思维树:利用大语言模型进行深思熟虑的问题解决
Shunyu Yao 普林斯顿大学
Dian Yu Google DeepMind
Jeffrey Zhao Google DeepMind
Izhak Shafran Google DeepMind
Thomas L. Griffiths 普林斯顿大学
Yuan Cao Google DeepMind
Karthik Narasimhan 普林斯顿大学
摘要
语言模型正日益被部署用于广泛任务的通用问题解决,但在推理过程中仍局限于标记(token)级别的从左到右的决策过程。这意味着它们在需要探索、战略性前瞻或初始决策起关键作用的任务中可能会表现不佳。为了克服这些挑战,我们引入了一种新的语言模型推理框架——“思维树”(Tree of Thoughts, ToT),它推广了流行的“思维链”(Chain of Thought)提示方法,并能够对作为解决问题中间步骤的连贯文本单元(“思维”)进行探索。ToT 允许语言模型通过考虑多种不同的推理路径和自我评估选择来决定下一步行动,从而进行深思熟虑的决策,并在必要时进行前瞻或回溯以做出全局选择。我们的实验表明,ToT 在三个需要非平凡规划或搜索的新任务上显著增强了语言模型的问题解决能力:24点游戏、创意写作和迷你填字游戏。例如,在24点游戏中,GPT-4 使用思维链提示仅解决了 4% 的任务,而我们的方法达到了 74% 的成功率。代码库及所有提示词:https://github.com/princeton-nlp/tree-of-thought-llm。
1 引言
最初设计用于生成文本的大规模语言模型(LM),如 GPT [25, 26, 1, 23] 和 PaLM [5],已被证明在执行需要数学、符号、常识和知识推理的更广泛任务方面具有越来越强的能力。令人惊讶的是,所有这些进步的基础仍然是最初的自回归文本生成机制,它逐个进行标记级别的决策,且以从左到右的方式进行。这种简单的机制是否足以让 LM 成为通用问题解决者?如果不是,哪些问题会挑战当前的范式,又应该有哪些替代机制?
人类认知文献为回答这些问题提供了一些线索。关于“双过程”模型的研究表明,人们在处理决策时有两种模式——一种是快速、自动、无意识的模式(“系统 1”),另一种是缓慢、深思熟虑、有意识的模式(“系统 2”)[30, 31, 16, 15]。这两种模式此前已与机器学习中使用的各种数学模型联系起来。例如,关于人类和其他动物强化学习的研究探讨了它们在何种情况下进行联想式“无模型”学习或更深思熟虑的“基于模型”的规划 [7]。LM 简单的联想式标记级选择也让人联想到“系统 1”,因此可能受益于更深思熟虑的“系统 2”规划过程的增强,该过程 (1) 维护并探索当前决策的多种替代方案,而不是仅仅选择一个,以及 (2) 评估其当前状态并主动前瞻或回溯以做出更全局的决策。
为了设计这样的规划过程,我们回归人工智能(和认知科学)的起源,汲取了 Newell、Shaw 和 Simon 自 20 世纪 50 年代以来探索的规划过程的灵感 [21, 22]。Newell 等人将问题解决 [21] 描述为在组合问题空间中的搜索,该空间表示为一棵树。因此,我们提出了用于语言模型通用问题解决的思维树(ToT)框架。如图 1 所示,虽然现有方法(详见下文)采样连续的语言序列来解决问题,但 ToT 主动维护一棵思维树,其中每个思维都是一个连贯的语言序列,作为解决问题的中间步骤(表 1)。这种高级语义单元允许 LM 通过同样以语言实例化的深思熟虑的推理过程,自我评估不同中间思维在解决问题方面的进展(图 2, 4, 6)。这种通过 LM 自我评估和审议来实现搜索启发式的方法是新颖的,因为以前的搜索启发式要么是编程的,要么是学习的。最后,我们将这种基于语言的生成和评估多样化思维的能力与搜索算法(如广度优先搜索 (BFS) 或深度优先搜索 (DFS))相结合,从而允许对思维树进行系统性的探索,并具备前瞻和回溯功能。
在实证方面,我们提出了三个即使使用最先进的语言模型 GPT-4 [23] 也具有挑战性的新问题:24点游戏、创意写作和填字游戏(表 1)。这些任务需要演绎、数学、常识、词汇推理能力,以及结合系统规划或搜索的方法。我们展示了 ToT 在所有三项任务上都获得了优越的结果,因为它足够通用和灵活,能够支持不同层级的思维、不同的思维生成和评估方式,以及适应不同问题性质的搜索算法。我们还通过系统性的消融实验分析了这些选择如何影响模型性能,并讨论了更好地训练和使用 LM 的未来方向。
2 背景
我们首先形式化一些现有的使用大语言模型进行问题解决的方法,我们的方法受到这些方法的启发并随后与之进行比较。我们使用 表示具有参数 的预训练 LM,并使用小写字母 表示语言序列,即 ,其中每个 是一个标记,因此 。我们使用大写字母 表示语言序列的集合。
输入-输出 (IO) 提示是将问题输入 转化为 LM 输出 的最常见方式:,其中 将输入 与任务指令和/或少样本输入-输出示例包装在一起。为简单起见,我们记 ,因此 IO 提示可以表述为 。
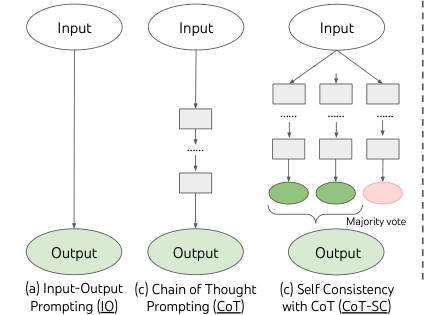
思维链 (CoT) 提示 [38] 被提出用于解决输入 到输出 的映射非平凡的情况(例如,当 是数学问题而 是最终数值答案时)。关键思想是引入思维链 来连接 和 ,其中每个 是一个连贯的语言序列,作为解决问题的有意义的中间步骤(例如, 可以是数学问答的中间方程)。为了用 CoT 解决问题,每个思维 被顺序采样,然后输出 。在实践中, 作为连续语言序列被采样,而思维的分解(例如,每个 是短语、句子还是段落)是模糊的。
