通往自主机器智能之路
版本 0.9.2, 2022-06-27
Yann LeCun
纽约大学库朗数学科学研究所 yann@cs.nyu.edu
Meta - 基础人工智能研究 yann@fb.com
2022年6月27日
摘要
机器如何才能像人类和动物一样高效地学习?机器如何才能学会推理和规划?机器如何才能在多个抽象层次上学习感知和行动计划的表征,从而使它们能够在多个时间跨度上进行推理、预测和规划?本立场论文提出了一种用于构建自主智能体的架构和训练范式。它结合了诸如可配置的预测性世界模型、由内在动机驱动的行为,以及通过自监督学习训练的分层联合嵌入架构等概念。
关键词: 人工智能,机器常识,认知架构,深度学习,自监督学习,能量模型,世界模型,联合嵌入架构,内在动机。
1 序言
本文并非传统意义上的技术或学术论文,而是一篇立场论文,旨在表达我对通往智能机器之路的愿景。这些机器应能像动物和人类一样学习,能够进行推理和规划,且其行为由内在目标驱动,而非由硬编码程序、外部监督或外部奖励驱动。
本文描述的许多思想(几乎全部)已被许多作者在各种背景下以各种形式提出。本文并不声称对其中任何思想拥有优先权,而是提出了一种将它们组装成一个连贯整体的方案。特别是,本文指出了未来的挑战,并列举了一些可能成功或不太可能成功的途径。
本文在撰写时尽可能少用术语,并尽可能少地使用数学先验知识,以便吸引包括神经科学、认知科学和哲学在内的广泛背景的读者,以及机器学习、机器人技术和其他工程领域的读者。我希望本文能有助于将人工智能领域中一些有时难以看出相关性的研究置于正确的背景下。
2 引言
动物和人类表现出的学习能力和对世界的理解,远远超出了当前人工智能和机器学习 (ML) 系统的能力。
青少年如何在约 20 小时的练习中学会驾驶汽车,儿童又如何通过少量的接触学会语言,这怎么可能呢?为什么大多数人类知道如何在许多从未遇到过的情况下采取行动?相比之下,为了可靠,当前的机器学习系统需要通过大量的试验进行训练,以便在训练过程中频繁遇到即使是最罕见的情况组合。尽管如此,我们最好的机器学习系统在驾驶等现实任务中,即使在输入了来自人类专家的大量监督数据、在虚拟环境中进行了数百万次强化学习试验,并且工程师为它们硬编码了数百种行为之后,仍然远未达到人类的可靠性。
答案可能在于人类和许多动物学习世界模型(关于世界如何运作的内部模型)的能力。
当今人工智能研究必须解决三个主要挑战:
-
机器如何通过观察来学习表征世界、学习预测并学习行动? 现实世界中的交互既昂贵又危险,智能体应该在没有交互的情况下(通过观察)尽可能多地了解世界,从而最大限度地减少学习特定任务所需的昂贵且危险的试验次数。
-
机器如何以与基于梯度的学习相兼容的方式进行推理和规划? 我们最好的学习方法依赖于估计和使用损失函数的梯度,这只能通过可微架构来实现,且难以与基于逻辑的符号推理相协调。
-
机器如何以分层的方式、在多个抽象层次和多个时间尺度上学习表征感知和行动计划? 人类和许多动物能够构思多级抽象,通过将复杂动作分解为低级动作序列,从而进行长期预测和长期规划。
本文提出了一种智能体架构,为这三个挑战提供了可能的解决方案。
本文的主要贡献如下:
- 一种整体的认知架构,其中所有模块都是可微的,且许多模块是可训练的(第 3 节,图 2)。
- JEPA 和分层 JEPA:一种用于预测性世界模型的非生成式架构,它学习表征的层次结构(第 4.4 和 4.6 节,图 12 和 15)。
- 一种非对比式自监督学习范式,它产生的表征既具有信息量又具有可预测性(第 4.5 节,图 13)。
- 一种将 H-JEPA 作为不确定性下分层规划的预测性世界模型基础的方法(第 4.7 节,图 16 和 17)。
心急的读者可能更愿意直接跳到上述章节和图表。
2.1 学习世界模型
人类和非人类动物似乎能够通过观察,并以任务无关、无监督的方式,通过极少量的交互,学习到关于世界如何运作的大量背景知识。可以假设,这种积累的知识可能构成通常所说的“常识”的基础。常识可以被视为世界模型的一个集合,它能告诉智能体什么是可能的、什么是合理的、什么是不可实现的。利用这样的世界模型,动物可以用极少的试验学习新技能。它们可以预测其行为的后果,可以推理、规划、探索并构思解决问题的新方案。重要的是,它们在面对未知情况时也能避免犯下危险的错误。
人类、动物和智能系统使用世界模型的思想在心理学中由来已久 (Craik, 1943)。自 20 世纪 50 年代以来,使用将世界下一状态预测为当前状态和所考虑动作的函数的前向模型,一直是最优控制中的标准程序 (Bryson and Ho, 1969),并被称为模型预测控制。在强化学习中使用可微世界模型长期以来一直被忽视,但现在正在卷土重来(例如参见 (Levine, 2021))。
汽车的自动驾驶系统可能需要数千次强化学习试验才能学会转弯时开得太快会导致糟糕的结果,并学会减速以避免打滑。相比之下,人类可以利用他们对直观物理学的深刻理解来预测此类结果,并在学习新技能时很大程度上避免致命的行为过程。
常识知识不仅允许动物预测未来的结果,还允许它们填补缺失的信息,无论是在时间上还是空间上。它允许它们产生与常识一致的感知解释。当面对模糊的感知时,常识允许动物排除与内部世界模型不一致的解释,并给予特别关注,因为这可能预示着危险的情况,也是学习更完善的世界模型的一个机会。
我认为,设计能够让机器以无监督(或自监督)方式学习世界模型,并利用这些模型进行预测、推理和规划的范式和架构,是当今人工智能和机器学习的主要挑战之一。一个主要的技术障碍是如何设计能够处理预测中复杂不确定性的可训练世界模型。
2.2 人类和动物学习模型层次结构
人类和非人类动物在生命的最初几天、几周和几个月里学习关于世界如何运作的基本知识。尽管这些知识在短时间内获得了巨大的数量,但这些知识似乎非常基础,以至于我们认为理所当然。在生命的最初几个月里,我们学习到世界是三维的。我们学习到世界上的每一个光源、声音和触觉都与我们有距离。事实上,视觉感知中的每一点都有一个距离,这是解释我们的世界观如何从左眼到右眼,或者当我们的头部移动时发生变化的最好方式。视差运动使深度变得显而易见,这反过来使对象的概念变得显而易见,以及对象可以遮挡更远的对象这一事实。一旦建立了对象的存在,它们就可以根据其外观或行为自动分配到广泛的类别中。在对象的概念之上,是关于对象不会自发出现、消失、改变形状或传送的知识:它们平稳移动,并且在任何时候只能处于一个地方。一旦获得了这些概念,就很容易学习到有些对象是静态的,有些具有可预测的轨迹(无生命对象),有些以某种不可预测的方式表现(如水、沙子、风中的树叶等集体现象),有些似乎遵循不同的规则(有生命对象)。直观物理学的概念,如稳定性、重力、惯性等,可以在此基础上涌现。有生命对象对世界的影响(包括主体自身行为的影响)可以用来推断因果关系,在此基础上可以获得语言和社会知识。
图 1(由 Emmanuel Dupoux 提供)显示了婴儿在什么年龄似乎获得了诸如对象恒存性、基本类别、直观物理学等基本概念。更高抽象层次的概念似乎是在低层次概念之上发展起来的。
具备了这些世界知识,结合简单的硬编码行为和内在动机/目标,动物可以快速学习新任务,预测其行为的后果并提前规划,预见成功的行动过程并避免危险的情况。
但人类或动物的大脑能否包含生存所需的所有世界模型?本文的一个假设是,动物和人类在他们的前额叶皮层某处只有一个世界模型引擎。该世界模型引擎是针对手头任务动态可配置的。通过单一的、可配置的世界模型引擎,而不是为每种情况配备单独的模型,关于世界如何运作的知识可以在任务之间共享。这可能通过将为一种情况配置的模型应用于另一种情况,从而实现类比推理。
为了使事情具体化,我将直接深入描述所提出的模型。
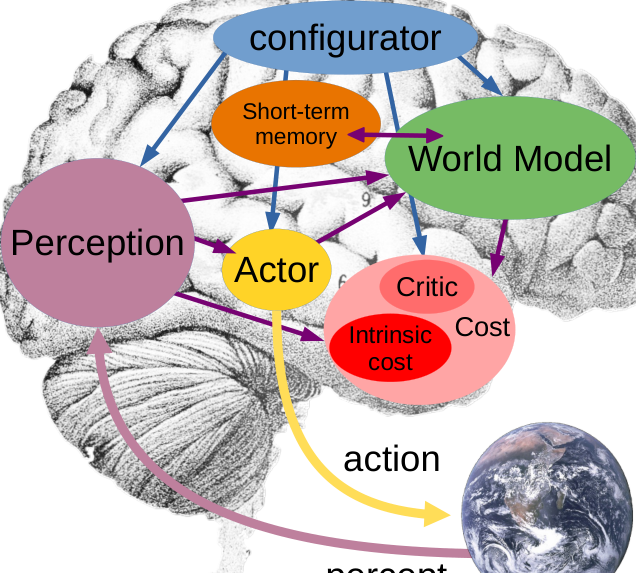
