直接偏好优化:你的语言模型其实是一个奖励模型
Rafael Rafailov Archit Sharma Eric Mitchell Stefano Ermon Christopher D. Manning Chelsea Finn
斯坦福大学 CZ Biohub {rafailov,architsh,eric.mitchell}@cs.stanford.edu
摘要
尽管大规模无监督语言模型(LMs)学习到了广泛的世界知识和一些推理技能,但由于其训练过程完全是无监督的,因此很难精确控制它们的行为。现有的获取这种可控性的方法是收集人类对模型生成结果相对质量的标注,并利用这些偏好对无监督语言模型进行微调,通常采用人类反馈强化学习(RLHF)。然而,RLHF 是一个复杂且往往不稳定的过程,首先需要拟合一个反映人类偏好的奖励模型,然后使用强化学习对大型无监督语言模型进行微调,以在不偏离原始模型太远的情况下最大化该估计奖励。在本文中,我们引入了一种 RLHF 中奖励模型的新参数化方法,它能够以闭式解(closed form)提取相应的最优策略,使我们能够仅通过简单的分类损失来解决标准的 RLHF 问题。我们将由此产生的算法称为直接偏好优化(Direct Preference Optimization, DPO)。DPO 稳定、高效且计算量小,消除了在微调过程中从语言模型进行采样或进行大量超参数调整的需要。我们的实验表明,DPO 在使语言模型与人类偏好对齐方面,效果与现有方法相当甚至更好。值得注意的是,使用 DPO 进行微调在控制生成情感的能力上超过了基于 PPO 的 RLHF,并且在摘要和单轮对话中匹配或提高了响应质量,同时在实现和训练上要简单得多。
1 引言
在超大规模数据集上训练的大型无监督语言模型(LMs)获得了令人惊讶的能力 [11, 7, 42, 8]。然而,这些模型是在人类生成的数据上训练的,这些数据包含各种各样的目标、优先级和技能集。其中一些目标和技能集可能并不值得模仿;例如,虽然我们可能希望我们的 AI 编程助手能够理解常见的编程错误以便纠正它们,但在生成代码时,我们希望使我们的模型偏向于其训练数据中存在的(可能很少见的)高质量编码能力。同样,我们可能希望我们的语言模型意识到 50% 的人所持有的常见误解,但我们绝对不希望模型在 50% 关于该误解的查询中声称它是正确的!
换句话说,从模型极其广泛的知识和能力中选择其期望的响应和行为,对于构建安全、高性能和可控的 AI 系统至关重要 [28]。虽然现有方法通常使用强化学习(RL)来引导语言模型以匹配人类偏好,但我们将在本文中展示,现有方法使用的基于 RL 的目标函数可以完全通过简单的二元交叉熵目标函数进行优化,从而极大地简化了偏好学习流程。
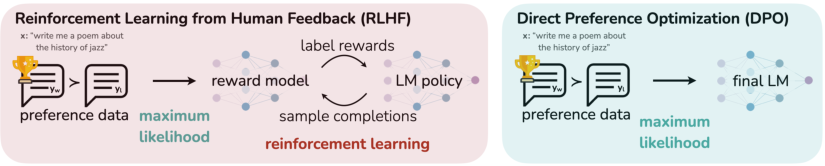
从宏观上看,现有方法使用精心策划的人类偏好集将期望的行为灌输到语言模型中,这些偏好代表了人类认为安全且有帮助的行为类型。这个偏好学习阶段发生在大规模文本数据集的初始无监督预训练阶段之后。虽然偏好学习最直接的方法是在高质量响应的人类演示上进行监督微调,但最成功的一类方法是人类(或 AI)反馈强化学习(RLHF/RLAIF; [12, 2])。RLHF 方法将奖励模型拟合到人类偏好数据集,然后使用 RL 来优化语言模型策略,以产生被分配高奖励的响应,同时不偏离原始模型太远。虽然 RLHF 产生了具有令人印象深刻的对话和编码能力的模型,但 RLHF 流程比监督学习复杂得多,涉及训练多个语言模型并在训练循环中从语言模型策略中进行采样,从而产生了巨大的计算成本。