带有 CoT 的自洽性 (CoT-SC) [36] 是一种集成方法,它采样 个独立同分布的思维链: (),然后返回最频繁的输出:。CoT-SC 在 CoT 的基础上进行了改进,因为对于同一个问题通常存在不同的思维过程(例如,证明同一个定理的不同方法),并且通过探索更丰富的思维集,输出决策可以更可靠。然而,在每个链条内部,没有对不同思维步骤的局部探索,并且“最频繁”启发式仅在输出空间有限时(例如多项选择问答)适用。
3 思维树:利用 LM 进行深思熟虑的问题解决
“一个真正的问题解决过程涉及重复使用可用信息来启动探索,这反过来又会揭示更多信息,直到最终发现通往解决方案的途径。”——Newell 等人 [21]
关于人类问题解决的研究表明,人们在组合问题空间中进行搜索——这是一棵树,其中节点代表部分解决方案,分支对应于修改它们的算子 [21, 22]。采取哪个分支由启发式方法决定,这些启发式方法有助于导航问题空间并引导问题解决者走向解决方案。这一视角突出了现有使用 LM 解决通用问题的方法的两个关键缺陷:1) 在局部,它们不会探索思维过程中的不同延续——即树的分支。2) 在全局,它们不包含任何类型的规划、前瞻或回溯来帮助评估这些不同的选项——这种启发式引导的搜索似乎是人类问题解决的特征。
为了解决这些缺陷,我们引入了思维树 (ToT),这是一种允许 LM 探索思维上多种推理路径的范式(图 1(c))。ToT 将任何问题构建为树上的搜索,其中每个节点是一个状态 ,代表带有输入和迄今为止思维序列的部分解决方案。ToT 的具体实例化涉及回答四个问题:1. 如何将中间过程分解为思维步骤;2. 如何从每个状态生成潜在思维;3. 如何启发式地评估状态;4. 使用什么搜索算法。
1. 思维分解。 虽然 CoT 在没有明确分解的情况下连贯地采样思维,但 ToT 利用问题属性来设计和分解中间思维步骤。如表 1 所示,根据不同的问题,思维可以是几个词(填字游戏)、一行方程(24点游戏)或整段写作计划(创意写作)。通常,思维应该足够“小”,以便 LM 能够生成有希望且多样化的样本(例如,生成整本书通常太“大”而无法连贯),但又足够“大”,以便 LM 能够评估其解决问题的前景(例如,生成一个标记通常太“小”而无法评估)。
2. 思维生成器 。 给定树状态 ,我们考虑两种策略来为下一个思维步骤生成 个候选者: (a) 从 CoT 提示中采样独立同分布的思维(创意写作,图 4): ()。当思维空间丰富时(例如每个思维都是一个段落),这效果更好,且独立同分布样本带来了多样性; (b) 使用“提议提示”顺序提议思维(24点游戏,图 2;填字游戏,图 6):。当思维空间受到更多限制时(例如每个思维只是一个词或一行),这效果更好,因此在相同上下文中提议不同的思维避免了重复。
3. 状态评估器 。 给定不同状态的前沿,状态评估器评估它们在解决问题方面取得的进展,作为搜索算法的启发式方法,以确定保留哪些状态进行探索以及以何种顺序探索。虽然启发式是解决搜索问题的标准方法,但它们通常要么是编程的(例如 DeepBlue [3]),要么是学习的(例如 AlphaGo [29])。我们提出了第三种替代方案,即利用 LM 对状态进行深思熟虑的推理。在适用时,这种深思熟虑的启发式方法可以比编程规则更灵活,比学习模型更具样本效率。类似于思维生成器,我们考虑两种策略来独立或共同评估状态: (a) 独立评估每个状态:,其中价值提示对状态 进行推理以生成标量值 (例如 1-10)或分类(例如确定/可能/不可能),这些可以启发式地转化为值。这种评估推理的基础可以因问题和思维步骤而异。在这项工作中,我们探索通过少量前瞻模拟进行评估(例如,快速确认 5, 5, 14 可以通过 5 + 5 + 14 达到 24,或者“hot l”可以通过在“ ”中填入“e”来表示“inn”),加上常识(例如 1 2 3 太小而无法达到 24,或者没有单词可以以“tzxc”开头)。虽然前者可能促进“好”状态,但后者可能有助于消除“坏”状态。此类估值不需要完美,只需要对决策大致有帮助即可。 (b) 跨状态投票:,其中“好”状态 是基于在投票提示中深思熟虑地比较 中的不同状态而投票选出的。当问题成功更难直接评估时(例如段落连贯性),自然会比较不同的部分解决方案并投票选出最有希望的一个。这在精神上类似于“逐步”自洽性策略,即把“探索哪个状态”作为多项选择问答,并使用 LM 样本对其进行投票。
对于这两种策略,我们都可以多次提示 LM 以聚合价值或投票结果,从而以时间/资源/成本为代价换取更忠实/稳健的启发式方法。
| 算法 1 ToT-BFS() | 算法 2 ToT-DFS() |
|---|---|
| 要求: 输入 , LM , 思维生成器 及大小限制 , 状态评估器 , 步骤限制 , 广度限制 。 | 要求: 当前状态 , 步骤 , LM , 思维生成器 及大小限制 , 状态评估器 , 步骤限制 , 阈值 |
| if then 记录输出 | |
| for do | end if |
| for do ▷ 排序候选者 | |
| if then ▷ 剪枝 | |
| DFS() | |
| end for | end if |
| return | end for |