图 2: 自主智能的系统架构。该模型中的所有模块都被假定为“可微的”,即一个馈入另一个模块的模块(通过连接它们的箭头)可以获得成本标量输出相对于其自身输出的梯度估计。
- 配置器模块接收来自所有其他模块的输入(为清晰起见未表示),并配置它们以执行手头的任务。
- 感知模块估计世界的当前状态。
- 世界模型模块根据参与者提出的想象动作序列预测可能的未来世界状态。
- 成本模块计算一个称为“能量”的单一标量输出,用于衡量智能体的不适程度。它由两个子模块组成:内在成本(不可变,不可训练,计算当前状态的即时能量,如疼痛、快乐、饥饿等)和评论家(一个可训练的模块,预测内在成本的未来值)。
- 短期记忆模块跟踪当前和预测的世界状态以及相关的内在成本。
- 参与者模块计算动作序列的建议。世界模型和评论家计算可能产生的结果。参与者可以找到一个最优动作序列,该序列能最小化估计的未来成本,并输出最优序列中的第一个动作。 详见第 3 节。
3 自主智能的模型架构
所提出的自主智能体架构如图 2 所示。
它由多个模块组成,其功能描述如下。其中一些模块是动态可配置的,即它们的精确功能由配置器模块决定。配置器的作用是执行控制:给定要执行的任务,它会为手头的任务预配置感知、世界模型、成本和参与者。配置器调节它所馈入模块的参数。
配置器模块接收来自所有其他模块的输入,并通过调节它们的参数和注意力电路来为手头的任务配置它们。特别是,配置器可以引导感知、世界模型和成本模块以实现特定的目标。
感知模块接收来自传感器的信号并估计世界的当前状态。对于给定的任务,只有感知到的世界状态的一小部分是相关且有用的。感知模块可以以分层方式表征世界状态,具有多个抽象层次。配置器引导感知系统从感知中提取与手头任务相关的信息。
世界模型模块构成了架构中最复杂的部分。它的作用是双重的:(1) 估计感知未提供的关于世界状态的缺失信息,(2) 预测世界可能的未来状态。世界模型可以预测世界的自然演变,或者可以预测由参与者模块提出的动作序列所导致的世界未来状态。世界模型可以预测多个可能的世界状态,这些状态由代表关于世界状态不确定性的潜在变量参数化。世界模型是一种关于世界相关方面的“模拟器”。世界状态的哪些方面是相关的取决于手头的任务。配置器配置世界模型以处理手头的情况。预测是在包含与手头任务相关信息的抽象表征空间内执行的。理想情况下,世界模型将操作多个抽象层次上的世界状态表征,从而允许它在多个时间尺度上进行预测。
一个关键问题是,世界模型必须能够表征世界状态的多个可能预测。自然界并非完全可预测。如果它包含潜在的对抗性其他智能体,情况尤其如此。但即使世界只包含行为混乱或状态未完全可观测的无生命物体,情况也往往如此。
在构建所提出的架构时,有两个基本问题需要回答:(1) 如何允许世界模型做出多个合理的预测并表征预测中的不确定性,以及 (2) 如何训练世界模型。
成本模块以称为能量的标量形式衡量智能体的“不适”程度。能量是两个子模块计算出的两个能量项之和:内在成本模块和可训练评论家模块。智能体的总体目标是采取行动,以保持在最小化平均能量的状态。
内在成本模块是硬编码的(不可变的,不可训练的),并计算一个单一标量,即衡量智能体瞬时“不适”的内在能量——想想疼痛(高内在能量)、快乐(低或负内在能量)、饥饿等。该模块的输入是感知模块产生的当前世界状态,或世界模型预测的潜在未来状态。智能体的最终目标是长期最小化内在成本。这就是基本行为驱动和内在动机所在。内在成本模块的设计决定了智能体行为的本质。基本驱动力可以在此模块中硬编码。这可能包括在站立时感到“良好”(低能量)以激励腿部机器人行走,在影响世界状态时以激励代理,在与人类互动时以激励社会行为,在感知附近人类的快乐时以激励同理心,在拥有充足能量供应时(饥饿/饱腹感),在体验新情况时以激励好奇心和探索,在完成特定程序时等。相反,当面对痛苦的情况或容易识别的危险情况(靠近极端高温、火等)时,或者在使用危险工具时,能量会很高。内在成本模块可以由配置器调节,以在不同时间驱动不同的行为。
可训练评论家模块预测未来内在能量的估计值。与内在成本一样,其输入是当前世界状态或世界模型预测的可能状态。为了训练,评论家从关联记忆模块中检索过去的状态和随后的内在成本,并训练自己从前者预测后者。评论家模块的功能可以由配置器动态配置,以引导系统实现特定的子目标,作为更大任务的一部分。
因为成本模块的两个子模块都是可微的,所以能量的梯度可以通过其他模块(特别是世界模型、参与者和感知)进行反向传播,用于规划、推理和学习。
短期记忆模块存储关于过去、当前和未来世界状态的相关信息,以及内在成本的相应值。世界模型在时间上预测世界未来(或过去)状态,并在空间上补全缺失信息或纠正关于当前世界状态的不一致信息时,访问并更新短期记忆。世界模型可以向短期记忆发送查询并接收检索到的值,或存储状态的新值。评论家模块可以通过从记忆中检索过去的状态和相关的内在成本来训练。该架构可能类似于键值记忆网络 (Miller et al., 2016)。该模块可以被视为在脊椎动物中发挥与海马体相同的一些作用。
参与者模块计算动作序列的建议并将动作输出给效应器。参与者向世界模型提出动作序列。世界模型从动作序列预测未来的世界状态序列,并将其馈入成本模块。给定由成本定义的任务(由配置器配置),成本计算与建议动作序列相关的估计未来能量。由于参与者可以访问估计成本相对于建议动作序列的梯度,它可以使用基于梯度的方法计算最小化估计成本的最优动作序列。如果动作空间是离散的,则可以使用动态规划来找到最优动作序列。一旦优化完成,参与者将第一个动作(或短动作序列)输出给效应器。这个过程类似于最优控制中的模型预测控制 (Bryson and Ho, 1969)。
图 3: Mode-1 感知-行动片段。感知模块估计世界状态 。参与者通过策略模块 直接计算动作或短动作序列。 这种反应式过程不使用世界模型也不使用成本。成本模块计算初始状态的能量 并将对 存储在短期记忆中。可选地,它还可以使用世界模型预测下一个状态 ,以及相关的能量 ,以便在采取行动后产生的下一个观察结果可用时,可以调整世界模型。
参与者可能包含两个组件:(1) 一个策略模块,直接从感知产生并从短期记忆中检索到的世界状态估计中产生动作,以及 (2) 如上所述的动作优化器,用于模型预测控制。第一种模式类似于丹尼尔·卡尼曼的“系统 1”,而第二种模式类似于“系统 2” (Kahneman, 2011)。
在下文中,我们将使用特定的符号来表示架构图中的各种组件。附录 8.3.3 中给出了简要说明。
3.1 典型的感知-行动循环
模型可以采用两种可能的模式进行感知-行动片段。第一种模式不涉及复杂的推理,直接从感知输出和可能的短期记忆访问中产生动作。我们将其称为“Mode-1”,类比卡尼曼的“系统 1”。第二种模式涉及通过世界模型和成本进行推理和规划。它类似于最优控制和机器人技术中的经典规划和推理范式——模型预测控制 (MPC)。我们将其称为“Mode-2”,类比卡尼曼的“系统 2”。我们在这里广义地使用“推理”一词,意指约束满足(或能量最小化)。许多类型的推理都可以被视为能量最小化的形式。
3.1.1 Mode-1:反应式行为
Mode-1 的感知-行动片段如图 3 所示。
感知模块通过编码器模块提取世界状态的表征 ,其中包含手头任务的相关信息。参与者的一个组件——策略模块,根据状态 产生动作。产生的动作被发送到效应器。
策略模块的功能由配置器调节,配置器将其配置为手头的任务。
策略模块实现了一种纯粹的反应式策略,不涉及通过世界模型的深思熟虑的规划或预测。然而,其结构可能相当复杂。例如,除了状态 之外,策略模块还可以访问短期记忆以获取关于过去世界状态的更完整信息。它可以使用短期记忆在给定当前状态的情况下进行动作的关联检索。
