QLoRA:量化大语言模型的高效微调
Tim Dettmers*, Artidoro Pagnoni*, Ari Holtzman, Luke Zettlemoyer 华盛顿大学 {dettmers, artidoro, ahai, lsz}@cs.washington.edu
摘要
我们提出了 QLoRA,这是一种高效的微调方法,它能显著降低内存使用量,从而在单张 48GB GPU 上微调 65B 参数的模型,同时保持与全量 16 位微调相当的任务性能。QLORA 通过冻结的 4 位量化预训练语言模型,将梯度反向传播至低秩适配器(LoRA)中。我们命名为 Guanaco 的最佳模型系列在 Vicuna 基准测试中超越了所有先前公开发布的模型,达到了 ChatGPT 性能水平的 99.3%,且仅需在单张 GPU 上微调 24 小时。QLORA 引入了多项创新以在不牺牲性能的前提下节省内存:(a) 4 位 NormalFloat (NF4),这是一种对于正态分布权重在信息论上最优的新型数据类型;(b) 双重量化(Double Quantization),通过量化量化常数来进一步降低平均内存占用;以及 (c) 分页优化器(Paged Optimizers),用于管理内存峰值。我们使用 QLoRA 微调了超过 1,000 个模型,并对 8 个指令数据集、多种模型类型(LLaMA, T5)以及在常规微调下无法运行的模型规模(如 33B 和 65B 参数模型)的指令遵循和聊天机器人性能进行了详细分析。我们的结果表明,在小型高质量数据集上进行 QLoRA 微调可获得最先进的结果,即使在使用比先前 SoTA 更小的模型时也是如此。我们基于人类和 GPT-4 的评估对聊天机器人性能进行了详细分析,结果显示 GPT-4 评估是人类评估的一种廉价且合理的替代方案。此外,我们发现当前的聊天机器人基准测试在准确评估聊天机器人性能水平方面并不可靠。通过对 Guanaco 失败案例的精选分析,我们展示了其与 ChatGPT 的差距。我们发布了所有的模型和代码,包括用于 4 位训练的 CUDA 内核。
1 引言
微调大语言模型(LLMs)是提升其性能 [40, 62, 43, 61, 59, 37] 以及添加期望行为或移除不期望行为 [43, 2, 4] 的一种极其有效的方法。然而,微调超大规模模型代价高昂;对 LLaMA 65B 参数模型 [57] 进行常规的 16 位微调需要超过 780 GB 的 GPU 内存。虽然近期的量化方法可以减少 LLMs 的内存占用 [14, 13, 18, 66],但这些技术仅适用于推理,在训练过程中会失效 [65]。
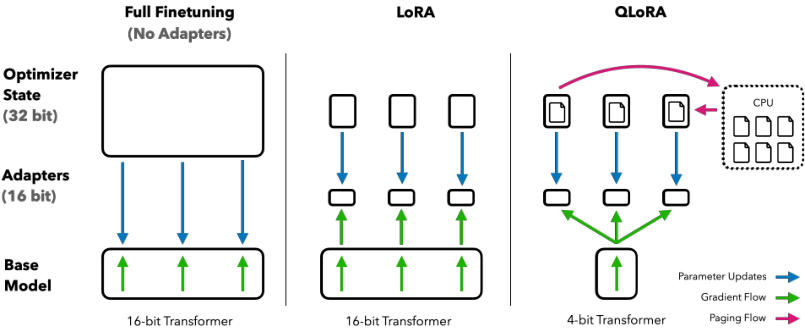
我们首次证明了在不降低任何性能的情况下微调量化 4 位模型是可能的。我们的方法 QLoRA 使用一种新颖的高精度技术将预训练模型量化为 4 位,然后通过反向传播梯度穿过量化权重,添加一组小的可学习低秩适配器权重 [28]。
QLORA 将微调 65B 参数模型的平均内存需求从 >780GB GPU 内存降低到 <48GB,且与 16 位全量微调基线相比,没有降低运行速度或预测性能。这标志着 LLM 微调的可访问性发生了重大转变:现在,迄今为止最大的公开可用模型可以在单张 GPU 上进行微调。使用 QLoRA,我们训练了 Guanaco 模型系列,其中第二好的模型在 Vicuna [10] 基准测试上达到了 ChatGPT 性能水平的 97.8%,且在单张消费级 GPU 上训练时间不到 12 小时;使用单张专业级 GPU 超过 24 小时,我们最大的模型达到了 99.3%,基本消除了与 ChatGPT 在 Vicuna 基准测试上的差距。部署时,我们最小的 Guanaco 模型(7B 参数)仅需 5 GB 内存,且在 Vicuna 基准测试上比 26 GB 的 Alpaca 模型高出 20 个百分点(表 6)。
QLORA 引入了多项旨在降低内存使用而不牺牲性能的创新:(1)4 位 NormalFloat,这是一种对于正态分布数据在信息论上最优的量化数据类型,其经验结果优于 4 位整数和 4 位浮点数。(2)双重量化,一种量化量化常数的方法,平均每个参数节省约 0.37 位(对于 65B 模型约为 3 GB)。(3)分页优化器,使用 NVIDIA 统一内存来避免处理长序列小批量时出现的梯度检查点内存峰值。我们将这些贡献结合成一种调优更好的 LoRA 方法,该方法在每个网络层都包含适配器,从而避免了先前工作中几乎所有的精度权衡。
QLORA 的效率使我们能够对常规微调因内存开销而无法实现的模型规模进行深入的指令微调和聊天机器人性能研究。因此,我们在多个指令微调数据集、模型架构以及 80M 到 65B 参数之间的规模上训练了超过 1,000 个模型。除了展示 QLoRA 恢复了 16 位性能(§4)并训练了一个最先进的聊天机器人 Guanaco(§5)之外,我们还分析了训练模型中的趋势。首先,我们发现数据质量远比数据集大小重要,例如,在聊天机器人性能方面,9k 样本的数据集(OASST1)优于 450k 样本的数据集(FLAN v2,子采样),即使两者都旨在支持指令遵循的泛化。其次,我们表明强大的大规模多任务语言理解(MMLU)基准测试性能并不意味着强大的 Vicuna 聊天机器人基准测试性能,反之亦然——换句话说,对于给定的任务,数据集的适用性比大小更重要。