在本文中,我们展示了如何直接优化语言模型以遵循人类偏好,而无需显式的奖励建模或强化学习。我们提出了直接偏好优化(DPO),这是一种隐式优化与现有 RLHF 算法相同目标(带有 KL 散度约束的奖励最大化)的算法,但实现简单且训练直接。直观地说,DPO 更新增加了偏好响应相对于非偏好响应的对数概率,但它结合了一个动态的、逐样本的重要性权重,防止了我们在朴素概率比目标函数中发现的模型退化。与现有算法一样,DPO 依赖于理论偏好模型(例如 Bradley-Terry 模型;[5]),该模型衡量给定的奖励函数与经验偏好数据的对齐程度。然而,虽然现有方法使用偏好模型来定义偏好损失以训练奖励模型,然后训练一个优化学习到的奖励模型的策略,但 DPO 使用变量替换来直接将偏好损失定义为策略的函数。因此,给定一个关于模型响应的人类偏好数据集,DPO 可以使用简单的二元交叉熵目标函数来优化策略,从而产生拟合到偏好数据的隐式奖励函数的最优策略。
我们的主要贡献是直接偏好优化(DPO),这是一种用于从偏好中训练语言模型的简单无 RL 算法。我们的实验表明,DPO 在学习偏好任务(如情感调节、摘要和对话)方面至少与现有方法(包括基于 PPO 的 RLHF)一样有效,且使用的语言模型参数量高达 6B。
2 相关工作
规模不断扩大的自监督语言模型学会了零样本(zero-shot)[33] 或少样本(few-shot)提示 [6, 27, 11] 完成一些任务。然而,通过在指令和人类编写的完成数据集上进行微调,它们在下游任务上的表现以及与用户意图的对齐可以得到显著改善 [25, 38, 13, 41]。这种“指令微调”过程使大型语言模型(LLMs)能够泛化到指令微调集之外的指令,并普遍提高其可用性 [13]。尽管指令微调取得了成功,但人类对响应质量的相对判断通常比专家演示更容易收集,因此后续工作使用人类偏好数据集对 LLMs 进行了微调,提高了翻译 [20]、摘要 [40, 51]、讲故事 [51] 和指令遵循 [28, 34] 的熟练度。这些方法首先优化神经网络奖励函数,以使其在诸如 Bradley-Terry 模型 [5] 等偏好模型下与偏好数据集兼容,然后使用强化学习算法(通常是 REINFORCE [47]、近端策略优化(PPO; [39])或变体 [34])对语言模型进行微调,以最大化给定的奖励。
3 预备知识
我们回顾了 Ziegler 等人(以及后来的 [40, 1, 28])的 RLHF 流程。它通常包括三个阶段:1) 监督微调(SFT);2) 偏好采样和奖励学习;3) RL 优化。
SFT:RLHF 通常从在感兴趣的下游任务(对话、摘要等)的高质量数据上对预训练的语言模型进行监督微调开始,以获得模型 。
奖励建模阶段:在第二阶段,SFT 模型被提示输入 以产生答案对 。这些答案对随后呈现给人类标注员,他们表达对其中一个答案的偏好,记为 ,其中 和 分别表示 中的偏好完成和非偏好完成。偏好被假设由某个潜在的奖励模型 生成,我们无法直接访问该模型。有许多方法用于建模偏好,Bradley-Terry (BT) [5] 模型是一个流行的选择(尽管如果我们有多个排序答案,更通用的 Plackett-Luce 排序模型 [32, 23] 也与该框架兼容)。BT 模型规定人类偏好分布 可以写为:
假设可以访问从 采样的静态比较数据集 ,我们可以参数化一个奖励模型 并通过最大似然估计参数。将问题框架化为二元分类,我们得到负对数似然损失:
其中 是逻辑函数。在语言模型的背景下,网络 通常从 SFT 模型 初始化,并在最终 transformer 层之上添加一个线性层,产生用于奖励值的单个标量预测 [51]。为了确保奖励函数具有较低的方差,先前的工作对奖励进行了归一化,使得对于所有 ,。
RL 微调阶段:在 RL 阶段,学习到的奖励函数被用于向语言模型提供反馈。遵循先前的工作 [17, 18],优化被表述为:
4 直接偏好优化
受在诸如微调语言模型等大规模问题上应用强化学习算法所面临挑战的驱动,我们的目标是推导一种直接使用偏好进行策略优化的简单方法。与先前学习奖励然后通过 RL 进行优化的 RLHF 方法不同,我们的方法利用了一种特定的奖励模型参数化选择,该选择能够以闭式解提取其最优策略,而无需 RL 训练循环。正如我们接下来将详细描述的那样,我们的关键洞察是利用从奖励函数到最优策略的分析映射,这使我们能够将奖励函数上的损失函数转换为策略上的损失函数。这种变量替换方法避免了拟合显式的、独立的奖励模型,同时仍然在现有的人类偏好模型(如 Bradley-Terry 模型)下进行优化。本质上,策略网络既代表语言模型,也代表(隐式)奖励。