虽然成本模块是可微的,但其输出 通过外部世界间接受到先前动作的影响。由于世界是不可微的,因此无法将梯度从成本通过链式法则 进行反向传播。在这种模式下,成本 相对于动作的梯度只能通过用多个扰动动作轮询世界来估计,但这既缓慢又具有潜在危险。这个过程将对应于强化学习中的经典策略梯度方法。
在 Mode-1 期间,系统可以选择性地调整世界模型。它运行世界模型一步,预测下一个状态 ,然后等待采取行动后产生的下一个感知,并使用观察到的世界状态作为预测器的目标。
通过使用世界模型,智能体可以想象行动过程并预测其效果和结果,从而减少通过在外部世界中尝试多种动作并测量结果来执行昂贵且危险的良好动作和策略搜索的需要。
3.1.2 Mode-2:使用世界模型进行推理和规划
Mode-2 的典型感知-行动片段如图 4 所示。
- 感知:感知系统提取当前世界状态的表征 。成本模块计算并存储与该状态相关的即时成本。
- 动作建议:参与者提出一个初始动作序列,以馈入世界模型进行评估 。
- 模拟:世界模型预测由建议的动作序列产生的一个或多个可能的世界状态表征序列 。
- 评估:成本模块从预测的状态序列估计总成本,通常作为时间步长的总和 。
- 规划:参与者提出一个成本更低的新动作序列。这可以通过基于梯度的过程来完成,在该过程中,成本的梯度通过计算图反向传播到动作变量。产生的最小成本动作序列表示为 。完全优化可能需要迭代步骤 2-5。

图 4: Mode-2 感知-行动片段。感知模块估计世界状态 。参与者提出动作序列 。世界模型递归地使用 预测世界状态序列的估计值。成本 计算序列中每个预测状态的能量,总能量是它们的总和。通过优化或搜索过程,参与者推断出一个最小化总能量的动作序列。然后它将序列中的第一个动作(或前几个动作)发送到效应器。这实际上是具有滚动视界规划的经典模型预测控制的一个实例。由于成本和模型是可微的,因此可以使用基于梯度的方法来搜索最优动作序列,就像在经典最优控制中一样。由于总能量随时间是可加的,因此也可以使用动态规划,特别是在动作空间较小且离散化时。状态对(由编码器计算或由预测器预测)以及来自内在成本和可训练评论家的相应能量被存储在短期记忆中,用于后续的评论家训练。
- 行动:在收敛到低成本动作序列后,参与者将低成本序列中的第一个动作(或前几个动作)发送到效应器。整个过程针对下一个感知-行动片段重复。
- 记忆:每次行动后,来自内在成本和评论家的状态和相关成本被存储在短期记忆中。这些对可以在以后用于训练或调整评论家。
这个过程本质上就是最优控制文献中所知的具有滚动视界模型预测控制 (MPC)。与经典最优控制的区别在于世界模型和成本函数是学习出来的。
原则上,步骤 5 可以使用任何形式的优化策略。虽然当世界模型和成本表现良好时,基于梯度的优化方法可能是有效的,但动作-成本映射具有不连续性的情况可能需要使用其他优化策略,特别是如果状态和/或动作空间可以离散化时。这些策略包括动态规划、组合优化、模拟退火和其他无梯度方法、启发式搜索技术(例如带剪枝的树搜索)等。
为了简化,该过程是在确定性情况下描述的,即当不需要处理给定初始状态 和动作 导致 的多种预测的可能性时。在现实情况下,世界很可能是不可预测的。由于世界本质上是随机的(偶然不确定性),或者状态表征 包含关于真实世界状态的不完整信息(认知不确定性),或者由于有限的训练数据、表征能力或计算约束导致世界模型的预测精度不完美,单个初始状态和动作可能导致多种状态。
图 5: 从 Mode-2 推理结果训练反应式策略模块。使用 Mode-2 是繁重的,因为它调动了智能体所有的资源来处理手头的任务。它涉及反复多次运行世界模型。该图描绘了如何训练策略模块 以近似 Mode-2 优化产生的动作。系统首先在 Mode-2 中运行并产生最优动作序列 。然后调整策略模块的参数,以最小化最优动作与策略模块输出之间的散度 。这产生了一个执行摊销推理的策略模块,并为良好的动作序列产生近似值。然后,策略模块可用于在 Mode-1 中反应式地产生动作,或在 Mode-2 推理之前初始化动作序列,从而加速优化。
3.1.3 从 Mode-2 到 Mode-1:学习新技能
使用 Mode-2 是繁重的。智能体只拥有一个世界模型“引擎”。它由配置器针对手头的任务进行配置,但一次只能用于单个任务。因此,与人类类似,智能体一次只能专注于一个复杂的任务。
Mode-1 的负担要轻得多,因为它只需要通过策略模块进行单次传递。智能体可能同时拥有多个策略模块,每个模块专门用于一组特定的任务。
图 5 中描述的过程展示了如何训练策略模块 以产生 Mode-2 推理产生的最优动作的近似值。系统在 Mode-2 上运行,产生最优动作序列 。然后,更新策略模块 的参数,以最小化其输出与当时最优动作之间的散度度量 。一旦训练得当,策略模块就可以直接用于在 Mode-1 中产生动作 。它也可以用于在 Mode-2 优化之前递归地计算初始动作序列建议:
策略模块可以被视为执行一种摊销推理。
这个过程允许智能体利用其世界模型和推理能力的全部力量来获得新技能,然后这些技能被“编译”成不再需要仔细规划的反应式策略模块。
3.1.4 推理作为能量最小化
在 Mode-2 中阐述合适的动作序列的过程可以被视为一种推理形式。这种推理形式基于使用世界模型的模拟,以及相对于动作序列的能量优化。更一般地,“动作”可以被视为代表从一个状态到下一个状态的抽象转换的潜在变量。这种通过模拟和优化进行的规划可能构成了自然智能中最常见的推理类型。
人工智能中的许多经典推理形式实际上可以被表述为优化问题(或约束满足问题)。对于使用因子图和概率图模型进行的概率推理,情况肯定如此。所提出的架构实际上是一个因子图,其中成本模块是日志因子。但所提出的架构所实现的推理类型超越了传统的逻辑和概率推理。它允许通过模拟和类比进行推理。

图 6: 成本模块架构。成本模块包含不可变的内在成本模块 (左)和可训练的评论家或可训练成本 (右)。IC 和 TC 都由多个子模块组成,它们的输出能量被线性组合。每个子模块在智能体中赋予特定的行为驱动。线性组合中的权重 和 由配置器模块确定,并允许智能体在不同时间专注于不同的子目标。
3.2 成本模块作为行为的驱动力
成本模块的整体架构如图 6 所示。它由不可变的内在成本模块 和可训练的评论家或可训练成本 组成。IC 和 TC 都由多个子模块组成,它们的输出能量被线性组合:
每个子模块赋予智能体特定的行为驱动。线性组合中的权重 和 由配置器模块调节,并允许智能体在不同时间专注于不同的子目标。
内在成本模块 (IC) 是定义智能体基本行为本质的地方。在这里可以间接指定基本行为。
对于机器人,这些术语将包括对应于“疼痛”、“饥饿”和“本能恐惧”的明显本体感觉测量,测量诸如外部力过载、危险的电气、化学或热环境、过度功耗、电源中能量储备水平低等事物。
它们还可以包括帮助智能体学习基本技能或完成其任务的基本驱动力。例如,腿部机器人可能包含一个内在成本来驱动它站立和行走。这还可以包括社会驱动力,例如寻求人类的陪伴,发现与人类的互动和来自他们的赞美是有益的,并发现他们的痛苦是不愉快的(类似于社会性动物的同理心)。其他内在行为驱动力,如好奇心,或采取具有可观察影响的行动,也可以包括在内,以最大限度地提高训练世界模型的情况的多样性 (Gottlieb et al., 2013)。
IC 可以被视为在哺乳动物大脑和脊椎动物的其他类似结构中发挥类似于杏仁核的作用。
为了防止一种行为崩溃或向不良行为的失控漂移,IC 必须是不可变的,且不受学习(也不受外部修改)的影响。
评论家 (TC) 的作用是双重的:(1) 以最小化使用繁重的世界模型来预期长期结果,以及 (2) 允许配置器使智能体专注于通过学习到的成本来完成子目标。
通常,AI 智能体的行为本质可以通过四种方式指定:
- 通过显式编程在满足特定条件时激活的特定行为。
- 通过定义目标函数,使得智能体通过找到最小化该目标的动作序列来执行期望的行为。
- 通过直接监督训练智能体以某种方式行事。智能体观察专家教师的动作,并训练一个 Mode-1 策略模块来重现它。
