ReAct:在语言模型中协同推理与行动
Shunyu Yao*, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao
普林斯顿大学计算机科学系 Google Research, Brain 团队 {shunyuy, karthikn}@princeton.edu {jeffreyzhao, dianyu, dunan, izhak, yuancao}@google.com
摘要
尽管大型语言模型(LLMs)在语言理解和交互式决策任务中表现出了令人印象深刻的性能,但它们在推理(例如思维链提示)和行动(例如生成行动计划)方面的能力主要被作为独立的主题进行研究。在本文中,我们探索了使用 LLMs 以交替方式生成推理轨迹和特定任务行动的方法,从而使两者之间产生更大的协同效应:推理轨迹帮助模型归纳、跟踪和更新行动计划以及处理异常,而行动则允许模型与外部源(如知识库或环境)进行交互并收集额外信息。我们将这种名为 ReAct 的方法应用于一系列不同的语言和决策任务,并证明了其相对于最先进基线方法的有效性,此外还提高了人类的可解释性和可信度。具体而言,在问答(HotpotQA)和事实核查(Fever)任务中,ReAct 通过与简单的 Wikipedia API 交互,克服了思维链推理中普遍存在的幻觉和错误传播问题,并生成了比没有推理轨迹的基线更具可解释性的人类化任务解决轨迹。此外,在两个交互式决策基准(ALFWorld 和 WebShop)上,ReAct 在仅使用一两个上下文示例进行提示的情况下,其绝对成功率分别超过了模仿学习和强化学习方法 34% 和 10%。
1 引言
人类智能的一个独特特征是能够将面向任务的行动与语言推理(或内心独白,Alderson-Day & Fernyhough, 2015)无缝结合,这在人类认知中被认为在实现自我调节或策略制定(Vygotsky, 1987; Luria, 1965; Fernyhough, 2010)以及维持工作记忆(Baddeley, 1992)方面发挥着重要作用。考虑在厨房做菜的例子。在任何两个具体行动之间,我们可能会用语言进行推理,以跟踪进度(“既然所有东西都切好了,我应该把水烧开”),处理异常或根据情况调整计划(“我没有盐,所以我用酱油和胡椒代替”),并意识到何时需要外部信息(“我该如何准备面团?让我上网查一下”)。我们也可以采取行动(打开食谱阅读配方,打开冰箱,检查配料)来支持推理并回答问题(“我现在能做什么菜?”)。这种“行动”与“推理”之间的紧密协同作用,使人类能够快速学习新任务,并在即使是以前未见过的情况下或面临信息不确定性时,执行稳健的决策或推理。
最近的研究结果暗示了在自主系统中将语言推理与交互式决策相结合的可能性。一方面,经过适当提示的大型语言模型(LLMs)已经展示了执行多个推理步骤以从算术、常识和符号推理任务中得出答案的涌现能力(Wei et al., 2022)。然而,这种“思维链”推理是一个静态的黑盒,模型使用其自身的内部表示来生成思想,并且没有扎根于外部世界,这限制了其反应性推理或更新知识的能力。这可能导致推理过程中出现事实幻觉和错误传播等问题(图 1 (1b))。另一方面,最近的工作探索了使用预训练语言模型在交互式环境中进行规划和行动(Ahn et al., 2022; Nakano et al., 2021; Yao et al., 2020; Huang et al., 2022a),重点是通过语言先验预测行动。这些方法通常将多模态观察转换为文本,使用语言模型生成特定领域的行动或计划,然后使用控制器来选择或执行它们。然而,它们不使用语言模型来抽象地推理高层目标或维持工作记忆以支持行动,除了 Huang et al. (2022b) 执行了有限形式的语言推理来重申关于当前状态的空间事实。除了这种与少量方块交互的简单具身任务外,目前还没有关于如何将推理和行动以协同方式结合起来进行通用任务解决的研究,以及这种结合是否能带来比单独推理或行动更系统的益处。