4. 搜索算法。 最后,在 ToT 框架内,可以根据树结构即插即用不同的搜索算法。我们探索了两种相对简单的搜索算法,并将更高级的算法(例如 A* [11], MCTS [2])留待未来工作: (a) 广度优先搜索 (BFS)(算法 1)每步维护一组 个最有希望的状态。这用于 24点游戏和创意写作,其中树深度有限 (),并且初始思维步骤可以被评估并剪枝为一个小集合 ()。 (b) 深度优先搜索 (DFS)(算法 2)首先探索最有希望的状态,直到达到最终输出 (),或者状态评估器认为从当前 解决问题是不可能的 (,对于价值阈值 )。在后一种情况下,从 开始的子树被剪枝,以用探索换取利用。在这两种情况下,DFS 都会回溯到 的父状态以继续探索。
从概念上讲,ToT 作为一种使用 LM 进行通用问题解决的方法有几个好处:(1) 通用性。IO、CoT、CoT-SC 和自我修正可以被视为 ToT 的特例(即深度和广度有限的树;图 1)。(2) 模块化。基础 LM 以及思维分解、生成、评估和搜索过程都可以独立变化。(3) 适应性。可以适应不同的问题属性、LM 能力和资源限制。(4) 便利性。无需额外训练,仅需预训练的 LM 即可。下一节将展示这些概念上的好处如何转化为不同问题中的强大实证性能。
4 实验
我们提出了三项任务,即使在使用标准 IO 提示或思维链 (CoT) 提示从最先进的语言模型 GPT-4 [23] 中采样时,这些任务也很困难。
| 24点游戏 | 创意写作 | 5x5 填字游戏 | |
|---|---|---|---|
| 输入 | 4 个数字 (4 9 10 13) | 4 个随机句子 | 10 条线索 (h1. presented;..) |
| 输出 | 到达 24 的方程 (13-9)*(10-4)=24 | 以 4 个句子结尾的 4 段文章 | 5x5 字母: SHOWN; WIRRA; AVAIL; ... |
| 思维 | 3 个中间方程 (13-9=4 (剩 4,4,10); 10-4=6 (剩 4,6); 4*6=24) | 短写作计划 (1. 介绍一本连接...) | 填入线索的单词: (h1. shown; v5. naled; ...) |
| #ToT 步骤 | 3 | 1 | 5-10 (可变) |
表 1:任务概述。输入、输出、思维示例为蓝色。
我们展示了思维树 (ToT) 中的深思熟虑搜索产生了更好的结果,更重要的是,产生了使用语言模型解决需要搜索或规划的问题的有趣且有前景的新方法。除非另有说明,我们使用 Chat Completion 模式的 GPT-4,采样温度为 0.7。
4.1 24点游戏
24点游戏是一项数学推理挑战,目标是使用 4 个数字和基本算术运算 (+-*/) 得到 24。例如,给定输入“4 9 10 13”,解决方案输出可以是“(10 - 4) * (13 - 9) = 24”。
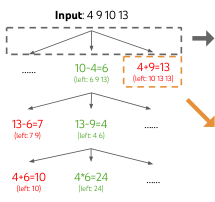
任务设置。 我们从 4nums.com 抓取数据,该网站有 1,362 个游戏,按人类解决时间从易到难排序,并使用索引为 901-1,000 的相对较难的游戏子集进行测试。对于每项任务,如果输出是一个有效的方程,等于 24 且每个输入数字恰好使用一次,我们认为输出成功。我们报告 100 个游戏的成功率作为指标。
基线。 我们使用带有 5 个上下文示例的标准输入-输出 (IO) 提示。对于思维链 (CoT) 提示,我们用 3 个中间方程增强每个输入-输出对,每个方程对两个剩余数字进行运算。例如,给定输入“4 9 10 13”,思维可以是“13 - 9 = 4 (剩: 4 4 10); 10 - 4 = 6 (剩: 4 6); 4 * 6 = 24 (剩: 24)”。对于每个游戏,我们采样 IO 和 CoT 提示 100 次以获得平均性能。我们还考虑了一个 CoT 自洽性基线,它取 100 个 CoT 样本中的多数输出,以及在 IO 样本之上进行最多 10 次迭代的迭代修正方法。在每次迭代中,LM 被条件化在所有历史记录上,如果输出不正确,则“反思你的错误并生成修正后的答案”。注意,它使用了关于方程正确性的真实反馈信号。
ToT 设置。 为了将 24点游戏纳入 ToT,自然地将思维分解为 3 个步骤,每个步骤是一个中间方程。如图 2(a) 所示,在每个树节点,我们提取剩余数字并提示 LM 提议一些可能的下一步。相同的“提议提示”用于所有 3 个思维步骤,尽管它只有一个带有 4 个输入数字的示例。我们在 ToT 中执行广度优先搜索 (BFS),每一步我们保留最好的 个候选者。为了在 ToT 中执行深思熟虑的 BFS,如图 2(b) 所示,我们提示 LM 将每个思维候选者评估为“确定/可能/不可能”,以达到 24。目的是促进可以在少量前瞻试验中判定正确的中间解决方案,并基于“太大/太小”的常识消除不可能的部分解决方案,并保留其余的“可能”。我们对每个思维采样 3 次值。
| 方法 | 成功率 |
|---|---|
| IO 提示 | 7.3% |
| CoT 提示 | 4.0% |
| CoT-SC () | 9.0% |
| ToT (我们的) () | 45% |
| ToT (我们的) () | 74% |
| IO + 修正 () | 27% |
| IO (100 次中最好) | 33% |
| CoT (100 次中最好) | 49% |
表 2:24点游戏结果。
结果。 如表 2 所示,IO、CoT 和 CoT-SC 提示方法在该任务上表现不佳,仅分别达到 7.3%、4.0% 和 9.0% 的成功率。相比之下,广度为 的 ToT 已经达到了 45% 的成功率,而 则达到了 74%。我们还考虑了 IO/CoT 的预言机设置,通过计算 个样本中最好的成功率 ()。为了比较 IO/CoT( 个中最好)与 ToT,我们考虑计算 ToT 中跨 每个任务访问的树节点,并映射图 3(a) 中的 5 个成功率,将 IO/CoT( 个中最好)视为在老虎机中访问 个节点。不出所料,CoT 的扩展性比 IO 好,100 个 CoT 样本中最好的成功率达到了 49%,但仍然比在 ToT 中探索更多节点 () 差得多。