- 通过模仿学习训练智能体。智能体观察专家教师,并推断出他们的行为在行动时似乎正在优化的目标函数。这为 Mode-2 行为产生了一个评论家子模块。这个过程有时被称为逆向强化学习。
第二种方法在工程上比第一种方法简单得多,因为它仅仅需要设计一个目标,而不是设计一个完整的行为。第二种方法也更稳健:预定的行为可能会因意外情况或不断变化的环境而失效。有了目标,智能体可以调整其行为以满足目标,尽管有意外情况和环境变化。第二种方法利用智能体的学习和推理能力,最大限度地减少设计者硬编码的、容易变得脆弱的先验。
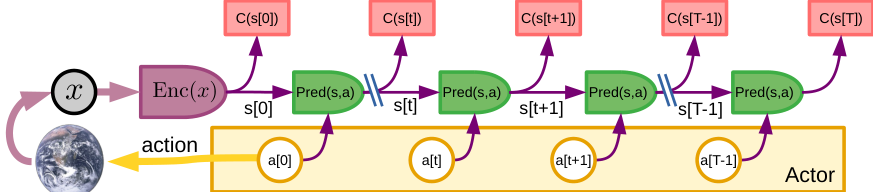
图 7: 训练评论家。在规划片段期间,内在成本模块将三元组(时间、状态、内在能量): 存储到关联短期记忆中。在评论家训练片段期间,评论家检索过去的状态向量 ,以及在较晚时间 的内在能量。在最简单的场景中,评论家调整其参数以最小化目标 与预测能量 之间的散度度量。在更复杂的方案中,它可以使用未来内在能量的组合作为目标。注意,状态序列可能包含关于智能体计划或采取的动作的信息。
3.3 训练评论家
一个基本问题是如何训练评论家。
评论家的主要作用是预测未来内在能量的值。为此,它使用短期记忆模块。该模块是一个关联记忆,内在成本模块在其中存储三元组(时间、状态、内在能量):。存储的状态和相应的内在能量可能对应于感知到的状态,或世界模型在 Mode-2 片段期间想象的状态。记忆可以在给定时间 时检索状态 ,并可以在给定时间 或状态 时检索能量 。通过合适的记忆架构,检索可能涉及键和检索值的插值。该过程如图 7 所示。
评论家可以通过检索过去的状态向量 以及在较晚时间 的内在能量来训练以预测未来的内在能量值。然后可以优化评论家的参数以最小化预测损失,例如 。这是一个简单的场景。可以设计更复杂的方案来预测折扣未来能量的期望值,或其分布。注意,状态向量可能包含关于参与者采取或想象的动作的信息。
在一般层面上,这类似于 A2C 等强化学习方法中使用的评论家训练方法。
短期记忆可以实现为键值记忆网络中的记忆模块:查询向量与多个键向量进行比较,产生一个分数向量。分数被归一化并用作系数来输出存储值的线性组合。它可以被视为一种能够插值的“软”关联记忆。它的一个优点是,通过适当的新键/值槽分配方案,它能够进行一次性学习,同时可以在键之间进行插值,并且是端到端可微的。
4 设计和训练世界模型
可以说,设计世界模型的架构和训练范式构成了未来几十年人工智能取得真正进展的主要障碍。本提案的主要贡献之一正是用于世界模型的分层架构和训练程序,该模型可以在其预测中表征多个结果。
训练世界模型是自监督学习 (SSL) 的一个原型示例,其基本思想是模式补全。对未来输入(或暂时未观察到的输入)的预测是模式补全的一个特例。在这项工作中,世界模型的主要目的被视为预测世界状态的未来表征。
有三个主要问题需要解决。首先,很明显,世界模型的质量将很大程度上取决于它在训练时能够观察到的状态序列,或(状态、动作、结果状态)三元组的多样性。其次,因为世界并非完全可预测,所以可能存在多个合理的世界状态表征,它们跟随给定的世界状态表征和智能体的动作。世界模型必须能够有意义地表征这个可能无限的合理预测集合。第三,世界模型必须能够在不同的时间尺度和不同的抽象层次上进行预测。
第一个问题触及了围绕顺序决策过程学习的核心问题之一:训练集的多样性取决于所采取的动作。这个问题将在下面的第 4.10 节中讨论。
第二个问题更为严峻:世界并非完全可预测。因此,世界模型应该能够从给定的状态和(可选的)动作中表征多个合理的结果。这可能构成了本提案解决的最困难的挑战之一。这个问题将在下面的第 4.8 节中讨论。
第三个问题涉及长期预测和规划的问题。人类在抽象层面上规划复杂目标,并使用世界状态和动作的高级描述来进行预测。然后,高级目标被分解为更基本的子目标序列,使用来自世界模型的短期预测来产生低级动作。这个分解过程一直重复到毫秒级的肌肉控制,并由局部条件提供信息。关于世界模型如何能够在多个时间尺度和多个抽象层次上表征行动计划的问题,将在第 4.6 节中讨论。
4.1 自监督学习
自监督学习 (SSL) 是一种范式,其中学习系统被训练以捕获其输入之间的相互依赖关系。具体而言,这通常归结为训练一个系统来告诉我们其输入的各个部分是否彼此一致。
例如,在视频预测场景中,系统被给予两个视频片段,并且必须告诉我们第二个视频片段在多大程度上是第一个片段的合理延续。在模式补全场景中,系统被给予输入的一部分(图像、文本、音频信号)以及输入其余部分的建议,并告诉我们该建议是否是第一部分的合理补全。在下文中,我们将用 表示输入的观察部分,用 表示可能未观察到的部分。
重要的是,我们不强求模型能够从 预测 。原因在于,对于给定的 ,可能存在无限多个与 兼容的 。在视频预测设置中,存在无限多个视频片段是给定片段的合理延续。显式地表征所有合理预测的集合可能很困难,甚至是不可能的。但仅仅要求系统告诉我们一个提议的 是否与给定的 兼容,似乎并不那么不便。
一个通用的表述可以在能量模型 (EBM) 的框架内完成。该系统是一个标量值函数 ,当 和 兼容时产生低能量值,当它们不兼容时产生较高值。这个概念如图 8 所示。数据点是黑点。能量函数在数据点周围产生低能量值,而在高数据密度区域之外产生较高能量,正如能量景观的等高线所象征的那样。EBM 隐函数表述使系统能够表征多模态依赖关系,其中多个 值与给定的 兼容。与给定 兼容的 集合可能是一个点、多个离散点、一个流形,或点和流形的集合。
为了实现 Mode-2 规划,预测性世界模型应该被训练以捕获过去和未来感知之间的依赖关系。它应该能够从过去和现在的表征中预测未来的表征。一般的学习原则如下:给定两个输入 和 ,学习两个计算表征 和 的函数,使得 (1) 和 关于 和 具有最大信息量,并且 (2) 可以很容易地从 预测出来。这一原则确保了在使世界在表征空间中的演变可预测,与在表征中尽可能多地捕获关于世界状态的信息之间取得平衡。
这样的 SSL 系统通过在视频上进行训练可以学习到什么概念?我们的假设是,可以获得关于世界如何运作的抽象概念层次结构。学习一个小图像区域的表征,使其能够从空间和时间上围绕它的相邻区域进行预测,将导致系统提取图像中的局部边缘和轮廓,并检测视频中的移动轮廓。学习图像的表征,使得从一个视点观察到的场景表征可以从稍微不同的视点观察到的相同场景表征中预测出来,将导致系统隐式地表征深度图。深度图是解释当摄像机稍微移动时场景视图如何变化的简单方式。一旦学习到了深度的概念,系统识别遮挡边缘以及属于刚性物体的区域的集体运动就变得简单了。3D 物体的隐式表征可能会自发涌现。一旦对象的概念在表征中涌现,像对象恒存性这样的概念可能变得容易学习:由于视差运动而消失在其他物体后面的物体将不可避免地再次出现。无生命物体和有生命物体之间的区别将随之而来:无生命物体是那些轨迹容易预测的物体。直观物理学概念(如稳定性、重力、惯性等)可能通过训练系统在对象表征层面执行长期预测而随之而来。人们可以想象,通过在越来越抽象的表征层次和越来越长的时间尺度上进行预测,关于世界如何运作的越来越复杂的概念可能会以分层方式获得。
通过预测学习抽象概念的思想是一个古老的思想,几十年来在认知科学、神经科学和人工智能领域被许多作者以各种方式表述。问题在于如何精确地做到这一点。
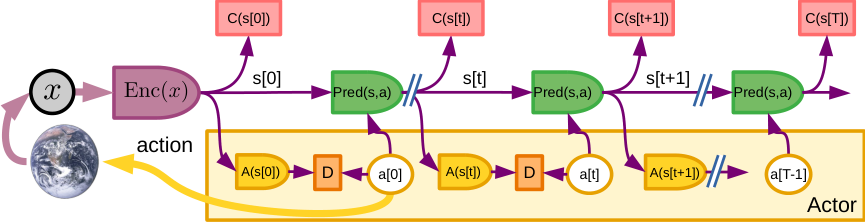