在本文中,我们提出了 ReAct,这是一种通用的范式,旨在将推理和行动与语言模型相结合,以解决各种语言推理和决策任务(图 1)。ReAct 提示 LLMs 以交替方式生成推理轨迹和与任务相关的行动,这允许模型执行动态推理来创建、维护和调整用于行动的高层计划(推理以行动),同时也与外部环境(例如 Wikipedia)交互,将额外信息纳入推理(行动以推理)。
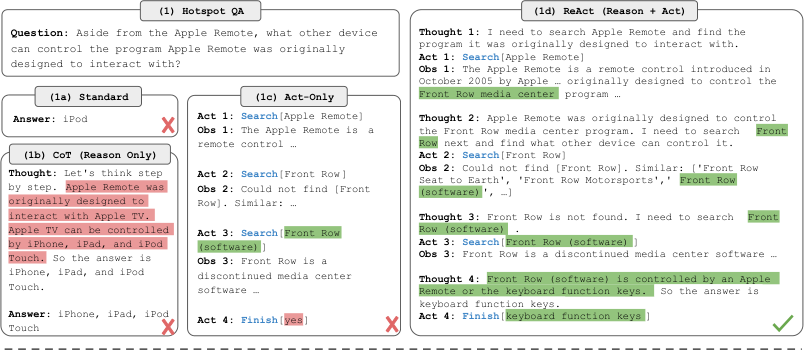
我们对 ReAct 和最先进的基线在四个不同的基准上进行了实证评估:问答(HotPotQA, Yang et al., 2018)、事实核查(Fever, Thorne et al., 2018)、基于文本的游戏(ALFWorld, Shridhar et al., 2020b)和网页导航(WebShop, Yao et al., 2022)。对于 HotPotQA 和 Fever,通过访问模型可以交互的 Wikipedia API,ReAct 在优于普通行动生成模型的同时,与思维链推理(CoT)(Wei et al., 2022)具有竞争力。总体上最好的方法是 ReAct 和 CoT 的结合,它允许在推理过程中同时使用内部知识和外部获取的信息。在 ALFWorld 和 WebShop 上,两次甚至一次的 ReAct 提示能够优于使用 个任务实例训练的模仿或强化学习方法,成功率分别绝对提高了 34% 和 10%。我们还通过显示相对于仅有行动的受控基线的持续优势,证明了稀疏、多功能推理在决策中的重要性。除了通用性和性能提升外,推理和行动的结合还有助于提高所有领域模型的可解释性、可信度和可诊断性,因为人类可以很容易地分辨出哪些信息来自模型的内部知识,哪些来自外部环境,并检查推理轨迹以理解模型行动的决策基础。
总结来说,我们的主要贡献如下:(1) 我们引入了 ReAct,这是一种新颖的基于提示的范式,用于在语言模型中协同推理和行动以进行通用任务解决;(2) 我们在不同的基准上进行了广泛的实验,以展示 ReAct 在少样本学习设置中相对于先前孤立地执行推理或行动生成的方法的优势;(3) 我们提出了系统的消融和分析,以理解行动在推理任务中的重要性,以及推理在交互式任务中的重要性;(4) 我们分析了 ReAct 在提示设置下的局限性(即对推理和行动行为的有限支持),并进行了初步的微调实验,显示了 ReAct 通过额外训练数据进行改进的潜力。将 ReAct 扩展到在更多任务上进行训练,并将其与强化学习等互补范式相结合,可以进一步释放大型语言模型的潜力。
2 ReAct:协同推理 + 行动
考虑一个代理与环境交互以解决任务的通用设置。在时间步 ,代理从环境中接收观察 ,并遵循某种策略 采取行动 ,其中 是代理的上下文。当映射 是高度隐式的并且需要大量计算时,学习策略是具有挑战性的。例如,图 1(1c) 中显示的代理无法生成正确的最终行动(行动 4)来完成 QA 任务,因为它需要对轨迹上下文(问题,行动 1-3,观察 1-3)进行复杂的推理。同样,图 1(2a) 中显示的代理无法从上下文中理解 sinkbasin 1 不包含 peppershaker 1,因此不断产生幻觉行动。
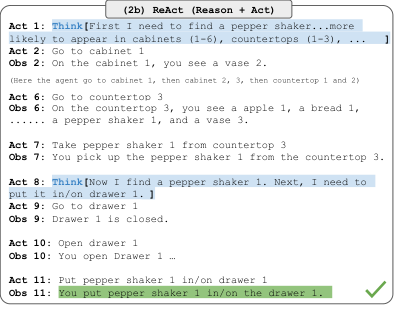
ReAct 的想法很简单:我们将代理的行动空间扩充为 ,其中 是语言空间。语言空间中的行动 (我们将称之为思想或推理轨迹)不会影响外部环境,因此不会导致观察反馈。相反,思想 旨在通过对当前上下文 进行推理来组合有用的信息,并更新上下文 以支持未来的推理或行动。如图 1 所示,可以有各种类型的有用思想,例如分解任务目标并创建行动计划(2b,行动 1;1d,思想 1),注入与任务解决相关的常识知识(2b,行动 1),从观察中提取重要部分(1d,思想 2, 4),跟踪进度并转换行动计划(2b,行动 8),处理异常并调整行动计划(1d,思想 3),等等。