错误分析。 图 3(b) 分解了 CoT 和 ToT 样本在哪个步骤失败,即思维(在 CoT 中)或所有 个思维(在 ToT 中)无效或不可能达到 24。值得注意的是,大约 60% 的 CoT 样本在生成第一步后,或者等同于前三个词(例如“4 + 9”)后就已经失败了。这突出了直接从左到右解码的问题。
4.2 创意写作
接下来,我们发明了一个创意写作任务,其中输入是 4 个随机句子,输出应该是以 4 个输入句子分别结尾的 4 段连贯文章。这样的任务是开放式的和探索性的,挑战创造性思维以及高级规划。
任务设置。 我们从 randomwordgenerator.com 采样随机句子以形成 100 个输入,并且每个输入约束没有真实文章。由于我们发现 GPT-4 大部分时间都能遵循输入约束,我们专注于以两种方式评估文章连贯性:使用 GPT-4 零样本提示提供 1-10 的标量分数,或使用人类判断来比较不同方法的输出对。对于前者,我们采样 5 个分数并取平均值作为每个任务输出,我们发现这 5 个分数通常是一致的,在所有输出中平均标准差约为 0.56。对于后者,我们聘请了一部分作者进行盲测,以比较 CoT 与 ToT 生成的文章对的连贯性,其中文章顺序在 100 个输入上是随机翻转的。
基线。 鉴于任务的创造性,IO 和 CoT 提示都是零样本的。虽然前者提示 LM 在给定输入约束的情况下直接生成连贯的文章,但后者提示 LM 先做一个简短的计划,然后写文章,即计划作为中间思维步骤。我们为每个任务生成 10 个 IO 和 CoT 样本。我们还考虑了在每个任务的随机 IO 样本之上的迭代修正 () 方法,其中 LM 被条件化在输入约束和最后生成的文章上,以决定文章是否已经“完全连贯”,如果不是,则生成修正后的文章。
ToT 设置。 我们构建了一个深度为 2(且只有一个中间思维步骤)的 ToT —— LM 首先生成 个计划并投票选出最好的一个(图 4),然后类似地基于最好的计划生成 篇文章,然后投票选出最好的一个。这里广度限制 ,因为每步只保留一个选择。一个简单的零样本投票提示(“分析下面的选择,然后得出结论哪个对指令最有希望”)被用于在两个步骤中采样 5 票。
结果。 图 5(a) 显示了 100 个任务的平均 GPT-4 分数,其中 ToT (7.56) 被认为平均比 IO (6.19) 和 CoT (6.93) 生成更连贯的文章。虽然这种自动指标可能有噪声,但图 5(b) 通过显示人类在 100 个文章对中更喜欢 ToT 而不是 CoT(41 对 21,其他 38 对被发现“同样连贯”)证实了这一发现。最后,迭代修正对这项自然语言任务更有效,它将 IO 连贯性分数从 6.19 提高到 7.67,将 ToT 连贯性分数从 7.56 提高到 7.91。我们认为它可以被认为是 ToT 框架中思维生成的第三种方法,其中新思维可以从修正旧思维中产生,而不是独立同分布或顺序生成。

4.3 迷你填字游戏
在 24点游戏和创意写作中,ToT 相对较浅——最多需要 3 个思维步骤才能达到最终输出。在这里,我们探索 5x5 迷你填字游戏作为一个涉及自然语言的更难的搜索问题。同样,目标不仅仅是解决任务,因为更通用的填字游戏可以很容易地用专门的 NLP 流水线 [34] 解决,该流水线利用大规模检索而不是 LM。相反,我们旨在探索 LM 作为通用问题解决者的极限,它探索自己的思维,并以深思熟虑的推理作为启发式方法来指导自己的探索。
任务设置。 我们从 GooBix 抓取数据,其中包含 156 个 5x5 迷你填字游戏。由于我们观察到相邻游戏包含相似的线索,我们使用索引为 1, 6, ..., 91, 96 的 20 个游戏进行测试,并使用游戏 136, 141, 146, 151, 156 进行提示。对于每项任务,输入描述了 5 条水平线索和 5 条垂直线索,输出应该是 5x5 = 25 个字母的棋盘来解决填字游戏。为了评估,我们考虑三个成功级别:正确字母(每个游戏 25 个)、单词(每个游戏 10 个)和游戏的比例。
基线。 我们在 IO 提示中提供 5 个示例输入-输出对,并在 CoT 提示中额外包含按 h1..5 然后 v1..5 顺序的中间单词。我们为每个提示运行 10 个样本并取平均结果。
ToT 设置。 我们利用深度优先搜索(算法 2),它不断探索最有希望的后续单词线索,直到状态不再有希望,然后回溯到父状态以探索替代思维。为了使搜索易于处理,后续思维被限制为不改变任何已填写的单词或字母,因此 ToT 最多有 10 个中间步骤。对于思维生成,在每个状态下,我们将所有现有思维(例如图 6(a) 中状态的“h2.motor; h1.tasks”)翻译成剩余线索的字母约束(例如“v1.To heap: tm ;...”),并提示提议提示 5 次,以提出关于在哪里以及填什么下一个单词的候选者。重要的是,我们还提示 LM 为不同的思维给出置信度,并将这些跨提议聚合以获得要探索的下一个思维的排序列表(图 6(a))。对于状态评估,我们类似地将每个状态翻译成剩余线索的字母约束,然后评估每条线索在给定约束下是否可能填写。如果任何剩余线索被认为“不可能”填写(例如“v1. To heap: tm s ”),则该状态子树的探索被剪枝,DFS 回溯到其父级以探索下一个有希望的思维。我们将 DFS 搜索步骤限制为 100,并简单地将最深探索的状态(如果多个则为第一个探索的)渲染为最终输出。