推导 DPO 目标函数。我们从与先前工作相同的 RL 目标函数(公式 3)开始,在通用奖励函数 下。遵循先前的工作 [31, 30, 19, 15],很容易证明公式 3 中 KL 约束奖励最大化目标的最优解具有以下形式:
其中 是配分函数。参见附录 A.1 获取完整推导。即使我们使用真实奖励函数 的 MLE 估计 ,估计配分函数 仍然很昂贵 [19, 15],这使得这种表示在实践中难以利用。然而,我们可以重新排列公式 4,以其对应的最优策略 、参考策略 和未知配分函数 来表示奖励函数。具体来说,我们首先对公式 4 的两边取对数,然后通过一些代数运算,我们得到:
我们可以将这种重参数化应用于真实奖励 和相应的最优模型 。幸运的是,Bradley-Terry 模型仅取决于两个完成之间的奖励差异,即 。将公式 5 中的重参数化代入偏好模型公式 1 中, 的配分函数抵消了,我们可以仅用最优策略 和参考策略 来表示人类偏好概率。因此,Bradley-Terry 模型下的最优 RLHF 策略 满足偏好模型:
推导在附录 A.2 中。虽然公式 6 使用了 Bradley-Terry 模型,但我们可以在更通用的 Plackett-Luce 模型 [32, 23] 下类似地推导表达式,如附录 A.3 所示。现在我们有了用最优策略而不是奖励模型表示的人类偏好数据概率,我们可以为参数化策略 制定最大似然目标。类似于奖励建模方法(即公式 2),我们的策略目标函数变为:
通过这种方式,我们使用另一种参数化拟合了一个隐式奖励,其最优策略就是 。此外,由于我们的过程等同于拟合重参数化的 Bradley-Terry 模型,它在偏好数据分布的适当假设下享有某些理论属性,例如一致性 [4]。在第 5 节中,我们进一步讨论 DPO 与其他工作的理论属性。
5 DPO 的理论分析
在本节中,我们将对 DPO 方法进行进一步解释,提供理论支持,并将 DPO 的优势与用于 RLHF 的演员-评论家(actor-critic)算法(如 PPO [39])所面临的问题联系起来。
5.1 你的语言模型其实是一个奖励模型
DPO 能够绕过拟合显式奖励和执行 RL,使用单个最大似然目标来学习策略。注意优化目标公式 5 等同于具有奖励参数化 的 Bradley-Terry 模型,并且我们优化我们的参数模型 ,这等同于变量替换下的公式 2 中的奖励模型优化。在本节中,我们将构建这种重参数化背后的理论,证明它不会限制学习到的奖励模型类,并允许精确恢复最优策略。我们首先定义奖励函数之间的等价关系。
定义 1。我们称两个奖励函数 和 是等价的,当且仅当对于某个函数 ,有 。
很容易看出这确实是一个等价关系,它将奖励函数集划分为若干类。我们可以陈述以下两个引理:
引理 1。在 Plackett-Luce,特别是 Bradley-Terry 偏好框架下,来自同一类的两个奖励函数诱导出相同的偏好分布。
引理 2。来自同一等价类的两个奖励函数在约束 RL 问题下诱导出相同的最优策略。
证明是直接的,我们将它们推迟到附录 A.5。第一个引理是 Plackett-Luce 模型族中众所周知的欠指定(under-specification)问题 [32]。由于这种欠指定,我们通常必须施加额外的可识别性约束,以实现公式 2 中 MLE 估计的任何保证 [4]。第二个引理指出,来自同一类的所有奖励函数产生相同的最优策略,因此对于我们的最终目标,我们只对从最优类中恢复任意奖励函数感兴趣。我们在附录 A.6 中证明了以下定理:
定理 1。在温和的假设下,所有与 Plackett-Luce(特别是 Bradley-Terry)模型一致的奖励类都可以用重参数化 来表示,对于某个模型 和给定的参考模型 。