图 8: 自监督学习 (SSL) 和能量模型 (EBM)。SSL 是一种学习范式,其中学习系统被训练以“填补空白”,或者更精确地说是捕获输入中观察到的部分与输入中可能未观察到的部分之间的依赖关系。输入信号的一部分被观察并记为 (粉色),输入信号的一部分要么被观察要么未被观察,记为 (蓝色)。在时间预测场景中, 代表过去和现在的观察结果, 代表未来的观察结果。在一般的模式补全场景中,输入的各个部分可能在不同时间被观察或未被观察。学习系统通过标量值能量函数 被训练以捕获 和 之间的依赖关系,该函数在 和 一致或兼容时取低值,而在 和 不一致或不兼容时取较高值。在视频预测场景中,如果视频片段 是视频片段 的合理延续,系统将产生一个低能量值。这种能量模型 (EBM) 表述使系统能够表征多模态依赖关系,其中多个 值(可能是一个无限集)可能与给定的 兼容。在右侧面板中,表示了一个能量景观,其中深色圆盘代表数据点,闭合线代表能量函数的等高线(水平集)。
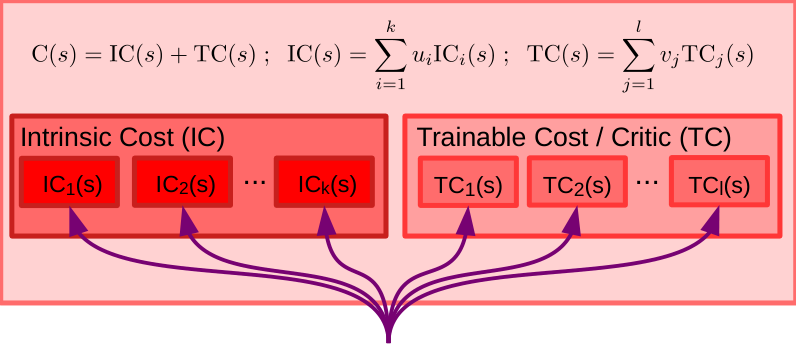
图 9: 潜在变量能量模型 (LVEBM)。为了评估 和 之间的兼容性程度,EBM 可能需要潜在变量 的帮助。潜在变量可以被视为参数化了 与一组兼容的 之间的可能关系集合。潜在变量代表了无法从 中提取的关于 的信息。例如,如果 是一个物体的视图, 是同一物体的另一个视图, 可能参数化了两个视图之间的摄像机位移。推理包括找到最小化能量的潜在变量 。产生的能量 仅取决于 和 。在双视图示例中,推理找到了最能解释 如何转换为 的摄像机运动。
4.2 用潜在变量处理不确定性
如上所述,主要问题之一是使模型能够表征多个预测。这可能需要使用潜在变量。潜在变量是一个输入变量,其值未被观察到但被推断出来。潜在变量可以被视为参数化了 与一组兼容的 之间的可能关系集合。潜在变量用于代表无法从 中提取的关于 的信息。
想象一个场景,其中 是场景的照片, 是从稍微不同的视点拍摄的同一场景的照片。为了判断 和 是否确实是来自同一场景的视图,可能需要推断两个视图之间的摄像机位移。类似地,如果 是一辆汽车驶向道路分叉处的图片, 是几秒钟后汽车在分叉处其中一个分支上的图片, 和 之间的兼容性取决于可以推断出的二进制潜在变量:汽车是向左转还是向右转。
在时间预测场景中,潜在变量代表了无法仅从 和过去的观察结果(过去)中预测关于 (未来)的内容。它应该包含所有对预测有用但不可观察或不可知的信息。我可能不知道前面的司机是会左转还是右转、加速还是刹车,但我可以用潜在变量来表征这些选项。
潜在变量 EBM (LVEBM) 是一个依赖于 和 的参数化能量函数:。当呈现一对 时,EBM 的推理过程会找到最小化能量的潜在变量 的值:
这种通过最小化进行的潜在变量推理允许我们从能量函数中消除 :
从技术上讲, 应该被称为零温度自由能,但我们将继续称其为能量。
4.3 训练能量模型
在讨论 EBM 训练之前,重要的是要注意 EBM 的定义没有涉及任何概率建模。尽管许多 EBM 可以很容易地通过吉布斯分布等转化为概率模型,但这绝不是必需的。因此,能量函数被视为基本对象,并不被假定为隐式地代表概率分布的非归一化对数。
训练 EBM 包括构建一个架构(例如深度神经网络)来计算由参数向量 参数化的能量函数 。训练过程必须寻求一个 向量,使能量函数具有正确的形状。对于训练集中的给定 ,训练有素的 将为训练集中与 相关联的 值产生较低的能量,而为 的其他值产生较高的能量。
给定一个训练样本 ,训练 EBM 归结为设计一个合适的损失函数 ,它可以直接表示为参数向量 的函数,并且使得最小化该损失将使训练样本的能量 低于任何不同于 的 的能量 。
使训练样本的能量变低很容易:只要损失是能量的递增函数,且能量有下界即可。
困难的问题是如何确保不同于 的 的能量高于 的能量。如果没有特定的规定来确保每当 时 ,能量景观可能会遭受崩溃:给定一个 ,能量景观可能会变得“平坦”,给所有 值赋予本质上相同的能量。
哪些 EBM 架构容易崩溃?EBM 是否容易崩溃取决于其架构。图 10 显示了一些标准架构,并指出了它们是否可能遭受崩溃。
常规预测或确定性生成架构(图 10(a))不会崩溃。对于任何 ,都会产生单个 。只要 ,能量就为零。只要 在 不同于 时严格大于零,任何不同于 的 都会具有更高的能量。
生成式潜在变量架构(非确定性生成式)(图 10(b))当潜在变量具有过多的信息容量时可能会崩溃。当潜在变量 在集合 上变化时,预测 在集合 上变化,该集合必须匹配与 兼容的 集合。如果 太“大”,那么低能量 的区域可能比高数据密度的区域更大。如果 与 具有相同的维度,系统很可能会给整个 空间赋予零能量。
自动编码器 (AE)(图 10(c))当表征 具有过多的信息容量时可能会崩溃。例如,如果 的维度等于或高于 的维度,AE 可能会学习恒等函数,从而在整个 空间上产生等于零的重构误差。
最后,联合嵌入架构 (JEA)(图 10(d))当 和/或 携带的信息不足时可能会崩溃。如果编码器忽略输入,并产生恒定且相等的代码 ,则整个空间将具有零能量。
这些只是架构的几个例子。
我们如何设计损失函数来防止崩溃?有两种方法:对比方法和正则化方法。在下文中,我将论证对比方法存在缺陷,而正则化(非对比)方法在长期来看更有可能更可取。
对比方法包括使用一种损失函数,其最小化效果是压低训练样本 的能量,并拉高适当产生的“对比”样本 的能量。对比样本 的选择方式应确保 EBM 为高数据密度区域之外的点分配更高的能量。这转化为设计一种损失函数,它是 的递增函数,也是 的递减函数,至少在 不足以高于 时是这样。有许多这样的对比损失函数,其中一些采用单个三元组 ,另一些需要一批正样本和对比样本 。
对比损失函数的一个简单示例如下:
其中 是 的递增函数,并且每当后者小于前者加上正边际函数 时,它是 的递减函数。这种损失的一个简单实例是距离依赖的铰链损失:
其中 在 为正时是恒等式,否则为零。这使得能量至少随数据流形的距离呈二次增长。其他对比损失函数考虑了多个对比样本:
这必须是第一个参数的递增函数,并且是所有其他参数的递减函数。这种损失的一个例子是流行的 InfoNCE:
对比方法非常流行,特别是对于使用成对训练的孪生网络架构,其中 是 的失真或损坏版本,而 是另一个随机(或适当选择)的训练样本。这包括原始孪生网络等方法,以及包括 DrLIM、PIRL、MoCO、SimCLR、CPT 等在内的更现代的方法。对比方法还包括诸如以最大似然训练的概率模型等经典方法,这些模型不会自动归一化。对比样本 通常使用蒙特卡洛方法、马尔可夫链蒙特卡洛方法或其近似版本(如对比散度)产生。生成对抗网络也可以被视为对比方法,其中 由可训练的生成器网络产生。去噪自动编码器及其特例掩码自动编码器,也是对比训练方法的例子,其中 是通过破坏干净的 产生的。附录 8.3.3 中对各种对比方法进行了更详细的讨论。
但对比方法存在两个主要问题。首先,必须设计一种方案来生成或选择合适的 。其次,当 处于高维空间时,如果 EBM 是灵活的,它可能需要大量的对比样本来确保能量在局部数据分布未占据的所有维度中更高。由于维数灾难,在最坏的情况下,对比样本的数量可能随表征的维度呈指数增长。这就是我反对对比方法的主要原因。
用于 EBM 训练的正则化方法在长期来看比对比方法更有前途,因为它们可以避免困扰对比方法的维数灾难。它们包括构建一种损失函数,其效果是压低训练样本的能量,同时最小化模型关联低能量的 空间的体积。低能量区域的体积由能量和/或损失中的正则化项来衡量。通过在压低数据点能量的同时最小化该正则化项,低能量区域将把高数据密度区域“收缩包裹”在低能量区域内,只要能量函数的灵活性允许。非对比正则化方法的主要优点是它们比对比方法更不容易受到维数灾难的影响。主要问题恰恰是如何设计这种体积最小化的正则化器。答案很大程度上取决于模型的架构,这将在接下来的章节中讨论。然而,非对比方法已经存在很长时间了。例子包括稀疏建模、稀疏自动编码器和具有噪声潜在变量的自动编码器,如 VAE。
重要的是要注意,对比方法和正则化方法并不相互排斥,可以在同一个模型上同时使用。
正则化方法将如何应用于图 10(b-d) 的架构?