| 方法 | 成功率 (%) | ||
|---|---|---|---|
| 字母 | 单词 | 游戏 | |
| IO | 38.7 | 14 | 0 |
| CoT | 40.6 | 15.6 | 1 |
| ToT (我们的) | 78 | 60 | 20 |
| +最好状态 | 82.4 | 67.5 | 35 |
| -剪枝 | 65.4 | 41.5 | 5 |
| -回溯 | 54.6 | 20 | 5 |
表 3:迷你填字游戏结果。
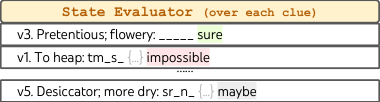
结果。 如表 3 所示,IO 和 CoT 提示方法表现不佳,单词级成功率低于 16%,而 ToT 显著提高了所有指标,达到了 60% 的单词级成功率,并解决了 20 个游戏中的 4 个。这种改进并不令人惊讶,因为 IO 和 CoT 缺乏尝试不同线索、更改决策或回溯的机制。
预言机和消融研究。 当从每个任务的预言机最佳 DFS 状态(而不是启发式确定的最佳状态)输出时,ToT 性能甚至更高,实际上解决了 7/20 个游戏(表 3,“+最好状态”),表明我们简单的输出启发式方法可以很容易地改进。有趣的是,有时当填字游戏实际上被解决时,状态评估器可能仍然认为某些单词是“不可能”的并进行剪枝——可能是因为 5x5 填字游戏设计上有一些 GPT-4 无法识别的罕见或过时单词^2。鉴于状态评估作为剪枝启发式是不完美的,我们还探索了消融剪枝,发现性能通常更差(表 3,“-剪枝”)。然而,它实际上可以为 4/20 个游戏找到正确的解决方案(尽管仅通过启发式输出 1 个),其中 3 个是 ToT+剪枝无法在 100 步内解决的游戏。因此,更好的 DFS 剪枝启发式对于这种情况下的问题解决至关重要。最后,我们通过运行一个消融实验确认了回溯的重要性,该实验保持填充最有希望的线索最多 20 步,允许覆盖。这类似于广度限制为 的“贪婪”BFS 搜索,并且表现不佳,单词级成功率仅为 20%(表 3,“-回溯”)。
5 相关工作
规划和决策。 智能规划和决策对于实现预定义目标至关重要。由于它们是在海量世界知识和人类示例上训练的,已知 LM 已经吸收了丰富的常识,使得根据问题设置和环境状态提出合理的计划成为可能 [12, 42, 37, 13, 35, 41, 40]。我们提出的 ToT 方法通过在每个问题解决步骤中同时考虑多个潜在可行的计划,并继续进行最有希望的计划,扩展了现有的规划公式。思维采样和价值反馈之间的集成有机地集成了规划和决策机制,实现了解决方案树内的有效搜索。另一方面,传统的决策过程通常需要训练专门的奖励和策略模型,如强化学习(例如 CHAI [33]),而我们使用 LM 本身来提供决策的价值估计。RAP [9] 是一项并发工作,它将语言模型推理视为具有内部世界模型的规划,并提出了类似于 ToT 的基于 MCTS 的方法。然而,它的任务比我们的简单,并且其框架缺乏结合不同树搜索算法的模块化。
自我反思。 使用 LLM 评估其自身预测的可行性正成为问题解决中越来越重要的程序。[28, 20, 24] 引入了“自我反思”机制,其中 LM 为其生成候选者提供反馈。[4] 通过注入 LM本身基于其代码执行结果生成的反馈消息,提高了 LM 的代码生成准确性。同样,[17] 也引入了针对动作和状态的“评论家”或审查步骤,决定在解决计算机操作任务时采取的下一个动作。另一项与我们非常相关的近期工作是“自我评估引导解码” [39]。与我们的方法类似,自我评估解码也遵循树搜索过程,其叶子节点是从随机束搜索解码中采样的,然后由 LLM 本身使用精心准备的自我评估提示进行评估。然而,他们的方法使用了 PAL 公式 [8],该公式将思维表示为代码,这使得处理像我们在本文中考虑的创意写作这样具有挑战性的任务变得困难。因此,我们的思维树公式更加通用,并且能够处理 GPT-4 在标准提示下仅能达到极低准确率的挑战性任务。
程序引导的 LLM 生成。 我们的提议也与最近通过系统程序 [14, 44, 6, 43] 或符号程序引导来组织 LM 行为的进展相关。例如,Schlag 等人 [27] 将 LM 嵌入到算法搜索过程中,以帮助逐步解决诸如问答之类的问题,其中搜索树通过可能提供答案的相关段落进行扩展。然而,这种方法与我们的不同之处在于,树是通过采样外部段落而不是 LM 自己的思维来扩展的,并且没有反思或投票步骤。另一种方法 LLM+P [18] 更进一步,将实际的规划过程委托给经典规划器。
经典搜索方法。 最后但同样重要的是,我们的方法可以被视为经典问题解决搜索方法的现代演绎。例如,它可以被视为一种启发式搜索算法,如 A* [10],其中每个搜索节点的启发式由 LM 的自我评估提供。从这个角度来看,我们的方法也与 NeuroLogic A* 风格解码 [19] 相关,它受到 A* 搜索的启发,但引入了对 LM 有效的前瞻启发式,以改进束搜索或 top-k 采样解码。然而,这种方法仅限于句子生成任务,而我们的框架旨在解决由价值反馈引导的复杂、多步骤问题。
6 讨论