此外,我们还提供了使用人类评分员和 GPT-4 进行评估的聊天机器人性能的广泛分析。我们使用锦标赛风格的基准测试,让模型在比赛中相互竞争,为给定的提示生成最佳响应。比赛的获胜者由 GPT-4 或人类标注员判定。比赛结果汇总为 Elo 分数 [16, 17],这决定了聊天机器人性能的排名。我们发现 GPT-4 和人类评估在锦标赛中的模型性能排名上基本一致,但也发现存在严重分歧的情况。因此,我们强调,基于模型的评估虽然提供了人类标注的廉价替代方案,但也存在其不确定性。
我们通过对 Guanaco 模型的定性分析增强了我们的聊天机器人基准测试结果。我们的分析突出了定量基准测试未捕捉到的成功和失败案例。我们发布了所有带有人类和 GPT-4 注释的模型生成结果,以促进进一步研究。我们开源了我们的代码库和 CUDA 内核,并将我们的方法集成到 Hugging Face transformers 栈 [64] 中,使所有人都能轻松访问。我们发布了一系列针对 7/13/33/65B 规模模型的适配器,这些模型在 8 个不同的指令遵循数据集上进行了训练,总共 32 个不同的开源微调模型。
表格 1:模型间竞赛的 Elo 评分,取 10,000 次随机初始排序的平均值。比赛获胜者由 GPT-4 决定,GPT-4 针对 Vicuna 基准测试的给定提示声明哪个响应更好。显示了 95% 置信区间 (±)。在 GPT-4 之后,Guanaco 33B 和 65B 赢得的比赛最多,而 Guanaco 13B 的得分高于 Bard。
| 模型 | 大小 | Elo |
|---|---|---|
| GPT-4 | - | 1348 ± 1 |
| Guanaco 65B | 41 GB | 1022 ± 1 |
| Guanaco 33B | 21 GB | 992 ± 1 |
| Vicuna 13B | 26 GB | 974 ± 1 |
| ChatGPT | - | 966 ± 1 |
| Guanaco 13B | 10 GB | 916 ± 1 |
| Bard | - | 902 ± 1 |
| Guanaco 7B | 6 GB | 879 ± 1 |
2 背景
块级 k 位量化 量化是将输入从持有更多信息的表示离散化为持有较少信息的表示的过程。它通常意味着采用具有更多位的数据类型并将其转换为更少的位,例如从 32 位浮点数转换为 8 位整数。为了确保使用低位数据类型的整个范围,通常通过输入元素(通常结构化为张量)的绝对最大值进行归一化,将输入数据类型重新缩放到目标数据类型范围。例如,将 32 位浮点 (FP32) 张量量化为范围为 的 Int8 张量:
其中 是量化常数或量化比例。反量化是其逆过程:
这种方法的问题在于,如果输入张量中出现大数值(即异常值),则量化箱(某些位组合)利用率不高,某些箱中几乎没有或没有数字被量化。为了防止异常值问题,一种常见的方法是将输入张量分块,这些块被独立量化,每个块都有自己的量化常数 。这可以形式化如下:我们将输入张量 分块为 个大小为 的连续块,方法是展平输入张量并将线性段切片为 个块。我们使用公式 1 独立量化这些块,以创建一个量化张量和 个量化常数 。
低秩适配器 低秩适配器 (LoRA) 微调 [28] 是一种通过使用一小组可训练参数(通常称为适配器)来减少内存需求的方法,同时不更新保持固定的全模型参数。随机梯度下降期间的梯度通过固定的预训练模型权重传递到适配器,适配器被更新以优化损失函数。LoRA 通过额外的因子分解投影增强线性投影。给定投影 ,其中 ,,LoRA 计算:
其中 且 , 是一个标量。
参数高效微调的内存需求 一个重要的讨论点是 LoRA 在训练期间的内存需求,包括所使用的适配器的数量和大小。由于 LoRA 的内存占用极小,我们可以使用更多的适配器来提高性能,而不会显著增加总内存使用量。虽然 LoRA 被设计为一种参数高效微调 (PEFT) 方法,但 LLM 微调的大部分内存占用来自激活梯度,而不是学习到的 LoRA 参数。对于在 FLAN v2 上训练的 7B LLaMA 模型,批量大小为 1,LoRA 权重相当于通常使用的原始模型权重的 0.2% [28, 37],LoRA 输入梯度的内存占用为 567 MB,而 LoRA 参数仅占用 26 MB。通过梯度检查点 [9],输入梯度平均减少到每个序列 18 MB,使其比所有 LoRA 权重的总和更消耗内存。相比之下,4 位基础模型消耗 5,048 MB 的内存。这突显了梯度检查点的重要性,但也表明积极减少 LoRA 参数量仅能带来微小的内存收益。这意味着我们可以使用更多的适配器,而不会显著增加整体训练内存占用(详细分解见附录 G)。正如稍后讨论的那样,这对于恢复完整的 16 位精度性能至关重要。
3 QLORA 微调
QLORA 通过我们提出的两种技术——4 位 NormalFloat (NF4) 量化和双重量化——实现了高保真 4 位微调。此外,我们引入了分页优化器,以防止梯度检查点期间的内存峰值导致内存不足错误,这些错误传统上使得大型模型在单台机器上的微调变得困难。