在潜在变量生成架构中,限制 的信息容量将限制可以取低能量的 空间的体积。如果 是具有 个可能值的离散变量, 空间中最多有 个点将具有零能量。如果 是维度为 的流形,那么具有零能量的 空间的区域将最多有 个维度。
类似地,在自动编码器架构中,限制 的信息容量将限制可以以低能量重构的 空间的体积。
最后,在联合嵌入架构中,最大化 包含关于 的信息以及 包含关于 的信息,将最小化可以取低能量的 空间的体积。
在下文中,我们将重点关注一种用于 SSL 的架构——联合嵌入预测架构 (JEPA),它可以被视为联合嵌入架构和潜在变量生成架构的组合。JEPA 是非生成式的,因为它实际上并不预测 ,而是从 的表征 预测 的表征 。
4.4 联合嵌入预测架构 (JEPA)
本文的核心是联合嵌入预测架构 (JEPA)。JEPA 在某种意义上不是生成式的,因为它不能轻易地用于从 预测 。它仅仅捕获 和 之间的依赖关系,而不显式生成 的预测。
通用的 JEPA 如图 12 所示。两个变量 和 被馈入两个编码器,产生两个表征 和 。这两个编码器可能不同。它们不需要拥有相同的架构,也不需要共享它们的参数。这允许 和 在本质上不同(例如视频和音频)。预测器模块从 的表征预测 的表征。预测器可能依赖于潜在变量 。能量仅仅是表征空间中的预测误差:
总能量通过对 进行最小化获得:
JEPA 的主要优点是它在表征空间中执行预测,避免了预测 的每一个细节的需要。这是因为 的编码器可以选择产生一个抽象表征,从中消除了不相关的细节。
但 JEPA 有两种方式可以表征与 兼容的多个 值。第一种是 编码器的不变性属性,第二种是潜在变量 ,如下所述。
通过编码器不变性的多模态: 编码器函数 可能具有不变性属性。如果集合中的所有 都映射到相同的 值,那么所有这些 将具有相同的能量。使用 JEPA,我们失去了生成输出的能力,但我们获得了一种强大的方式来表征输入和输出之间的多模态依赖关系。
通过潜在变量预测器的多模态: 预测器可以使用潜在变量 来捕获预测 所需但 中不存在的信息。当 在集合 上变化时,预测器产生一组合理的预测 。例如,如果 是一辆汽车驶向道路分叉处的视频片段, 和 可能分别代表分叉前后汽车的位置、方向、速度和其他特征,忽略诸如道路边缘的树木或人行道纹理等不相关细节。潜在变量 可能是一个二进制变量,指示汽车是走左分支()还是右分支()。如果汽车走左分支,值 将产生比 更低的能量 。
4.5 训练 JEPA
像任何 EBM 一样,JEPA 可以用对比方法进行训练。但是,如上所述,对比方法在高维空间中往往变得非常低效。这里的相关维度是 的维度,它可能比 小得多,但对于高效训练来说仍然太高。
使 JEPA 特别有趣的是,我们可以设计非对比方法来训练它们。正如第 4.3 节所解释的,非对比方法使用衡量可以取低能量值的空间体积的正则化器。在 JEPA 的情况下,这可以通过四个标准来完成,如图 13 所示:
- 最大化 关于 的信息内容。
- 最大化 关于 的信息内容。
- 使 容易从 预测出来。
- 最小化预测中使用的潜在变量 的信息内容。
标准 1、2 和 4 共同防止了能量函数的崩溃。它们确保 和 尽可能多地携带关于其输入的信息。没有这些标准,系统可能会选择使 和 保持恒定,或信息量较弱,这将使能量在输入空间的大部分区域保持恒定。标准 3 由能量项 强制执行,并确保 在表征空间中可以从 预测出来。标准 4 通过强制模型尽可能少地借助潜在变量来预测 ,从而防止系统陷入另一种类型的信息崩溃。这种类型的崩溃可以通过以下思想实验来理解。假设 与 具有相同的维度。假设预测器是一个参数化函数(例如神经网络),它可以选择忽略 并简单地将 复制到其输出 。对于任何 ,都可以设置 ,这将使能量 为零。这对应于一个完全平坦且崩溃的能量表面。
我们如何防止这种崩溃发生? 通过限制或最小化潜在变量的信息内容。 如何做到这一点? 通过使 离散、低维、稀疏或有噪声,以及其他方法。
几个具体的例子可能有助于建立对该现象的直观理解。假设 ,并且 是具有 个可能整数值 的离散变量。对于给定的 , 只能有 个可能值:
因此,这些可以是具有零能量的 的唯一值,并且只有 个。考虑一个从 开始并向 移动的点 。它的能量将从零开始,随着 远离 而呈二次增长,直到 。当 变得比 更接近 时,能量将减少,并在 到达 时达到零。在表征空间中,能量将是 个二次能量井的最小值。
类似地,想象 是一个维度 低于 的向量。然后,假设 是 的平滑函数,可能的预测集合在 空间中最多是一个 维流形。
更重要的是,想象能量函数通过形式为 的 正则化项进行了增强,即 的 范数。这将驱动 变得稀疏。与经典的稀疏编码一样,这将导致低能量区域被低维流形的并集(如果 在 中是线性的,则为低维线性子空间的并集)所近似,其维度将由 正则化器最小化。
使 成为熵最大化的分布中的随机样本也将具有适当的正则化效果。这是变分自动编码器和类似模型的基础。
对可以最小化潜在变量信息内容的正则化器的更完整讨论超出了本文的范围。目前,我们可以提到四类方法:离散化/量化(例如 VQ-VAE (Walker et al., 2021))、维度/秩最小化(例如隐式秩最小化 AE (Jing et al., 2020))、稀疏化(如线性稀疏建模 (Olshausen and Field, 1996)、LISTA (Gregor and LeCun, 2010b) 和非线性稀疏建模 (Evtimova and LeCun, 2022))以及模糊化(如噪声 AE (Doi et al., 2007)、VAE (Kingma and Welling, 2013) 以及控制问题中使用的变体 (Henaff et al., 2019))。
JEPA 在表征空间中进行预测的能力使其比直接产生 预测的生成模型更可取。在视频预测场景中,预测每一帧的每一个像素值本质上是不可能的。地毯上的纹理细节、风中移动的树叶或池塘上的涟漪,都无法准确预测,至少在长期内且不消耗巨大资源的情况下是无法预测的。JEPA 的一个相当大的优势是它可以选择忽略那些不容易预测的输入细节。然而,标准 1 和 2 将确保被忽略细节的信息内容保持在最低限度。
我们如何实现标准 1 和 2? 换句话说,给定一个参数化的确定性编码函数 ,我们如何最大化 的信息内容? 如果 是可逆的, 包含关于 的所有信息,但这对于标准 3 来说可能是次优的,因为 将包含关于 的许多不相关或难以预测的细节。更精确地说,如果函数 是最小满射的,即如果映射到相同 的 集合的体积是最小的,那么 关于 具有最大信息量。同样的推理也适用于 编码器。为了将此标准转化为可微损失,我们需要做出一些假设。
4.5.1 VICReg
VICReg 方法 (Bardes et al., 2021) 对 和 的分布做出了一些假设。图形表示如图 14 所示。为了最大化 的信息内容,VICReg 使用以下两个子标准:(1) 的分量不能是恒定的,(2) 的分量必须尽可能彼此独立。这通过首先通过可训练的扩展器模块(例如具有几层的神经网络)将 和 非线性映射到更高维的嵌入 和 ,并使用具有在样本批次上计算的两个可微损失项的损失函数来近似:
- 方差: 一种铰链损失,它在批次上将 和 的每个分量的标准差保持在阈值以上。
- 协方差: 一种协方差损失,其中 不同分量对之间的协方差被推向零。这具有去相关 分量的效果,这反过来将使 的分量在某种程度上独立。
同样的标准分别应用于 和 。
VICReg 的第三个标准是表征预测误差 。在 VICReg 的最简单实现中,预测器是恒定的(等于恒等函数),使表征对将 转换为 的转换保持不变。在更复杂的版本中,预测器可能没有潜在变量,或者可能依赖于离散、低维或随机的潜在变量。
当预测器使用其信息内容必须最小化的潜在变量时,第四个标准是必要的,例如维度接近或超过 的向量。
VICReg 学习不变表征的一个简单实例化包括使 和 成为相同内容的不同视图(或失真版本),将预测器设置为恒等函数,并定义 。
通过基于梯度的优化方法推断潜在变量可能是繁重的。但计算成本可以通过使用摊销推理大大降低,如附录 8.3.3 中所解释的那样。
虽然对比方法确保了批次中不同输入的表征是不同的,但 VICReg 确保了批次上表征的不同分量是不同的。VICReg 是分量对比的,而传统的对比方法是向量对比的,这需要大量的对比样本。
但 JEPA 与 VICReg 和类似的非对比方法结合使用的最有前途的方面是用于学习分层预测世界模型,正如我们在下一节中探讨的那样。
4.5.2 使 JEPA 偏向于学习“有用”的表征
通过上述训练标准,JEPA 在表征的完整性和可预测性之间找到了平衡。什么是可预测的,什么没有被表征,是由编码器和预测器的架构隐式决定的。它们决定了一个归纳偏置,定义了什么信息是可预测的。
但如果有一种方法能使系统偏向于包含与一类任务相关信息的表征,那将是有用的。这可以通过添加预测头来完成,这些预测头以 作为输入,并被训练以预测可以从数据中轻松导出且已知与任务相关的变量。
4.6 分层 JEPA (H-JEPA)
以非对比方式训练的 JEPA 模型可能构成了我们学习能够学习相关抽象的世界模型的最佳工具。当使用 VICReg 和类似标准进行训练时,JEPA 可以选择训练其编码器以消除输入的无关细节,从而使表征更具可预测性。换句话说,JEPA 将学习使世界可预测的抽象表征。不可预测的细节将通过编码器的不变性属性被消除,或者被推入预测器的潜在变量中。由此忽略的信息量将通过训练标准和潜在变量正则化器最小化。
重要的是要注意,生成式潜在变量模型无法消除无关细节,除非将它们推入潜在变量中。这是因为它们不产生 的抽象(和不变)表征。这就是为什么我们反对使用生成式架构。
JEPA 学习抽象的能力表明了架构的扩展,以处理多个时间尺度和多个抽象层次上的预测。直观地说,低级表征包含关于输入的许多细节,可用于短期预测。但用相同水平的细节产生准确的长期预测可能很困难。相反,高级抽象表征可能实现长期预测,但代价是消除了许多细节。
让我们举一个具体的例子。在驾驶汽车时,给定在接下来的几秒钟内对方向盘和踏板的建议动作序列,驾驶员可以准确预测其汽车在同一时期内的轨迹。较长时期内的轨迹细节更难预测,因为它们可能取决于其他汽车、交通灯、行人和一些不可预测的外部事件。但驾驶员仍然可以在更高的抽象层面上做出准确的预测:忽略轨迹、其他汽车、交通信号等的细节,汽车可能会在可预测的时间框架内到达目的地。详细的轨迹将从这个描述层面上消失。但近似轨迹,如地图上绘制的那样,是被表征的。离散潜在变量可用于表征多个替代路线。
图 15 显示了用于多级、多尺度世界状态预测的可能架构。变量 代表观察序列。第一级网络,称为 JEPA-1,使用低级表征执行短期预测。第二级网络 JEPA-2 使用高级表征执行长期预测。人们可以设想这种类型的架构具有许多层,可能使用卷积和其他模块,并使用层间的时间池化来粗粒化表征并执行长期预测。训练可以逐层或全局进行,使用任何用于 JEPA 的非对比方法。
我认为,在多个抽象层次上表征世界状态序列的能力对于智能行为至关重要。通过世界状态和动作的多级表征,复杂的任务可以分解为越来越详细的子任务,并在了解局部条件时实例化为动作序列。例如,规划一项复杂的任务,如通勤上班,可以分解为开车去火车站、乘火车等。开车去火车站可以分解为走出家门、启动汽车和驾驶。走出家门需要站起来、走到门口、打开门等。这种分解一直下降到毫秒级的肌肉控制,只有在感知到相关环境条件(障碍物、交通灯、移动物体等)时才能实例化。
4.7 分层规划
如果我们的世界模型能够分层执行预测,它能被用来分层执行 Mode-2 推理和规划吗?