局限性和未来方向。 对于 GPT-4 已经擅长的许多现有任务,像 ToT 这样的深思熟虑搜索可能是不必要的(参见附录 B.1),并且作为初步步骤,这项工作仅探索了三个挑战 GPT-4 的相对简单的任务(参见附录 B.2 中一些 GPT-3.5 的实验结果),并呼吁将更好的搜索和规划能力纳入 LM。然而,随着我们开始将 LM 部署到更多现实世界的决策应用中(例如编码、数据分析、机器人技术等),更复杂的任务可能会出现,并为研究这些研究问题提供新的机会。此外,像 ToT 这样的搜索方法比采样方法需要更多的资源(例如 GPT-4 API 成本)来提高任务性能,但 ToT 的模块化灵活性允许用户自定义这种性能-成本权衡,并且正在进行的开源工作 [32] 应该能在不久的将来轻松降低此类成本。关于成本和效率的更多细节在附录 B.3 中。最后,这项工作专注于使用现成的 LM,而使用 ToT 风格的高级反事实决策(例如,对下一段的潜在选择进行审议,而不是预测下一个标记)对 LM 进行微调,可能会提供增强 LM 问题解决能力的机会。
结论。 LM 的联想式“系统 1”可以通过基于搜索问题解决方案路径树的“系统 2”得到有益的增强。思维树框架提供了一种将关于问题解决的经典见解转化为当代 LM 可操作方法的方式。同时,LM 解决了这些经典方法的一个弱点,提供了一种解决不易形式化的复杂问题的方法,例如创意写作。我们将这种 LM 与经典 AI 方法的交叉视为一个令人兴奋的方向。
广阔影响
ToT 是一个赋予 LM 更自主、更智能地做出决策和解决问题的框架。虽然目前的任务仅限于推理和搜索问题,但涉及与外部环境或人类交互的未来应用可能会带来潜在危险,例如促进 LM 的有害使用。另一方面,ToT 也提高了模型决策的可解释性和人类对齐的机会,因为生成的表示是可读的高级语言推理,而不是隐式的低级标记值。
致谢
SY 和 KN 感谢 Oracle 协作研究奖和国家科学基金会(Grant No. 2239363)的支持。本材料中表达的任何观点、发现、结论或建议均为作者的观点,不一定反映国家科学基金会的观点。SY 还得到普林斯顿大学 Harold W. Dodds 奖学金的支持。
参考文献
[1] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, 等。Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
[2] C. Browne, E. J. Powley, D. Whitehouse, S. M. M. Lucas, P. I. Cowling, P. Rohlfshagen, S. Tavener, D. P. Liebana, S. Samothrakis, 和 S. Colton。A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in Games, 4:1–43, 2012.
[3] M. Campbell, A. J. Hoane Jr, 和 F.-h. Hsu。Deep blue. Artificial intelligence, 134(1-2):57–83, 2002.
[4] X. Chen, M. Lin, N. Scharli, 和 D. Zhou。Teaching large language models to self-debug, 2023.
[5] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, 等。Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
[6] A. Creswell 和 M. Shanahan。Faithful reasoning using large language models. arXiv preprint arXiv:2208.14271, 2022.
[7] N. D. Daw, Y. Niv, 和 P. Dayan。Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nature neuroscience, 8(12):1704–1711, 2005.
[8] L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, 和 G. Neubig。Pal: Program aided language models, 2023.
[9] S. Hao, Y. Gu, H. Ma, J. J. Hong, Z. Wang, D. Z. Wang, 和 Z. Hu。Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992, 2023.
[10] P. E. Hart, N. J. Nilsson, 和 B. Raphael。A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Science and Cybernetics, 4(2):100–107, 1968. doi: 10.1109/TSSC.1968.300136.
[11] P. E. Hart, N. J. Nilsson, 和 B. Raphael。A formal basis for the heuristic determination of minimum cost paths. IEEE transactions on Systems Science and Cybernetics, 4(2):100–107, 1968.
[12] W. Huang, P. Abbeel, D. Pathak, 和 I. Mordatch。Language models as zero-shot planners: Extracting actionable knowledge for embodied agents, 2022.