QLORA 有一种低精度存储数据类型(在我们的例子中通常是 4 位)和一种计算数据类型(通常是 BFloat16)。在实践中,这意味着每当使用 QLORA 权重张量时,我们都会将张量反量化为 BFloat16,然后进行 16 位矩阵乘法。
我们现在讨论 QLORA 的组件,随后给出 QLORA 的形式化定义。
4 位 NormalFloat 量化 NormalFloat (NF) 数据类型建立在分位数量化 [15] 的基础上,这是一种信息论上最优的数据类型,确保每个量化箱分配的输入张量值数量相等。分位数量化通过经验累积分布函数估计输入张量的分位数。
分位数量化的主要局限性在于分位数估计过程昂贵。因此,使用快速分位数近似算法(如 SRAM 分位数 [15])来估计它们。由于这些分位数估计算法的近似性质,该数据类型对于异常值具有较大的量化误差,而异常值通常是最重要的值。
当输入张量来自固定到量化常数的分布时,可以避免昂贵的分位数估计和近似误差。在这种情况下,输入张量具有相同的分位数,使得精确的分位数估计在计算上是可行的。
由于预训练神经网络权重通常具有标准差为 的零中心正态分布(见附录 F),我们可以通过缩放 将所有权重转换为单一的固定分布,使得分布完全符合我们数据类型的范围。对于我们的数据类型,我们设置任意范围 。因此,数据类型的分位数和神经网络权重都需要归一化到这个范围内。
对于范围 内具有任意标准差 的零均值正态分布,信息论上最优的数据类型计算如下:(1)估计理论 分布的 个分位数,以获得用于正态分布的 位分位数量化数据类型,(2)采用该数据类型并将其值归一化到 范围,(3)通过绝对最大值重缩放将输入权重张量归一化到 范围来量化它。
一旦权重范围和数据类型范围匹配,我们就可以像往常一样进行量化。步骤 (3) 等同于重缩放权重张量的标准差以匹配 位数据类型的标准差。更正式地,我们估计数据类型的 个值 ,如下所示:
其中 是标准正态分布 的分位数函数。对称 位量化的一个问题是,这种方法没有零的精确表示,这是无误差量化填充和其他零值元素的重要属性。为了确保 0 的离散零点并使用 位数据类型的所有 位,我们通过估计两个范围的分位数 来创建非对称数据类型:负部分为 ,正部分为 ,然后我们统一这些 集合并移除两个集合中都出现的两个零中的一个。我们将所得数据类型称为 位 NormalFloat (NFk),因为该数据类型对于零中心正态分布数据在信息论上是最优的。该数据类型的确切值可以在附录 E 中找到。
双重量化 我们引入双重量化 (DQ),即量化量化常数以进一步节省内存的过程。虽然精确的 4 位量化需要较小的块大小 [13],但它也有相当大的内存开销。例如,对于 使用 32 位常数和 64 的块大小,量化常数平均每个参数增加 位。双重量化有助于降低量化常数的内存占用。
更具体地说,双重量化将第一次量化的量化常数 视为第二次量化的输入。这一步产生了量化的量化常数 和第二级量化常数 。我们对第二次量化使用块大小为 256 的 8 位浮点数,因为对于 8 位量化没有观察到性能下降,这与 Dettmers 和 Zettlemoyer [13] 的结果一致。由于 是正数,我们在量化前从 中减去平均值,以使值围绕零中心化并利用对称量化。平均而言,对于 64 的块大小,这种量化将每个参数的内存占用从 位减少到 位,每个参数减少了 0.373 位。
分页优化器 使用 NVIDIA 统一内存功能,该功能在 GPU 偶尔内存不足的情况下,在 CPU 和 GPU 之间进行自动页面到页面的传输,以实现无错误的 GPU 处理。该功能的工作方式类似于 CPU RAM 和磁盘之间的常规内存分页。我们使用此功能为优化器状态分配分页内存,当 GPU 内存不足时,这些状态会自动被驱逐到 CPU RAM,并在优化器更新步骤中需要内存时分页回 GPU 内存。
QLORA 使用上述组件,我们定义量化基础模型中具有单个 LoRA 适配器的单个线性层的 QLORA 如下:
其中 定义为:
我们对 使用 NF4,对 使用 FP8。我们对 使用 64 的块大小以获得更高的量化精度,对 使用 256 的块大小以节省内存。
对于参数更新,仅需要关于适配器权重 的误差梯度,而不需要 4 位权重 的梯度。然而, 的计算需要计算 ,这通过公式 (5) 进行,并从存储的 反量化到计算数据类型 以计算 BFloat16 精度下的导数 。
总结一下,QLORA 有一种存储数据类型(通常是 4 位 NormalFloat)和一种计算数据类型(16 位 BrainFloat)。我们将存储数据类型反量化为计算数据类型以执行前向和后向传递,但我们仅计算使用 16 位 BrainFloat 的 LoRA 参数的权重梯度。
表格 2:针对 125M 到 13B OPT、BLOOM、LLaMA 和 Pythia 模型,不同数据类型的 Pile Common Crawl 平均困惑度。
| 数据类型 | 平均 PPL |
|---|---|
| Int4 | 34.34 |
| Float4 (E2M1) | 31.07 |
| Float4 (E3M0) | 29.48 |
| NFloat4 + DQ | 27.41 |
表格 3:在 GLUE 和 Super-NaturalInstructions 上比较 16 位 BrainFloat (BF16)、8 位整数 (Int8)、4 位浮点 (FP4) 和 4 位 NormalFloat (NF4) 的实验。QLORA 复制了 16 位 LoRA 和全量微调。