然而,由于语言空间 是无限的,在这个扩充的行动空间中学习是困难的,并且需要强大的语言先验。在本文中,我们主要关注冻结的大型语言模型 PaLM-540B (Chowdhery et al., 2022) 被提示使用少样本上下文示例来生成特定领域的行动和自由形式的语言思想以进行任务解决(图 1 (1d), (2b))的设置。每个上下文示例都是一个人类轨迹,包含行动、思想和环境观察,用于解决一个任务实例(见附录 C)。对于推理至关重要的任务(图 1(1)),我们交替生成思想和行动,以便任务解决轨迹由多个思想-行动-观察步骤组成。相比之下,对于可能涉及大量行动的决策任务(图 1(2)),思想只需要稀疏地出现在轨迹中最相关的部分,因此我们让语言模型自行决定思想和行动的异步发生。
由于决策和推理能力集成在大型语言模型中,ReAct 具有几个独特的特征:A) 直观且易于设计:设计 ReAct 提示非常简单,因为人类标注者只需在他们采取的行动之上用语言输入他们的想法。本文中没有使用特定的格式选择、思想设计或示例选择。我们在第 3 节和第 4 节中详细介绍了每个任务的提示设计。B) 通用且灵活:由于灵活的思想空间和思想-行动发生格式,ReAct 适用于具有不同行动空间和推理需求的多样化任务,包括但不限于 QA、事实核查、文本游戏和网页导航。C) 高性能且稳健:ReAct 在仅从一到六个上下文示例中学习时,表现出对新任务实例的强大泛化能力,在不同领域中始终优于仅有推理或仅有行动的基线。我们还在第 3 节中展示了启用微调时的额外好处,并在第 4 节中展示了 ReAct 性能如何对提示选择保持稳健。D) 人类对齐且可控:ReAct 承诺了一个可解释的顺序决策和推理过程,人类可以轻松检查推理和事实正确性。此外,人类还可以通过思想编辑在运行中控制或纠正代理行为,如图 5 第 4 节所示。
3 知识密集型推理任务
我们从多跳问答和事实核查等知识密集型推理任务开始。如图 1(1d) 所示,通过与 Wikipedia API 交互,ReAct 能够检索信息以支持推理,同时也使用推理来确定下一步要检索的内容,展示了推理和行动的协同作用。
3.1 设置
领域 我们考虑两个具有挑战性的知识检索和推理数据集:(1) HotPotQA (Yang et al., 2018),一个多跳问答基准,需要对两个或多个 Wikipedia 段落进行推理,以及 (2) FEVER (Thorne et al., 2018),一个事实核查基准,其中每个声明都被标注为 SUPPORTS、REFUTES 或 NOT ENOUGH INFO,基于是否存在 Wikipedia 段落来验证该声明。在本文中,我们在这两个任务中都采用仅问题的设置,其中模型仅接收问题/声明作为输入,而无法访问支持段落,并且必须依赖其内部知识或通过与外部环境交互来检索知识以支持推理。
行动空间 我们设计了一个简单的 Wikipedia 网络 API,具有三种类型的行动来支持交互式信息检索:(1) search[entity],如果存在,则返回相应实体维基页面的前 5 句,否则从 Wikipedia 搜索引擎建议前 5 个相似实体;(2) lookup[string],将返回页面中包含 string 的下一句,模拟浏览器上的 Ctrl+F 功能;(3) finish[answer],将以 answer 完成当前任务。我们注意到,这个行动空间大多只能基于确切的段落名称检索段落的一小部分,这明显弱于最先进的词法或神经检索器。其目的是模拟人类如何与 Wikipedia 交互,并强制模型通过语言中的显式推理进行检索。
3.2 方法