6 实验
在本节中,我们实证评估了 DPO 直接从偏好中训练策略的能力。首先,在一个控制良好的文本生成设置中,我们询问:与常见的偏好学习算法(如 PPO)相比,DPO 在最大化奖励和最小化与参考策略的 KL 散度之间权衡的效率如何?接下来,我们评估 DPO 在更大模型和更困难的 RLHF 任务(包括摘要和对话)上的表现。我们发现,几乎不需要调整超参数,DPO 的表现往往与强大的基线(如带有 PPO 的 RLHF)一样好或更好,并且在学习到的奖励函数下返回 个采样轨迹中的最佳轨迹。在展示这些结果之前,我们描述了实验设置;更多细节在附录 C 中。
任务。我们的实验探索了三种不同的开放式文本生成任务。对于所有实验,算法都从偏好数据集 中学习策略。在受控情感生成中, 是 IMDb 数据集 [24] 中电影评论的前缀,策略必须生成具有积极情感的 。为了进行受控评估,对于此实验,我们使用预训练的情感分类器生成关于生成结果的偏好对,其中 。对于 SFT,我们在 IMDB 数据集的训练集上对 GPT-2-large 进行微调直到收敛(更多细节在附录 C.1)。在摘要中, 是 Reddit 上的论坛帖子;策略必须生成帖子中要点的摘要 。遵循先前的工作,我们使用 Reddit TL;DR 摘要数据集 [43] 以及 Stiennon 等人收集的人类偏好。我们使用在人类编写的论坛帖子摘要上微调的 SFT 模型,并使用 TRLX [44] 框架进行 RLHF。人类偏好数据集是由 Stiennon 等人在来自不同但训练相似的 SFT 模型的样本上收集的。最后,在单轮对话中, 是人类查询,它可以是任何内容,从关于天体物理学的问题到关于关系建议的请求。策略必须产生一个引人入胜且有帮助的响应 来回答用户的查询;我们使用 Anthropic Helpful and Harmless 对话数据集 [1],其中包含 170k 个在人类和自动化助手之间的对话。每个转录本都以一对由大型(尽管未知)语言模型生成的响应结束,并带有表示人类偏好响应的偏好标签。在这种设置中,没有可用的预训练 SFT 模型;因此,我们仅在偏好完成上对现成的语言模型进行微调以形成 SFT 模型。
评估。我们的实验使用两种不同的评估方法。为了分析每种算法在优化约束奖励最大化目标方面的有效性,在受控情感生成设置中,我们通过其实现的奖励和与参考策略的 KL 散度的前沿(frontier)来评估每种算法;这个前沿是可计算的,因为我们可以访问真实奖励函数(情感分类器)。然而,在现实世界中,真实奖励函数是未知的;因此,我们使用 GPT-4 作为人类评估摘要质量和响应帮助性的代理,通过它们对基线策略的胜率(win rate)来评估算法,分别在摘要和单轮对话设置中。对于摘要,我们使用测试集中的参考摘要作为基线;对于对话,我们使用测试集中的偏好响应作为基线。
6.1 DPO 优化 RLHF 目标的效果如何?
典型 RLHF 算法中使用的 KL 约束奖励最大化目标在利用奖励和限制策略偏离参考策略之间取得平衡。因此,在比较算法时,我们必须同时考虑实现的奖励以及 KL 差异;实现略高的奖励但具有高得多的 KL 不一定是可取的。图 2 显示了情感设置中各种算法的奖励-KL 前沿。我们为每种算法执行多次训练运行,在每次运行中使用不同的策略保守性超参数(PPO 的目标 KL ,, 用于非似然,Preferred-FT 的随机种子)。这个扫描总共包括 22 次运行。在收敛前的每 100 个训练步骤后,我们在测试提示集上评估每个策略,计算真实奖励函数下的平均奖励以及与参考策略的平均序列级 KL 散度。我们发现 DPO 产生了迄今为止最高效的前沿,在实现低 KL 的同时实现了最高奖励。这个结果在多个方面特别值得注意。首先,DPO 和 PPO 优化相同的目标,但 DPO 明显更高效;DPO 的奖励/KL 权衡严格支配 PPO。其次,即使 PPO 可以访问真实奖励(PPO-GT),DPO 也实现了比 PPO 更好的前沿。