| 数据集 | GLUE (Acc.) | Super-NaturalInstructions (RougeL) | ||||
|---|---|---|---|---|---|---|
| 模型 | RoBERTa-large | T5-80M | T5-250M | T5-780M | T5-3B | T5-11B |
| BF16 | 88.6 | 40.1 | 42.1 | 48.0 | 54.3 | 62.0 |
| BF16 replication | 88.6 | 40.0 | 42.2 | 47.3 | 54.9 | - |
| LoRA BF16 | 88.8 | 40.5 | 42.6 | 47.1 | 55.4 | 60.7 |
| QLORA Int8 | 88.8 | 40.4 | 42.9 | 45.4 | 56.5 | 60.7 |
| QLORA FP4 | 88.6 | 40.3 | 42.4 | 47.5 | 55.6 | 60.9 |
| QLORA NF4 + DQ | - | 40.4 | 42.7 | 47.7 | 55.3 | 60.9 |
表格 4:在 Alpaca 和 FLAN v2 上使用适配器微调的 LLaMA 7-65B 模型,针对不同数据类型的平均 5-shot MMLU 测试准确率。总体而言,带有双重量化 (DQ) 的 NF4 与 BFloat16 性能相当,而 FP4 始终比两者落后一个百分点。
| 平均 5-shot MMLU 准确率 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| LLaMA 大小 | 7B | 13B | 33B | 65B | 平均 | ||||
| 数据集 | Alpaca | FLAN v2 | Alpaca | FLAN v2 | Alpaca | FLAN v2 | Alpaca | FLAN v2 | |
| BFloat16 | 38.4 | 45.6 | 47.2 | 50.6 | 57.7 | 60.5 | 61.8 | 62.5 | 53.0 |
| Float4 | 37.2 | 44.0 | 47.3 | 50.0 | 55.9 | 58.5 | 61.3 | 63.3 | 52.2 |
| NFloat4 + DQ | 39.0 | 44.5 | 47.5 | 50.7 | 57.3 | 59.2 | 61.8 | 63.9 | 53.1 |
表格 5:使用 QLORA 在相应数据集上微调的不同规模 LLaMA 的 MMLU 5-shot 测试结果。
| 数据集 | 7B | 13B | 33B | 65B |
|---|---|---|---|---|
| LLaMA no tuning | 35.1 | 46.9 | 57.8 | 63.4 |
| Self-Instruct | 36.4 | 33.3 | 53.0 | 56.7 |
| Longform | 32.1 | 43.2 | 56.6 | 59.7 |
| Chip2 | 34.5 | 41.6 | 53.6 | 59.8 |
| HH-RLHF | 34.9 | 44.6 | 55.8 | 60.1 |
| Unnatural Instruct | 41.9 | 48.1 | 57.3 | 61.3 |
| Guanaco (OASST1) | 36.6 | 46.4 | 57.0 | 62.2 |
| Alpaca | 38.8 | 47.8 | 57.3 | 62.5 |
| FLAN v2 | 44.5 | 51.4 | 59.2 | 63.9 |
表格 6:由 GPT-4 评估的零样本 Vicuna 基准测试分数,作为 ChatGPT 获得分数的百分比。我们看到 OASST1 模型尽管在非常小的数据集上训练且内存需求仅为基线模型的一小部分,但性能接近 ChatGPT。
| 模型 / 数据集 | 参数 | 模型位数 | 内存 | ChatGPT vs Sys | Sys vs ChatGPT | 平均 | 95% CI |
|---|---|---|---|---|---|---|---|
| GPT-4 | - | - | - | 119.4% | 110.1% | 114.5% | 2.6% |
| Bard | - | - | - | 93.2% | 96.4% | 94.8% | 4.1% |
| Guanaco 65B | 65B | 4-bit | 41 GB | 96.7% | 101.9% | 99.3% | 4.4% |
| Alpaca 65B | 65B | 4-bit | 41 GB | 63.0% | 77.9% | 70.7% | 4.3% |
| FLAN v2 65B | 65B | 4-bit | 41 GB | 37.0% | 59.6% | 48.4% | 4.6% |
| Guanaco 33B | 33B | 4-bit | 21 GB | 96.5% | 99.2% | 97.8% | 4.4% |
| Open Assistant | 33B | 16-bit | 66 GB | 91.2% | 98.7% | 94.9% | 4.5% |