ReAct 提示 对于 HotpotQA 和 Fever,我们从训练集中随机选择 6 个和 3 个案例,并手动编写 ReAct 格式的轨迹,用作提示中的少样本示例。与图 1(d) 类似,每个轨迹由多个思想-行动-观察步骤(即密集思想)组成,其中自由形式的思想用于各种目的。具体来说,我们使用思想的组合来分解问题(“我需要搜索 x,找到 y,然后找到 z”),从 Wikipedia 观察中提取信息(“x 开始于 1844 年”,“段落没有告诉 x”),执行常识(“x 不是 y,所以 z 必须是……”)或算术推理(“1844 < 1989”),指导搜索重构(“也许我可以搜索/查找 x 代替”),并合成最终答案(“……所以答案是 x”)。有关更多详细信息,请参阅附录 C。
基线 我们系统地消融 ReAct 轨迹以构建多个基线的提示(格式如图 1(1a-1c)):(a) 标准提示(Standard),它删除了 ReAct 轨迹中的所有思想、行动、观察。(b) 思维链提示(CoT)(Wei et al., 2022),它删除了行动和观察,并作为仅推理的基线。我们还通过在推理过程中使用解码温度 0.7 对 21 个 CoT 轨迹进行采样并采用多数答案,构建了一个自洽基线(CoT-SC)(Wang et al., 2022a;b),这被发现始终能提高相对于 CoT 的性能。(c) 仅行动提示(Act),它删除了 ReAct 轨迹中的思想,松散地类似于 WebGPT (Nakano et al., 2021) 如何与互联网交互以回答问题,尽管它在不同的任务和行动空间上运行,并使用模仿和强化学习而不是提示。
结合内部和外部知识 正如第 3.3 节将详细说明的那样,我们观察到 ReAct 展示的问题解决过程更具事实性和扎根性,而 CoT 在制定推理结构方面更准确,但很容易受到幻觉事实或思想的影响。因此,我们建议结合 ReAct 和 CoT-SC,并让模型根据以下启发式方法决定何时切换到另一种方法:A) ReAct CoT-SC:当 ReAct 在给定步骤内未能返回答案时,退回到 CoT-SC。我们为 HotpotQA 和 FEVER 分别设置了 7 步和 5 步,因为我们发现更多的步骤不会提高 ReAct 性能。B) CoT-SC ReAct:当 个 CoT-SC 样本中的多数答案出现次数少于 次时(即内部知识可能无法自信地支持任务),退回到 ReAct。
微调 由于大规模手动标注推理轨迹和行动的挑战,我们考虑了一种类似于 Zelikman et al. (2022) 的引导方法,使用 3,000 个由 ReAct 生成正确答案的轨迹(也用于其他基线)来微调较小的语言模型(PaLM-8/62B),以解码以输入问题/声明为条件的轨迹(所有思想、行动、观察)。更多详细信息在附录 B.1 中。
3.3 结果和观察
ReAct 始终优于 Act 表 1 显示了使用 PaLM-540B 作为基础模型,采用不同提示方法的 HotpotQA 和 Fever 结果。我们注意到 ReAct 在两项任务上都优于 Act,证明了推理对指导行动的价值,特别是对于合成最终答案,如图 1 (1c-d) 所示。微调结果也证实了推理轨迹对于更明智的行动的好处。
| 提示方法 | HotpotQA (EM) | Fever (Acc) |
|---|---|---|
| Standard | 28.7 | 57.1 |
| CoT (Wei et al., 2022) | 29.4 | 56.3 |
| CoT-SC (Wang et al., 2022a) | 33.4 | 60.4 |
| Act | 25.7 | 58.9 |
| ReAct | 27.4 | 60.9 |
| CoT-SC ReAct | 34.2 | 64.6 |
| ReAct CoT-SC | 35.1 | 62.0 |
| Supervised SoTA | 67.5 | 89.5 |
表 1:PaLM-540B 在 HotpotQA 和 Fever 上的提示结果。 HotpotQA EM 在 Wang et al. (2022b) 中分别为 Standard, CoT, CoT-SC 的 27.1, 28.9, 33.8。 (Zhu et al., 2021; Lewis et al., 2020)