分层规划是一个困难的话题,解决方案很少,其中大多数要求预定义动作的中间词汇。但如果遵循深度学习哲学,那些动作计划的中间表征也应该被学习。
图 16 显示了用于分层 Mode-2 规划的可能架构,它可以利用多尺度世界模型的分层性质。
感知通过编码器级联被编码为多个抽象层次的表征:
$$s[0] = Enc_1(x) \quad ; \quad s_2[0] = Enc_2(s[0]) \;
预测发生在所有层级。更高级别执行长期预测,而较低级别执行短期预测。整体任务由高级目标定义,在图中描绘为 。顶层推断出一系列高级动作 以优化此目标。这些高级“动作”并非真实动作,而是较低级别预测状态的目标。人们可以认为它们是较低级别状态为了使高级别预测准确而必须满足的条件。这些条件是否满足可以通过成本模块 和 计算。它们接收较低级别的状态 和高级条件 ,并衡量状态在多大程度上满足该条件。定义了这些子目标后,较低级别可以执行推理并找到一个最小化中级子目标 和 的低级动作序列。
刚刚描述的过程是自顶向下且贪婪的。但人们可以有利地迭代优化,以便联合优化所有层级中的动作。成本模块可以由配置器针对手头的情况进行配置。
动作仅仅是下一层级需要满足的条件这一思想,实际上在控制理论中是一个古老的思想。例如,经典的比例伺服机构可以被视为被赋予了一个目标状态。二次成本衡量目标与当前状态之间的平方距离,而控制仅仅与成本相对于动作变量的负梯度成正比。
4.8 处理不确定性
现实世界并非完全可预测。未来世界状态预测中的不确定性可能归因于多种原因:
- 世界本质上是随机的(偶然不确定性,类型 1)
- 世界是确定性的但混乱的,因此在没有无限精确感知的情况下难以预测(偶然不确定性,类型 2)
- 世界是确定性的但部分可观测的(偶然不确定性,类型 3)。
- 世界是完全可观测的,但传感器只提供关于世界状态的部分信息(认知不确定性,类型 1)
- 感知模块提取的世界状态表征不包含准确预测所需的全部信息(认知不确定性,类型 2)。
- 由于其表征能力的限制(有限理性或认知不确定性,类型 3),世界模型是不准确的。
- 由于在有限数据量下进行训练,世界模型是不准确的(认知不确定性,类型 4)。
强化学习文献中的大部分内容集中在处理环境的随机性上。通常从一开始就假设模型、评论家和策略必须表征分布。在目前的工作中,我们将预测变量的可能随机性推入潜在变量中,该变量可以被优化、预测或采样。这就是机器学习文献中通常所说的“重参数化技巧”。我们在这里不需要使用这个技巧,因为我们将预测的潜在变量参数化视为根本性的。
图 17 代表了存在不确定性时的分层规划片段。给定层级和时间步长的预测,例如 ,需要对相应的潜在变量 进行采样。样本可能来自其负对数是正则化器 的分布。正则化器的参数可能是恒定的(例如固定的高斯分布),从当前可用数据中使用摊销推理预测(例如参数由 计算或由配置器产生的多项式或高斯分布)。使用先前的预测来配置潜在正则化器会使系统偏向于生成“良好”的轨迹。
随着预测的进行,生成的状态轨迹数量可能会呈指数级增长:如果每个潜在变量有 个可能的离散值,则可能轨迹的数量将增长为 ,其中 是时间步数。可以采用定向搜索和剪枝策略,如在经典的蒙特卡洛树搜索 (MCTS) 中一样。在连续潜在变量的情况下,人们可以从正则化器定义的连续分布中采样潜在变量。
给定所有潜在变量的样本,可以推断出每个层级的最优动作序列。然而,预测过程可能需要针对潜在变量的多次抽取重复进行,以覆盖合理结果的集合。推理过程可用于多次预测,以产生一个不仅最小化预期成本,而且还最小化预期成本不确定性的动作。
4.8.1 世界模型架构
世界模型架构的细节应该取决于智能体所处的环境类型。
JEPA 中的最佳模块架构很可能应该包括某种形式的门控或动态路由机制。
例如,处理视频中低级、短期预测的最佳方式是提取简单的局部特征向量,并根据预测的运动将这些特征向量从一帧移动到下一帧。潜在变量可以编码位移图,它可以调节一帧与下一帧之间的路由连接。
对于更高级别抽象的长期预测,相关的特征是对象及其交互。演变最好由 Transformer 架构建模,该架构具有对排列等变的特性,并且适合捕获离散对象之间的交互(Vaswani et al., 2017; Carion et al., 2020; Battaglia et al., 2016)。
将世界模型与自我模型分离: 自然界是复杂且有些不可预测的,需要一个带有潜在变量的强大模型来解释这种不可预测性。
另一方面,智能体本身在某种程度上是可预测的:对效应器的特定动作通常会产生可以确定性预测的运动。这表明智能体应该拥有一个独立的自我模型,也许不需要潜在变量 (Sobal et al., 2022),因为动作对本体感觉的影响比外部世界的演变或动作对它的影响更容易预测。
反过来,智能体拥有的自我模型可以用作多智能体场景中其他智能体模型的模板。
4.9 跟踪世界状态
传统上,深度学习架构中的模块通过向量或多维数组来通信状态。但当被建模对象的状态从一个时间到下一个时间仅发生微小变化时,这往往是一种非常低效的方法。
智能体的典型动作只会修改世界状态的一小部分。如果一个瓶子正从厨房移动到餐厅,瓶子、厨房和餐厅的状态将被修改。但世界的其余部分将不受影响。
这表明世界状态应该保持在某种可写内存中。每当发生事件时,只有受事件影响的世界状态内存部分需要更新,而其余部分应保持不变。
传统的键值关联记忆可用于此目的,类似于在记忆增强网络 (Bordes et al., 2015; Sukhbaatar et al., 2015; Miller et al., 2016) 和实体网络 (Henaff et al., 2017) 的背景下所提出的。世界模型在给定时间步长的输出是一组查询-值对 ,用于修改世界状态内存中的现有条目,或添加新条目。给定查询 ,世界状态内存返回:
其中 是键, 是存储的值,函数 衡量键和查询之间的散度或不相似度,向量 包含标量系数 ,函数 执行某种竞争性归一化或阈值处理,例如常用的 ,其中 是一个正的常数。
使用查询(或地址) 将值 写入内存可以通过更新现有条目来完成:
函数 可以简单地为 。
如果查询距离所有键都很远,内存可能会分配一个新条目,其键为 ,对应的值为 。上述 Normalize 函数示例中的 常数可以用作可接受的键-查询散度的阈值。
人们可以将每个条目视为代表世界中的一个实体。在上述瓶子的例子中,世界模型可能包含键 ,分别代表瓶子、厨房和餐厅。 的初始值将其位置编码为“厨房”, 的初始值将其内容编码为包括瓶子, 的初始值将其内容编码为不包括瓶子。事件发生后,位置和内容被更新。
所有这些操作都可以以可微的方式完成,因此将允许梯度通过它们进行反向传播。
4.10 数据流
关于世界的许多知识可以通过纯观察来学习。物理对象的运动定律原则上可以从观察中推导出来,而无需干预。但高效地训练世界模型可能需要更主动或“代理式”的信息收集。
可以列出智能体可以用来了解世界如何运作的五种信息收集模式:
- 被动观察: 智能体被馈送传感器流(例如视频、音频等)。
- 主动注视: 智能体被馈送一个流,其中的注意力焦点可以在不影响环境的情况下被引导。例如,在观看场景的同时能够定向视觉和声音传感器,或者被馈送一个宽视角、高分辨率的视频和/或音频流,其中的注意力焦点可以被引导。
- 被动代理: 观察到另一个在环境中行动的智能体的感官流,从而能够推断智能体动作对环境状态的因果影响。
- 主动自我运动: 智能体从真实或虚拟环境中接收感官流,其中的传感器位置可以在不显著影响环境的情况下被修改。这可能包括可操纵的主动传感器(例如测距传感器、热传感器、化学传感器)以及触摸传感器。
- 主动代理: 受智能体动作影响的感官流。这使得能够建立因果模型,智能体可以在其中学习预测其动作的后果。这种模式将探索-利用困境推到了最前沿。
在复杂的环境中,收集足够的被动数据以使世界模型捕获环境行为的足够部分可能并不实际。模式 2、4 和 5 允许智能体收集最大限度地提高其对环境理解的信息。但这样做可能需要驱动注意力、好奇心和探索的内在动机模块,进入世界模型预测目前不准确或不确定的状态空间角落。
主要悬而未决的问题是,使用被动观察(模式 1、2、4)可以学习到多少,需要多少自我运动(模式 3),以及需要多少完全代理(模式 5)。
5 设计和训练参与者
参与者模块的作用是三重:
- 在给定世界模型为 Mode-2 动作产生的预测的情况下,推断最小化成本的最优动作序列。
- 产生代表智能体不知道的世界状态部分的潜在变量的多个配置。
- 训练用于产生 Mode-1 动作的策略网络。
动作和潜在变量之间没有概念上的区别。两组变量的配置都必须由参与者探索。对于潜在变量,必须探索配置以在不确定性下进行规划。对于动作变量,必须探索配置以产生最小化成本的最优配置。在对抗性场景(如游戏)中,必须探索最大化成本的潜在配置。实际上,参与者扮演了优化器和探索者的角色。
当世界模型和成本表现良好时,参与者模块可以使用基于梯度的优化过程来推断最优动作序列。为此,它接收通过反向传播梯度通过成本和展开的世界模型计算出的成本梯度估计。它使用这些估计来更新动作序列。