| Alpaca 33B | 33B | 4-bit | 21 GB | 67.2% | 79.7% | 73.6% | 4.2% |
| FLAN v2 33B | 33B | 4-bit | 21 GB | 26.3% | 49.7% | 38.0% | 3.9% |
| Vicuna 13B | 13B | 16-bit | 26 GB | 91.2% | 98.7% | 94.9% | 4.5% |
| Guanaco 13B | 13B | 4-bit | 10 GB | 87.3% | 93.4% | 90.4% | 5.2% |
| Alpaca 13B | 13B | 4-bit | 10 GB | 63.8% | 76.7% | 69.4% | 4.2% |
| HH-RLHF 13B | 13B | 4-bit | 10 GB | 55.5% | 69.1% | 62.5% | 4.7% |
| Unnatural Instr. | 13B | 4-bit | 10 GB | 50.6% | 69.8% | 60.5% | 4.2% |
| Chip2 13B | 13B | 4-bit | 10 GB | 49.2% | 69.3% | 59.5% | 4.7% |
| Longform 13B | 13B | 4-bit | 10 GB | 44.9% | 62.0% | 53.6% | 5.2% |
| Self-Instruct 13B | 13B | 4-bit | 10 GB | 38.0% | 60.5% | 49.1% | 4.6% |
| FLAN v2 13B | 13B | 4-bit | 10 GB | 32.4% | 61.2% | 47.0% | 3.6% |
| Guanaco 7B | 7B | 4-bit | 5 GB | 84.1% | 89.8% | 87.0% | 5.4% |
| Alpaca 7B | 7B | 4-bit | 5 GB | 57.3% | 71.2% | 64.4% | 5.0% |
| FLAN v2 7B | 7B | 4-bit | 5 GB | 33.3% | 56.1% | 44.8% | 4.0% |
表格 7:模型间竞赛的 Elo 评分,由人类评分员或 GPT-4 判定。总体而言,Guanaco 65B 和 33B 在所研究的基准测试中往往优于 ChatGPT-3.5。根据人类评分员的说法,Elo 每 10 分的差异大约是胜率 1.5% 的差异。
| 基准测试 | Vicuna | Vicuna | Open Assistant | |||
|---|---|---|---|---|---|---|
| # 提示 | 80 | 80 | 953 | |||
| 评判 | 人类评分员 | GPT-4 | GPT-4 | 中位数排名 | ||
| 模型 | Elo | 排名 | Elo | 排名 | Elo | 排名 |
| GPT-4 | 1176 | 1 | 1348 | 1 | 1294 | 1 |
| Guanaco-65B | 1023 | 2 | 1022 | 2 | 1008 | 3 |
| Guanaco-33B | 1009 | 4 | 992 | 3 | 1002 | 4 |
| ChatGPT-3.5 Turbo | 916 | 7 | 966 | 5 | 1015 | 2 |
| Vicuna-13B | 984 | 5 | 974 | 4 | 936 | 5 |
| Guanaco-13B | 975 | 6 | 913 | 6 | 885 | 6 |
| Guanaco-7B | 1010 | 3 | 879 | 8 | 860 | 7 |
| Bard | 909 | 8 | 902 | 7 | - | - |
表格 8:CrowS 数据集上的偏见评估。较低的分数表示生成偏见序列的可能性较低。Guanaco 遵循 LLaMA 基础模型的偏见模式。
| LLaMA-65B | GPT-3 | OPT-175B | Guanaco-65B | |
|---|---|---|---|---|
| 性别 | 70.6 | 62.6 | 65.7 | 47.5 |
| 宗教 | 79.0 | 73.3 | 68.6 | 38.7 |
| 种族/肤色 | 57.0 | 64.7 | 68.6 | 45.3 |
| 性取向 | 81.0 | 76.2 | 78.6 | 59.1 |
| 年龄 | 70.1 | 64.4 | 67.8 | 36.3 |
| 国籍 | 64.2 | 61.6 | 62.9 | 32.4 |
| 残疾 | 66.7 | 76.7 | 76.7 | 33.9 |
| 外貌 | 77.8 | 74.6 | 76.2 | 43.1 |
| 社会经济地位 | 71.5 | 73.8 | 76.2 | 55.3 |
| 平均 | 66.6 | 67.2 | 69.5 | 43.5 |
表格 9:不同数据集和模型规模下 QLORA 微调的训练超参数。