4 决策任务
我们还在两个基于语言的交互式决策任务上测试了 ReAct,ALFWorld 和 WebShop,这两个任务都具有复杂的环境,需要代理在长视界内采取行动并获得稀疏奖励,从而需要推理来有效地行动和探索。
ALFWorld ALFWorld (Shridhar et al., 2020b)(图 1(2))是一个合成的基于文本的游戏,旨在与具身 ALFRED 基准 (Shridhar et al., 2020a) 对齐。它包括 6 种任务,其中代理需要通过文本行动(例如 go to coffeetable 1, take paper 2, use desklamp 1)导航和与模拟家庭交互来达到高层目标(例如 examine paper under desklamp)。一个任务实例可以有超过 50 个位置,并且需要专家策略超过 50 个步骤来解决,因此挑战代理规划和跟踪子目标,以及系统地探索(例如一个接一个地检查所有桌子以寻找台灯)。特别是,ALFWorld 中内置的一个挑战是需要确定常见家庭用品的可能位置(例如台灯很可能在桌子、架子或梳妆台上),这使得该环境非常适合 LLMs 利用其预训练的常识知识。为了提示 ReAct,我们为每种任务类型从训练集中随机标注了三个轨迹,其中每个轨迹包括稀疏的思想,这些思想 (1) 分解目标,(2) 跟踪子目标完成情况,(3) 确定下一个子目标,以及 (4) 通过常识推理在哪里找到物体以及如何处理它。我们在附录 C.4 中展示了用于 ALFWorld 的提示。遵循 Shridhar et al. (2020b),我们在任务特定设置中对 134 个未见过的评估游戏进行了评估。为了稳健性,我们通过我们标注的 3 个轨迹中的 2 个的每种排列,为每种任务类型构建了 6 个提示。Act 提示是使用相同的轨迹构建的,但没有思想——由于任务实例是从训练集中随机选择的,它既不偏向 ReAct 也不偏向 Act,并提供了一个公平和受控的比较来测试稀疏思想的重要性。对于基线,我们使用 BUTLER (Shridhar et al., 2020b),这是一个为每种任务类型训练了 个专家轨迹的模仿学习代理。
WebShop ReAct 能否也与嘈杂的现实世界语言环境交互以用于实际应用?我们调查了 WebShop (Yao et al., 2022),这是一个最近提出的在线购物网站环境,拥有 118 万个现实世界产品和 1.2 万条人类指令。与 ALFWorld 不同,WebShop 包含多种结构化和非结构化文本(例如从亚马逊抓取的产品标题、描述和选项),并要求代理根据用户指令(例如“我正在寻找一个带抽屉的床头柜。它应该有镍饰面,价格低于 140 美元”)通过网络交互(例如搜索“nightstand drawers”,选择按钮如“color: modern-nickel-white”或“back to search”)购买产品。该任务通过平均得分(所选产品覆盖的期望属性的百分比,在所有剧集中平均)和成功率(所选产品满足所有要求的剧集百分比)在 500 个测试指令上进行评估。我们制定了带有搜索、选择产品、选择选项和购买行动的 Act 提示,而 ReAct 提示则额外进行推理以确定探索什么、何时购买以及哪些产品选项与指令相关。有关示例提示,请参阅附录中的表 6,有关模型预测,请参阅表 10。我们将其与模仿学习 (IL) 方法进行了比较,该方法使用 1,012 个由人类标注的轨迹进行训练,以及一个额外使用 10,587 条训练指令训练的模仿 + 强化学习 (IL + RL) 方法。
| 方法 | Pick | Clean | Heat | Cool | Look | Pick 2 | All |
|---|---|---|---|---|---|---|---|