6.2 DPO 能否扩展到真实偏好数据集?
接下来,我们评估 DPO 在摘要和单轮对话上的微调性能。对于摘要,自动评估指标(如 ROUGE)可能与人类偏好相关性较差 [40],先前的工作发现使用 PPO 在人类偏好上微调 LLMs 可以提供更有效的摘要。我们通过在 TL;DR 摘要数据集的测试集上采样完成结果,并计算相对于测试集中参考完成的平均胜率来评估不同的方法。所有方法的完成结果都是在 0.0 到 1.0 之间变化的温度下采样的,胜率如图 2(右)所示。DPO、PPO 和 Preferred-FT 都微调相同的 GPT-J SFT 模型。我们发现 DPO 在 0.0 温度下的胜率约为 61%,超过了 PPO 在其 0.0 的最优采样温度下 57% 的表现。与 个最佳基线相比,DPO 也实现了更高的最大胜率。我们注意到我们没有有意义地调整 DPO 的 超参数,因此这些结果可能低估了 DPO 的潜力。此外,我们发现 DPO 对采样温度比 PPO 稳健得多,PPO 的性能在高温度下会退化到基础 GPT-J 模型的水平。Preferred-FT 在 SFT 模型上没有显著改进。我们还在第 6.4 节的人类评估中对 DPO 和 PPO 进行了正面比较,其中 DPO 在 0.25 温度下的样本比 PPO 在 0 温度下的样本更受青睐,比例为 58%。
在单轮对话上,我们评估了 Anthropic HH 数据集 [1] 测试集子集上的不同方法,该子集具有一步人类-助手交互。GPT-4 评估使用测试集上的偏好完成作为参考,以计算不同方法的胜率。由于此任务没有标准的 SFT 模型,我们从预训练的 Pythia-2.8B 开始,使用 Preferred-FT 在偏好完成上训练参考模型,使得完成结果在模型分布内,然后使用 DPO 进行训练。我们还与 128 个 Preferred-FT 完成中的最佳结果进行了比较(我们发现此任务的 个最佳基线在 128 个完成时趋于平稳;参见附录图 4)以及 Pythia-2.8B 基础模型的 2-shot 提示版本,发现 DPO 在每种方法的最佳性能温度下表现得一样好或更好。我们还评估了一个使用 PPO 在 Anthropic HH 数据集上训练的 RLHF 模型,但无法找到比基础 Pythia-2.8B 模型表现更好的提示或采样温度。基于我们在 TL;DR 上的结果以及两种方法都优化相同奖励函数的事实,我们将 128 个最佳结果视为 PPO 级性能的粗略代理。总体而言,DPO 是唯一一种在计算上高效且比 Anthropic HH 数据集中的偏好完成有所改进的方法,并提供了与计算要求高的 128 个最佳基线相似或更好的性能。最后,图 3 显示 DPO 相对较快地收敛到其最佳性能。
6.3 对新输入分布的泛化
| Alg. | Temp 0 | Temp 0.25 |
|---|---|---|
| DPO | 0.36 | 0.31 |
| PPO | 0.26 | 0.23 |
表 1:GPT-4 胜率 vs. 用于分布外 CNN/DailyMail 输入文章的真实摘要。
为了进一步比较 PPO 和 DPO 在分布偏移下的性能,我们评估了我们在 Reddit TL;DR 摘要实验中的 PPO 和 DPO 策略在不同分布(CNN/DailyMail 数据集 [26] 测试集中的新闻文章)上的表现,使用了来自 TL;DR 的最佳采样温度(0 和 0.25)。结果呈现在表 1 中。我们计算了 GPT-4 相对于数据集中真实摘要的胜率,使用了我们用于 Reddit TL;DR 的相同 GPT-4 (C) 提示,但将“论坛帖子”替换为“新闻文章”。对于这个新分布,DPO 继续以显著优势优于 PPO 策略。该实验提供了初步证据,表明 DPO 策略可以像 PPO 策略一样很好地泛化,即使 DPO 没有使用 PPO 使用的额外未标注 Reddit TL;DR 提示。
6.4 验证 GPT-4 判断与人类判断