| 参数 | 数据集 | 批量大小 | LR | 步数 | 源长度 | 目标长度| 参数 | 数据集 | 批量大小 | LR | 步数 | 源长度 | 目标长度 | | :--- | :--- | :--- | :--- | :--- | :--- | :--- | | 7B | All | 16 | 2e-4 | 10000 | 384 | 128 | | 7B | OASST1 | 16 | 2e-4 | 1875 | - | 512 | | 7B | HH-RLHF | 16 | 2e-4 | 10000 | - | 768 | | 7B | Longform | 16 | 2e-4 | 4000 | 512 | 1024 | | 13B | All | 16 | 2e-4 | 10000 | 384 | 128 | | 13B | OASST1 | 16 | 2e-4 | 1875 | - | 512 | | 13B | HH-RLHF | 16 | 2e-4 | 10000 | - | 768 | | 13B | Longform | 16 | 2e-4 | 4000 | 512 | 1024 | | 33B | All | 32 | 1e-4 | 5000 | 384 | 128 | | 33B | OASST1 | 16 | 1e-4 | 1875 | - | 512 | | 33B | HH-RLHF | 32 | 1e-4 | 5000 | - | 768 | | 33B | Longform | 32 | 1e-4 | 2343 | 512 | 1024 | | 65B | All | 64 | 1e-4 | 2500 | 384 | 128 | | 65B | OASST1 | 16 | 1e-4 | 1875 | - | 512 | | 65B | HH-RLHF | 64 | 1e-4 | 2500 | - | 768 | | 65B | Longform | 32 | 1e-4 | 2343 | 512 | 1024 |
Self-Instruct, Alpaca, Unnatural Instructions Self-Instruct、Alpaca 和 Unnatural Instructions 数据集 [59, 55, 26] 是通过各种模型蒸馏方法(来自 GPT-3 Instruct 和 ChatGPT)收集的指令微调数据集。它们依赖于提示、上下文学习和改写来生成多样化的指令和输出集。这些数据集分别包含 82,612、51,942 和 240,670 个示例。此类蒸馏数据集的一个优势在于,与 FLAN v2 集合及类似的指令微调集合相比,它们包含更多样化的指令风格。
Longform LongForm 数据集 [30] 基于一个扩充了指令的英语语料库,因此是一个混合的人类生成数据集。基础文档由人类撰写,来自 C4 和维基百科,而指令则由 LLM 生成。该数据集通过额外的结构化语料库示例(如 Stack Exchange 和 WikiHow)以及任务示例(如问答、电子邮件撰写、语法纠错、故事/诗歌生成和文本摘要)进行了扩展。该数据集包含 23,700 个示例。
Chip2 是 OIG Laion 数据集的一部分。它包含 Python 代码示例、自然指令示例、通用无害指令、带列表的指令/响应、后续问题、维基百科有毒对抗性问题、小学数学、推理指令以及角色和场景描述,总计 210,289 个示例。
B.2 超参数
我们提供了 QLORA 微调实验中使用的确切超参数。我们发现超参数在不同数据集上具有很强的鲁棒性。我们使用 MMLU 5-shot 开发集进行验证和超参数调优。在所有实验中,我们使用带有双重量化和 bf16 计算数据类型的 NF4。我们设置 LoRA ,,并在基础模型的所有线性层上添加 LoRA 模块。我们还对 13B 及以下模型使用 Adam beta2 为 0.999、最大梯度范数为 0.3 和 LoRA dropout 为 0.1,对 33B 和 65B 模型使用 0.05。遵循先前关于指令微调的工作 [62, 60],并在对其他线性及余弦调度进行基准测试后,我们使用恒定的学习率调度。我们使用 group-by-length 将相似长度的示例分组到同一个批次中(注意这会产生振荡的损失曲线)。每个模型规模调优的超参数如表 9 所示。
B.3 消融实验
虽然在指令遵循数据集的文献中,通常只在响应上进行训练,但我们在表 10 中研究了在指令和响应上同时进行训练的效果。在这些实验中,我们将训练数据限制为 52,000 个示例,并使用 7B 模型。在四个不同的指令微调数据集上,我们发现仅在目标上进行训练对 MMLU 性能更有利。我们没有评估这对 Vicuna 或 OA 基准测试所测量的聊天机器人性能可能产生的影响。
表格 10:研究在指令和响应上同时进行训练对 MMLU 5-shot 测试结果的影响。
| 数据集 | Unnatural Instructions | Chip2 | Alpaca | FLAN v2 | 平均 |
|---|---|---|---|---|---|
| Train on source and target | 36.2 | 33.7 | 38.1 | 42.0 | 37.5 |
| Train on target | 38.0 | 34.5 | 39.0 | 42.9 | 38.6 |
B.4 什么更重要:指令微调数据集大小还是数据集质量?