| Act (best of 6) | 88 | 42 | 74 | 67 | 72 | 41 | 45 |
| ReAct (avg) | 65 | 39 | 83 | 76 | 55 | 24 | 57 |
| ReAct (best of 6) | 92 | 58 | 96 | 86 | 78 | 41 | 71 |
| ReAct-IM (avg) | 55 | 59 | 60 | 55 | 23 | 24 | 48 |
| ReAct-IM (best of 6) | 62 | 68 | 87 | 57 | 39 | 33 | 53 |
| BUTLER (best of 8) | 33 | 26 | 70 | 76 | 17 | 12 | 22 |
| BUTLER (best of 8) | 46 | 39 | 74 | 100 | 22 | 24 | 37 |
表 3:AlfWorld 任务特定成功率 (%)。BUTLER 和 BUTLER 结果来自 Shridhar et al. (2020b) 的表 4。所有方法都使用贪婪解码,除了 BUTLER 使用束搜索。
| 方法 | Score | SR |
|---|---|---|
| Act | 62.3 | 30.1 |
| ReAct | 66.6 | 40.0 |
| IL | 59.9 | 29.1 |
| IL+RL | 62.4 | 28.7 |
| Human Expert | 82.1 | 59.6 |
表 4:WebShop 上的得分和成功率 (SR)。IL/IL+RL 取自 Yao et al. (2022)。
5 相关工作
用于推理的语言模型 也许最著名的使用 LLMs 进行推理的工作是思维链(CoT)(Wei et al., 2022),它揭示了 LLMs 制定自己的“思维过程”进行问题解决的能力。此后进行了几项后续工作,包括用于解决复杂任务的从少到多提示(Zhou et al., 2022)、零样本 CoT (Kojima et al., 2022) 以及自洽推理 (Wang et al., 2022a)。最近,(Madaan & Yazdanbakhsh, 2022) 系统地研究了 CoT 的制定和结构,并观察到符号、模式和文本的存在对于 CoT 的有效性至关重要。其他工作也扩展到了超越简单提示的更复杂的推理架构。例如,选择-推理 (Creswell et al., 2022) 将推理过程分为“选择”和“推理”两个步骤。STaR (Zelikman et al., 2022) 通过在模型自身生成的正确理由上微调模型来引导推理过程。忠实推理 (Creswell & Shanahan, 2022) 将多步推理分解为三个步骤,每个步骤由一个专门的 LM 执行。类似的方法如 Scratchpad (Nye et al., 2021),它在中间计算步骤上微调 LM,也证明了在多步计算问题上的改进。与这些方法相比,ReAct 执行的不仅仅是孤立的、固定的推理,并将模型行动及其相应的观察整合到一个连贯的输入流中,供模型更准确地推理并解决超越推理的任务(例如交互式决策)。
用于决策的语言模型 LLMs 的强大能力使它们能够执行超越语言生成的任务,并且将 LLMs 作为决策策略模型变得越来越流行,特别是在交互式环境中。WebGPT (Nakano et al., 2021) 使用 LM 与网络浏览器交互,浏览网页,并从 ELI5 (Fan et al., 2019) 推断复杂问题的答案。与 ReAct 相比,WebGPT 没有显式地建模思维和推理过程,而是依赖昂贵的人类反馈进行强化学习。在对话建模中,像 BlenderBot (Shuster et al., 2022b) 和 Sparrow (Glaese et al., 2022) 这样的聊天机器人以及像 SimpleTOD (Hosseini-Asl et al., 2020) 这样的任务导向对话系统也训练 LMs 来对 API 调用做出决策。与 ReAct 不同,它们也没有显式地考虑推理过程,并且也依赖昂贵的数据集和人类反馈收集来进行策略学习。相比之下,ReAct 以一种更便宜的方式学习策略,因为决策过程只需要推理过程的语言描述。
