1.3B 2k 上下文 | 142 TFLOPs/s | 189 TFLOPs/s | 196 TFLOPs/s |
| GPT3-1.3B 8k 上下文 | 72 TFLOPs/s | 170 TFLOPs/s | 220 TFLOPs/s |
| GPT3-2.7B 2k 上下文 | 149 TFLOPs/s | 189 TFLOPs/s | 205 TFLOPs/s |
| GPT3-2.7B 8k 上下文 | 80 TFLOPs/s | 175 TFLOPs/s | 225 TFLOPs/s |
表 1:8×A100 GPU 上 GPT 风格模型的训练速度(TFLOPs/s/GPU)。FlashAttention-2 达到了高达 225 TFLOPs/s(72% 的模型 FLOPs 利用率)。我们与没有 FlashAttention 的基线进行了比较。
致谢
我们感谢 Phil Tillet 和 Daniel Haziza,他们实现了 Triton [17] 和 xformers 库 [10] 中的 FlashAttention 版本。FlashAttention-2 的灵感来自于不同注意力实现方式之间的思想交流。我们感谢 Nvidia CUTLASS 团队(特别是 Vijay Thakkar、Cris Cecka、Haicheng Wu 和 Andrew Kerr)提供的 CUTLASS 库,特别是 CUTLASS 3.x 版本,它为 FlashAttention-2 的实现提供了清晰的抽象和强大的构建块。我们感谢 Driss Guessous 将 FlashAttention 集成到 PyTorch 中。FlashAttention-2 受益于与 Phil Wang、Markus Rabe、James Bradbury、Young-Jun Ko、Julien Launay、Daniel Hesslow、Michaël Benesty、Horace He、Ashish Vaswani 和 Erich Elsen 的有益讨论。感谢 Stanford CRFM 和 Stanford NLP 提供的计算支持。我们感谢 Dan Fu 和 Christopher Ré 的合作、建设性反馈以及在设计硬件高效算法这一工作方向上的持续鼓励。我们感谢 Albert Gu 和 Beidi Chen 对本技术报告初稿提出的有益建议。
参考文献
[1] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023.
[2] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
[3] Beidi Chen, Tri Dao, Eric Winsor, Zhao Song, Atri Rudra, and Christopher Ré. Scatterbrain: Unifying sparse and low-rank attention. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
[4] Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. In International Conference on Learning Representations (ICLR), 2020.
[5] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In Advances in Neural Information Processing Systems, 2022.
[6] Zhe Jia and Peter Van Sandt. Dissecting the Ampere GPU architecture via microbenchmarking. GPU Technology Conference, 2021.
[7] Zhe Jia, Marco Maggioni, Benjamin Staiger, and Daniele P Scarpazza. Dissecting the nvidia Volta GPU architecture via microbenchmarking. arXiv preprint arXiv:1804.06826, 2018.
[8] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. In International Conference on Machine Learning, pages 5156–5165. PMLR, 2020.
[9] Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In The International Conference on Machine Learning (ICML), 2020.
[10] Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, Wenhan Xiong, Vittorio Caggiano, Sean Naren, Min Xu, Jieru Hu, Marta Tintore, Susan Zhang, Patrick Labatut, and Daniel Haziza. xformers: A modular and hackable transformer modelling library. https://github.com/facebookresearch/xformers, 2022.
[11] Maxim Milakov and Natalia Gimelshein. Online normalizer calculation for softmax. arXiv preprint arXiv:1805.02867, 2018.
[12] OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
[13] Markus N Rabe and Charles Staats. Self-attention does not need memory. arXiv preprint arXiv:2112.05682, 2021.
[14] Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. Efficient content-based sparse attention with routing transformers. Transactions of the Association for Computational Linguistics, 9: 53–68, 2021.
[15] Noam Shazeer. Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150, 2019.
[16] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019.
[17] Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019.
[18] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[19] Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
[20] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences. Advances in Neural Information Processing Systems, 33, 2020.