数据集适用性比数据集大小更重要。 为了理解数据集质量与数据集大小的影响,我们尝试将至少包含 150,000 个样本的大型数据集(Chip2, FLAN v2, Unnatural Instructions)子采样为 50,000、100,000 和 150,000 个样本的数据集,并检查由此产生的趋势,如表 11 所示。我们发现增加数据集大小和增加 epoch 数仅能边际性地提高 MMLU(0.0 - 0.5 MMLU),而数据集之间的差异则大 40 倍(1.5 - 8.0 MMLU)。这是一个明确的指标,表明数据集质量而非数据集大小对于平均 MMLU 准确率至关重要。正如所讨论的那样,我们在聊天机器人性能方面也获得了类似的发现。
C 人类评估
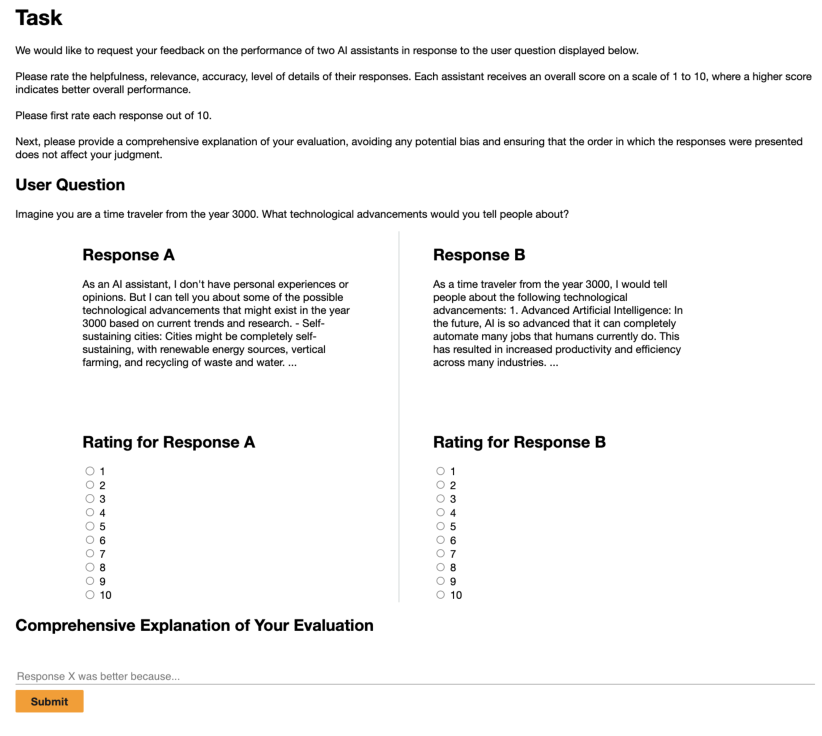
我们进行了一项人类评估,使用了与原始 Vicuna 评估 [10] 中给 GPT-4 的相同措辞,并针对 Amazon Mechanical Turk 表单进行了调整,如图 5 所示。
D 使用 GPT-4 进行成对评估
虽然我们发现 GPT-4 评估的结果取决于哪个系统先呈现,但在对两个选项进行平均后,成对结果是有序的。汇总的成对判断如表 12 所示。经检查,很明显这些判断是传递性的,即当系统 A 被判定优于系统 B,且系统 B 被判定优于系统 C 时,系统 A 总是被判定优于系统 C。这产生了一个完整的排序,如表 13 所示。
E NormalFloat 4 位数据类型
NF4 数据类型的确切值如下: [-1.0, -0.6961928009986877, -0.5250730514526367, -0.39491748809814453, -0.28444138169288635, -0.18477343022823334, -0.09105003625154495, 0.0, 0.07958029955625534, 0.16093020141124725, 0.24611230194568634, 0.33791524171829224, 0.44070982933044434, 0.5626170039176941, 0.7229568362236023, 1.0]
F 训练后的神经网络权重的正态性
虽然众所周知训练后的神经网络权重大多呈正态分布,但我们执行了统计测试来验证这一点。我们对 7B LLaMA 模型 [57] 的权重使用了 Shapiro-Wilk 测试 [53]。我们发现每个隐藏单元的权重具有不同的正态分布。因此,我们测试了每个单独隐藏单元的权重。这意味着对于权重 ,我们对 维度进行了测试。使用 5% 的显著性阈值,我们发现 7.5% 的神经元是非正态分布的,这比预期的假阳性率高出约 2.5%。因此,虽然几乎所有预训练权重看起来都呈正态分布,但似乎存在例外。这些例外可能是由于异常值权重 [13],或者是因为 Shapiro-Wilk 测试的 值对于 LLaMA FFN 层隐藏单元中出现的大样本量 [53] 不准确。这验证了神经网络权重的声明。
表格 11:不同数据集大小和微调 epoch 对平均 5-shot MMLU 测试集准确率的影响。虽然增加数据集大小和训练超过 1 个 epoch 有助于 MMLU 性能,但数据集之间的差异要大得多,这表明数据集质量对 MMLU 性能的影响比数据集大小更大。