LLMs 也越来越多地被用于交互式和具身环境中的规划和决策。在这方面,与 ReAct 最相关的是 SayCan (Ahn et al., 2022) 和 Inner Monologue (Huang et al., 2022b),它们使用 LLMs 进行机器人行动规划和决策。在 SayCan 中,LLMs 被提示直接预测机器人可以采取的可能行动,然后由扎根于视觉环境的启示模型重新排序以进行最终预测。Inner Monologue 通过添加同名的“内心独白”进行了进一步改进,该独白实现为来自环境的注入反馈。据我们所知,Inner Monologue 是第一个展示这种闭环系统的工作,ReAct 正是建立在此基础上的。然而,我们认为 Inner Monologue 并不真正包含内心思想——这在第 4 节中进行了详细说明。我们还注意到,在交互式决策过程中利用语言作为语义丰富的输入已在其他设置中被证明是成功的 (Abramson et al., 2020; Karamcheti et al., 2021; Huang et al., 2022a; Li et al., 2022)。越来越明显的是,在 LLMs 的帮助下,语言作为一种基本的认知机制将在交互和决策中发挥关键作用。此外,LLMs 的进步也激发了像 Reed et al. (2022) 这样的多功能和通用代理的发展。
6 结论
我们提出了 ReAct——一种简单而有效的方法,用于在大型语言模型中协同推理和行动。通过对多跳问答、事实核查和交互式决策任务的一系列多样化实验,我们证明了 ReAct 以可解释的决策轨迹带来了卓越的性能。尽管我们的方法很简单,但具有大行动空间的复杂任务需要更多的演示才能很好地学习,这不幸地很容易超出上下文学习的输入长度限制。我们探索了 HotpotQA 上的微调方法,并取得了初步的有希望的结果,但从更多高质量的人类标注中学习将是进一步提高性能的愿望。将 ReAct 与多任务训练扩展并将其与强化学习等互补范式相结合,可能会产生更强大的代理,从而进一步释放 LLMs 的潜力以用于更多应用。
致谢
我们感谢来自 Google Brain 团队和普林斯顿 NLP 小组的许多人的支持和反馈。这项工作部分得到了国家科学基金会(Grant No. 2107048)的支持。本材料中表达的任何意见、发现和结论或建议均属于作者,并不一定反映国家科学基金会的观点。
可重复性声明
我们的主要实验是在 PaLM (Chowdhery et al., 2022) 上完成的,该模型目前还不是公开可访问的。为了提高可重复性,我们在附录 C 中包含了所有使用的提示,在附录 A.1 中包含了使用 GPT-3 (Brown et al., 2020) 的额外实验,以及相关的 GPT-3 ReAct 提示代码:https://anonymous.4open.science/r/ReAct-2268/。
伦理声明
ReAct 提示大型语言模型生成比先前方法更具人类可解释性、可诊断性和可控性的任务解决轨迹。然而,将大型语言模型与行动空间挂钩以与外部环境(例如网络、物理环境)交互具有潜在的危险,例如查找不适当或私人的信息,或在环境中采取有害的行动。我们的实验通过将交互限制在不包含私人信息的特定网站(Wikipedia 或 WebShop)来最大限度地减少此类风险,并且在行动空间设计中没有危险的行动(即模型不能真正购买 WebShop 研究基准上的产品,或编辑 Wikipedia)。我们相信研究人员在未来设计更广泛的实验之前应该意识到此类风险。
参考文献
[此处省略参考文献列表,与原文保持一致]