我们进行了一项人类研究,以验证 GPT-4 判断的可靠性,使用了 TL;DR 摘要实验的结果和两个不同的 GPT-4 提示。GPT-4 (S)(简单)提示只是询问哪个摘要更好地总结了帖子中的重要信息。GPT-4 (C)(简洁)提示还询问哪个摘要更简洁;我们评估这个提示是因为我们发现 GPT-4 比人类更喜欢用 GPT-4 (S) 提示生成更长、更重复的摘要。参见附录 C.2 获取完整提示。我们进行了三次比较,使用了最高(DPO,温度 0.25)、最低(PPO,温度 1.0)和中等表现(SFT,温度 0.25)的方法,目的是覆盖样本质量的多样性;所有三种方法都与贪婪采样的 PPO(其表现最好的温度)进行了比较。我们发现,对于这两个提示,GPT-4 倾向于与人类达成一致的频率与人类之间达成一致的频率大致相同,这表明 GPT-4 是人类评估的合理代理(由于人类评估员有限,我们仅为 DPO 和 PPO-1 比较收集了多个人类判断)。总体而言,GPT-4 (C) 提示通常提供更具人类代表性的胜率;因此,我们将此提示用于第 6.2 节的主要结果。有关人类研究的更多细节,包括呈现给评估员的 Web 界面和人类志愿者名单,请参见附录 D.3。
| DPO | SFT | PPO-1 | |
|---|---|---|---|
| N 响应者 | 272 | 122 | 199 |
| GPT-4 (S) 胜率 % | 47 | 27 | 13 |
| GPT-4 (C) 胜率 % | 54 | 32 | 12 |
| 人类胜率 % | 58 | 43 | 17 |
| GPT-4 (S)-H 一致性 | 70 | 77 | 86 |
| GPT-4 (C)-H 一致性 | 67 | 79 | 85 |
| H-H 一致性 | 65 | - | 87 |
表 2:比较 TL;DR 摘要样本上的人类和 GPT-4 胜率以及判断一致性。人类与 GPT-4 的一致程度与他们彼此之间的一致程度大致相同。每个实验都将来自所述方法的摘要与来自 PPO(温度 0)的摘要进行了比较。
7 讨论
从偏好中学习是一个强大的、可扩展的框架,用于训练有能力的、对齐的语言模型。我们引入了 DPO,这是一种无需强化学习即可从偏好中训练语言模型的简单训练范式。DPO 没有为了使用现成的 RL 算法而将偏好学习问题强行纳入标准 RL 设置,而是确定了语言模型策略和奖励函数之间的映射,从而能够训练语言模型直接满足人类偏好,使用简单的交叉熵损失,而无需强化学习或损失通用性。几乎不需要调整超参数,DPO 的表现与现有的 RLHF 算法(包括基于 PPO 的算法)相当或更好;因此,DPO 有意义地降低了从人类偏好训练更多语言模型的门槛。
局限性与未来工作。我们的结果提出了几个重要的未来工作问题。与从显式奖励函数学习相比,DPO 策略如何泛化到分布外?我们的初步结果表明,DPO 策略可以与基于 PPO 的模型类似地泛化,但需要更全面的研究。例如,使用来自 DPO 策略的自标注进行训练是否同样可以有效利用未标注的提示?另一方面,奖励过度优化在直接偏好优化设置中如何表现,图 3 右侧性能的轻微下降是否是一个实例?此外,虽然我们评估了高达 6B 参数的模型,但探索将 DPO 扩展到数量级更大的最先进模型是未来工作的一个令人兴奋的方向。关于评估,我们发现 GPT-4 计算的胜率受到提示的影响;未来的工作可以研究从自动化系统中引出高质量判断的最佳方式。最后,DPO 存在许多超出从人类偏好训练语言模型的潜在应用,包括在其他模态中训练生成模型。
致谢 EM 感谢 Knight-Hennessy 研究生奖学金的资助。CF 和 CM 是 CIFAR 研究员。这项工作部分得到了斯坦福学习加速器(SAL)和斯坦福以人为本人工智能研究所(HAI)“未来学习的生成式 AI”种子基金项目的支持。斯坦福基础模型研究中心(CRFM)为本工作中的实验提供了部分计算资源。这项工作部分得到了 ONR 拨款 N00014-20-1-2675 的支持。