| Chip | Unnatural Instructions | FLAN v2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Datapoints ↓ Epochs → | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 平均 |
| 50000 | 34.50 | 35.30 | 34.70 | 38.10 | 42.20 | 38.10 | 43.00 | 43.50 | 44.10 | 39.28 |
| 100000 | 33.70 | 33.90 | 34.00 | 40.10 | 41.20 | 37.00 | 43.90 | 43.70 | 44.90 | 39.16 |
| 150000 | 34.40 | 34.80 | 35.10 | 39.70 | 41.10 | 41.50 | 44.60 | 45.50 | 43.50 | 40.02 |
| 平均 | 34.20 | 34.67 | 34.60 | 39.30 | 41.50 | 38.87 | 43.83 | 44.23 | 44.17 |
表格 12:系统之间的汇总成对 GPT-4 判断,其中行 和列 处单元格的值为
| 模型 | Guanaco 65B | Guanaco 33B | Vicuna | ChatGPT-3.5 Turbo | Bard | Guanaco 13B | Guanaco 7B |
|---|---|---|---|---|---|---|---|
| Guanaco 65B | - | 0.21 | 0.19 | 0.16 | 0.72 | 0.59 | 0.86 |
| Guanaco 33B | -0.21 | - | 0.17 | 0.10 | 0.51 | 0.41 | 0.68 |
| Vicuna | -0.19 | -0.17 | - | 0.10 | 0.50 | 0.20 | 0.57 |
| ChatGPT-3.5 Turbo | -0.16 | -0.10 | -0.10 | - | 0.35 | 0.19 | 0.40 |
| Bard | -0.72 | -0.51 | -0.50 | -0.35 | - | 0.12 | 0.03 |
| Guanaco 13B | -0.59 | -0.41 | -0.20 | -0.19 | -0.12 | - | 0.20 |
| Guanaco 7B | -0.86 | -0.68 | -0.57 | -0.40 | -0.03 | -0.20 | - |
G 内存占用
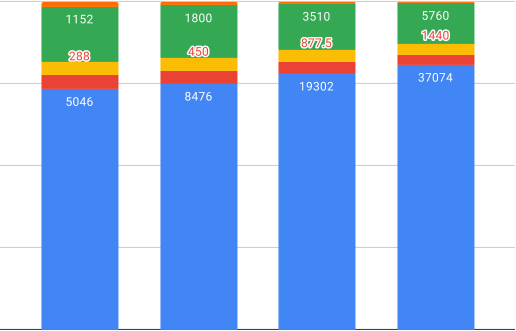
QLORA 训练不同 LLaMA 基础模型的内存占用如图 6 所示。我们看到 33B 模型不太适合 24 GB 内存,需要分页优化器来训练它。图中还描绘了批量大小为 1、序列长度为 512 和梯度检查点的情况。这意味着,如果使用更大的批量大小,或者处理长序列,激活梯度可能会消耗相当多的内存。
表格 13:由成对 GPT-4 判断诱导的系统完整排序
| 模型 | 参数 | 大小 |
|---|---|---|
| Guanaco 65B | 65B | 41 GB |
| Guanaco 33B | 33B | 21 GB |
| Vicuna 13B | 13B | 26 GB |
| ChatGPT-3.5 Turbo | N/A | N/A |
| Bard | N/A | N/A |
| Guanaco 13B | 13B | 10 GB |
| Guanaco 7B | 7B | 5 GB |