[13] W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar, 等。Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608, 2022.
[14] J. Jung, L. Qin, S. Welleck, F. Brahman, C. Bhagavatula, R. L. Bras, 和 Y. Choi。Maieutic prompting: Logically consistent reasoning with recursive explanations. arXiv preprint arXiv:2205.11822, 2022.
[15] D. Kahneman。Thinking, fast and slow. Macmillan, 2011.
[16] D. Kahneman, S. Frederick, 等。Representativeness revisited: Attribute substitution in intuitive judgment. Heuristics and biases: The psychology of intuitive judgment, 49(49-81):74, 2002.
[17] G. Kim, P. Baldi, 和 S. McAleer。Language models can solve computer tasks, 2023.
[18] B. Liu, Y. Jiang, X. Zhang, Q. Liu, S. Zhang, J. Biswas, 和 P. Stone。Llm+p: Empowering large language models with optimal planning proficiency, 2023.
[19] X. Lu, S. Welleck, P. West, L. Jiang, J. Kasai, D. Khashabi, R. L. Bras, L. Qin, Y. Yu, R. Zellers, N. A. Smith, 和 Y. Choi。Neurologic a*esque decoding: Constrained text generation with lookahead heuristics. In North American Chapter of the Association for Computational Linguistics, 2021.
[20] A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Welleck, B. P. Majumder, S. Gupta, A. Yazdanbakhsh, 和 P. Clark。Self-refine: Iterative refinement with self-feedback, 2023.
[21] A. Newell, J. C. Shaw, 和 H. A. Simon。Report on a general problem solving program. In IFIP congress, volume 256, page 64. Pittsburgh, PA, 1959.
[22] A. Newell, H. A. Simon, 等。Human problem solving. Prentice-Hall, 1972.
[23] OpenAI。Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
[24] D. Paul, M. Ismayilzada, M. Peyrard, B. Borges, A. Bosselut, R. West, 和 B. Faltings。Refiner: Reasoning feedback on intermediate representations, 2023.
[25] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever, 等。Improving language understanding by generative pre-training. OpenAI blog, 2018.
[26] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, 等。Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
[27] I. Schlag, S. Sukhbaatar, A. Celikyilmaz, W. tau Yih, J. Weston, J. Schmidhuber, 和 X. Li。Large language model programs, 2023.
[28] N. Shinn, B. Labash, 和 A. Gopinath。Reflexion: an autonomous agent with dynamic memory and self-reflection, 2023.
[29] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, 等。Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017.
[30] S. A. Sloman。The empirical case for two systems of reasoning. Psychological bulletin, 119(1):3, 1996.
[31] K. E. Stanovich。Who is rational? Studies of individual differences in reasoning. Psychology Press, 1999.
[32] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Roziere, N. Goyal, E. Hambro, F. Azhar, 等。Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[33] S. Verma, J. Fu, S. Yang, 和 S. Levine。Chai: A chatbot ai for task-oriented dialogue with offline reinforcement learning. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4471–4491, 2022.
[34] E. Wallace, N. Tomlin, A. Xu, K. Yang, E. Pathak, M. Ginsberg, 和 D. Klein。Automated crossword solving. arXiv preprint arXiv:2205.09665, 2022.
[35] L. Wang, W. Xu, Y. Lan, Z. Hu, Y. Lan, R. K.-W. Lee, 和 E.-P. Lim。Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models, 2023.
[36] X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, 和 D. Zhou。Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
[37] Z. Wang, S. Cai, A. Liu, X. Ma, 和 Y. Liang。Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents, 2023.
[38] J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. Chi, Q. Le, 和 D. Zhou。Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.
[39] Y. Xie, K. Kawaguchi, Y. Zhao, X. Zhao, M.-Y. Kan, J. He, 和 Q. Xie。Decomposition enhances reasoning via self-evaluation guided decoding, 2023.
[40] S. Yang, O. Nachum, Y. Du, J. Wei, P. Abbeel, 和 D. Schuurmans。Foundation models for decision making: Problems, methods, and opportunities, 2023.
[41] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, 和 Y. Cao。ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
[42] S. Zhang, Z. Chen, Y. Shen, M. Ding, J. B. Tenenbaum, 和 C. Gan。Planning with large language models for code generation. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=Lr8cOOtYbfL.
[43] D. Zhou, N. Scharli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le, 等。Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.
[44] X. Zhu, J. Wang, L. Zhang, Y. Zhang, R. Gan, J. Zhang, 和 Y. Yang。Solving math word problem via cooperative reasoning induced language models. arXiv preprint arXiv:2210.16257, 2022.
A 代码、提示词、轨迹
所有代码均可在 https://github.com/princeton-nlp/tree-of-thought-llm 获取。 所有提示词均可在 https://github.com/princeton-nlp/tree-of-thought-llm/tree/master/src/tot/prompts 获取。 轨迹均可在 https://github.com/princeton-nlp/tree-of-thought-llm/tree/master/logs 获取。
B 额外实验结果
鉴于探索和扩展语言模型能力边界的动机,我们在主论文中的实验集中于使用最先进的语言模型 (GPT-4) 以及为挑战它而发明的三项困难任务的设置。在这里,我们报告了使用较弱 LLM 或较简单任务的额外实验,并讨论了成本和效率。
| GSM8K | StrategyQA | |
|---|---|---|
| IO | 51 | 73 |
| CoT | 86 | 82 |
| ToT | 90 | 83 |
表 4:使用零样本 ToT 和 GPT-4 的新任务。
| GPT-4 | GPT-3.5 | |
|---|---|---|
| IO | 7.3% | 6% |
| CoT | 4.0% | 3% |
| ToT | 74% | 19% |
表 5:GPT-4 与 GPT-3.5 的 24点游戏对比。
| GPT-4 | GPT-3.5 | |
|---|---|---|
| IO | 6.19 | 4.47 |
| CoT | 6.93 | 5.16 |
| ToT | 7.56 | 6.62 |
表 6:GPT-4 与 GPT-3.5 的创意写作对比。
B.1 使用零样本 ToT 扩展到新任务 (GSM8k, StrategyQA)
虽然更常见的 NLP 任务对 GPT-4 来说可能太简单,不需要 ToT(这就是我们考虑更困难的新任务的原因),但我们相信将 ToT 应用于新任务可能是直接的。例如,我们实现了一个类似于创意写作的简单且通用的零样本 ToT-BFS(采样 5 个问题解决策略,然后投票选出最好的一个;然后基于最好的策略采样 5 个解决方案,然后投票选出最好的一个),用于 GSM8K 和 StrategyQA,只需几行额外的代码:
python# 定义新任务的答案格式 gsm8k_format = '"the answer is n" where n is a number' strategyqa_format = 'either "the answer is yes" or "the answer is no"' # 定义零样本 io 提示 standard_prompt = 'Answer the following question with {format}: {input}' # 定义零样本 cot 和零样本 tot 的思维格式 cot_prompt = '''Answer the following question: {input} Make a strategy then write. Your output should be of the following format: Strategy: Your strategy about how to answer the question. Answer: Your answer to the question. It should end with {format}. ''' # 定义用于零样本 tot 的零样本投票 vote_prompt = '''Given an instruction and several choices, decide which choice is most promising. Analyze each choice in detail, then conclude in the last line "The best choice is {s}", where s the integer id of the choice. '''
我们在 100 个随机 GSM8K 测试和 StrategyQA 开发问题子集上进行了评估。如表 4 所示,正如预期的那样,ToT 在两项任务上都比 CoT 有所改进(但改进幅度较小,因为 GPT-4 + CoT 在此类任务上已经非常出色,且 StrategyQA 的瓶颈是外部知识,而不是推理)。考虑到计算成本,尝试较小的 LLM + ToT 用于传统 NLP 任务,或 GPT-4 + ToT 用于挑战 GPT-4 + CoT 推理的困难任务更为合适。
B.2 扩展到新 LM (GPT-3.5)
为了了解 ToT 如何与其他 LLM 一起工作,我们还运行了 GPT-3.5-turbo 进行创意写作(表 6)和 24点游戏(表 5)。在这两项任务上,“ToT > CoT > IO”对于 GPT-3.5 仍然成立。在创意写作上,我们发现 GPT-3.5+ToT 优于 GPT-4+IO,并且与 GPT-4+CoT 相似,这表明 ToT 在较弱的语言模型上也可能工作得很好。
在 24点游戏上(我们将 1-shot 提议提示更改为 3-shot 以使其工作),GPT-3.5+ToT 的 19% 远差于 GPT-4+ToT 的 74%。为了进一步了解生成与评估的重要性,我们运行了 GPT-4 生成 + GPT-3.5 评估 (64%) 和 GPT-3.5 生成 + GPT-4 评估 (31%)。这表明该游戏的瓶颈是思维生成,不同的生成/评估语言模型可能在降低成本的同时获得不错的结果。
B.3 成本和效率
运行 ToT 需要比 IO 或 CoT 提示更多的计算。例如,在 24点游戏(下表 7)中,用 ToT 解决一个问题需要 5.5k 个完成标记,接近 100 个 CoT 试验(6.7k 个标记)。但 ToT 的性能优于 100 个独立 CoT 试验中最好的一个。
| 24点游戏 | 生成/提示标记 | 每个案例成本 | 成功率 |
|---|---|---|---|
| IO (100 次中最好) | 1.8k / 1.0k | $0.13 | 33% |
| CoT (100 次中最好) | 6.7k / 2.2k | $0.47 | 49% |
| ToT | 5.5k / 1.4k | $0.74 | 74% |
表 7:24点游戏成本分析。
在创意写作(下表 8)上,我们发现 ToT 需要大约 5 倍的完成标记和金钱成本,这是直观的,因为 且大多数标记是生成的文章。
| 创意写作 | 生成/提示标记 | 每个案例成本 |
|---|---|---|
| IO | 0.9k / 0.4k | $0.06 |
| CoT | 0.9k / 0.4k | $0.07 |
| ToT | 4k / 2.9k | $0.32 |
表 8:24点游戏成本分析。
因此,完成 24点游戏和创意写作的主要 ToT 实验花费了大约 美元。填字游戏的 DFS 实验也应该在 100 美元以内。通常,ToT 的成本和效率高度依赖于所使用的提示和搜索算法,并且可能需要比 CoT 多 5-100 倍的生成标记。一些可操作的见解:
- 我们建议在需要深思熟虑推理的任务上使用 ToT,CoT 在这些任务上表现挣扎。
- ToT 的灵活性允许一些性能-成本权衡,例如,在 BFS 中更改束大小或投票数量,少样本与零样本提示,GPT-3.5 与 GPT-4 等。可以根据某些资源限制或性能目标配置设置。
- 提高效率的空间很大,例如,BFS 可以在找到解决方案时提前停止,或者在某些思维被认为是“不可能”时缩减束大小。
- 我们相信,为了让模型实现更强的智能,确实需要更多的计算,这不应成为长期的阻碍问题,因为(开源)LM 将变得更便宜、更高效。如何更好地训练/微调 LM 以进行思维生成和/或评估也是一个很好的方向。