当世界模型或成本表现不佳时,基于梯度的最优动作序列搜索可能会失败。在这种情况下,可以应用另一种搜索/规划方法。如果动作空间是离散的或可以离散化,可以使用动态规划方法或近似动态规划方法,如束搜索或蒙特卡洛树搜索。实际上,在最优控制、机器人技术或“经典”人工智能背景下开发的任何规划方法都可以用于此背景。
一旦通过规划/推理/优化过程获得了最优动作序列,就可以使用这些动作作为目标来训练策略网络。策略网络随后可用于快速行动,或仅仅用于在优化阶段之前将建议的动作序列初始化为良好的起点。可以为多个任务训练多个策略网络。
参与者还产生潜在变量的配置。这些潜在变量代表了智能体不知道的世界状态部分。理想情况下,参与者会系统地探索潜在变量的可能配置。理想情况下,图 17 中的潜在变量正则化器 和 将代表可以从中采样潜在变量的对数先验。但与策略网络类似,人们可以设计一个潜在摊销推理模块,学习潜在变量的分布。良好的分布将产生合理的预测。分布的参数可能取决于当时所有可用的变量。
6 设计配置器
配置器是智能体的主要控制器。它接收来自所有其他模块的输入,并调节它们的参数和连接图。这种调节可以路由信号、激活子网络、聚焦注意力等。在预测器和感知编码器的上层是 Transformer 块的场景中,配置器输出可能构成这些 Transformer 块的额外输入标记,从而调节它们的连接图和功能。
配置器模块是必要的,原因有二:硬件重用和知识共享。能够将相同的电路重用于多个任务具有明显的优势,特别是如果任务可以按顺序完成,并且资源(例如参数内存)有限。但还有另一个优势:知识重用。一个合理的假设是,为给定环境训练的世界模型可以通过微小的变化用于一系列不同的任务。人们可以想象一个针对该环境的“通用”世界模型,其中一小部分参数由配置器针对手头的任务进行调节。这比为每种技能配备单独的世界模型在数据效率和计算效率上更高。缺点是智能体一次只能完成一个任务。
配置器可以通过调节各个层级的参数来为特定任务引导感知模块。人类感知系统可以针对特定任务进行引导,例如在杂乱的抽屉中检测物品、在森林中检测水果或猎物、阅读、计数某些事件、组装两个零件等。对于需要快速检测简单基元的任务,配置器可以调节卷积架构中低层级的权重。对于涉及满足对象之间关系的任务(例如用螺丝组装两个零件),配置可以通过调节高级 Transformer 模块中的标记来执行。
世界模型的预测器部分必须能够根据手头的任务执行广泛的功能。对于在低抽象级别执行短期预测的预测器,配置可能意味着动态信号路由。在低级视网膜特征阵列表征中,预测可以简化为单个特征向量的局部位移,并伴随这些向量的小转换。这可以通过局部门控/路由电路有利地实现。对于更高级别抽象的长期预测,使用 Transformer 架构可能更可取。Transformer 块特别适用于对象交互的对象级推理。原因是 Transformer 块的功能对排列是等变的。由于该属性,人们不需要担心哪个对象被分配给哪个输入标记:结果将与输入分配一致且一致。模型驱动机器人技术的最新工作提出了使用在整个轨迹级别上运行的 Transformer,对注意力电路施加约束,以配置预测器进行因果预测或其他任务 (Janner et al., 2021)。
方便的是,Transformer 块的功能很容易通过添加额外的输入标记来配置。这些额外的输入具有调节网络其余部分使用的连接图的效果,从而允许指定广泛的输入-输出功能。
配置器最重要的功能也许是为智能体设置子目标并为该子目标配置成本模块。如第 3.2 节所述,使成本可配置的一种简单方法是调节基本成本子模块的线性组合的权重。这可能适用于不可变的内在成本子模块:允许对内在成本进行复杂的调节可能会使智能体的基本驱动力难以控制,包括实现安全护栏的成本项。相比之下,人们可以想象更复杂的架构,允许成本的可训练评论家部分被灵活调节。与预测器一样,如果高级成本被表述为对象之间的一组期望关系(“螺母是否安装在螺丝上?”),人们可以使用训练来衡量世界状态偏离要满足条件的程度的 Transformer 架构。与预测器一样,额外的标记输入可用于调节该功能。
一个未回答的问题是,配置器如何学习将复杂的任务分解为可以由智能体单独完成的子目标序列。我将把这个问题留给未来的研究。
7 相关工作
本文提出的大多数思想并非新颖,已在认知科学、神经科学、最优控制、机器人技术、人工智能和机器学习(特别是强化学习)中以各种形式进行了详细讨论。
本文的主要原创贡献也许在于:
- 一种整体的认知架构,其中所有模块都是可微的,且许多模块是可训练的。
- H-JEPA:一种用于预测性世界模型的非生成式分层架构,它学习在多个抽象层次和多个时间尺度上的表征。
- 一种非对比式自监督学习范式,它产生的表征既具有信息量又具有可预测性。
- 一种将 H-JEPA 作为不确定性下分层规划的预测性世界模型基础的方法。
以下是尝试将本提案与相关先前工作联系起来的尝试。鉴于提案的范围,参考文献不可能详尽无遗。
7.1 训练世界模型、模型预测控制、分层规划
最优控制中使用模型可以追溯到 Kelley-Bryson 方法的早期(参见 (Bryson and Ho, 1969) 及其参考文献,或综述 (Morari and Lee, 1997))。一些方法允许在线系统识别 (Richalet et al., 1978)。
使用神经网络学习控制模型是一个古老的想法,可以追溯到 20 世纪 90 年代初 (Jordan and Rumelhart, 1992; Narendra and Parthasarathy, 1990; Miller et al., 1995)。
在最优控制的背景下,学习类似 Mode-1 的策略网络被称为直接逆控制。
在强化学习的背景下,使用预测模型对动作进行 Mode-2 风格推理的想法也是一个古老的想法,例如 Sutton 的 Dyna 架构 (Sutton, 1991)。参见 (Bertsekas, 2019) 以获取详尽的综述。
可学习模型的想法最近在各种背景下重新引起了兴趣 (Ha and Schmidhuber, 2018b; Ha and Schmidhuber, 2018a; Hafner et al., 2018; Hafner et al., 2020)(参见 (Moerland et al., 2020) 以获取基于模型的强化学习的最新综述)。
学习世界模型在机器人技术背景下尤为重要,特别是在抓取和操作方面,其中样本效率至关重要,且模拟往往不准确。事实上,由于经典的强化学习方法在现实世界应用中需要太多的试验,基于机器学习的机器人研究中出现了用于控制的习得模型的有趣进展 (Agrawal et al., 2016; Finn and Levine, 2017; Chua et al., 2018; Srinivas et al., 2018; Yu et al., 2020; Yarats et al., 2021)。有关最新综述,请参见 (Levine, 2021) 及其参考文献。
一个困难的设置是主要输入是视觉,并且必须从视频中学习世界模型。早期尝试在没有潜在变量的情况下从简单视频训练预测模型产生了模糊的预测 (Lerer et al., 2016)。为了处理预测中的不确定性,可以使用各种风格的潜在变量模型,例如生成对抗网络 (GAN) (Goodfellow et al., 2014)、变分自动编码器 (VAE) (Kingma and Welling, 2013)、向量量化 VAE (VQ-VAE) (van den Oord et al., 2017)。这些方法的变体已被应用于视频预测,并有助于使用 GAN (Mathieu et al., 2015; Luc et al., 2020)、VAE (Babaeizadeh et al., 2017; Denton and Fergus, 2018; Henaff et al., 2019) 或 VQ-VAE (Walker et al., 2021) 来表征多模态输出并减少模糊性。尽管这些方法中的许多尚未应用于控制问题,但有些已被应用于自动驾驶的车辆轨迹预测 (Henaff et al., 2019; Mercat et al., 2020),或各种机器人控制任务 (Oh et al., 2015; Fragkiadaki et al., 2015; Agrawal et al., 2016; Finn et al., 2016; Nagabandi et al., 2017; Babaeizadeh et al., 2017; Srinivas et al., 2018)。与所提出的 JEPA 不同,这些模型是生成式的。如何表征预测中的不确定性的关键问题仍然存在。
正则化潜在变量模型的替代方案是对比方法,例如对比预测编码 (CPC) (Hénaff et al., 2019),它已被应用于通过视频预测学习视觉表征 (van den Oord et al., 2018)。
为了解决多模态/模糊性问题,其他工作提出了在表征空间中执行视频预测。在一些工作中,表征空间是从以监督模式训练的视觉管道中获得的,例如用于执行语义分割 (Luc et al., 2017; Luc et al., 2018)。不幸的是,对预训练视觉管道的需求降低了这些方法通过观察学习世界模型的通用可用性。
本着与 JEPA 相同的精神,已经有关于自动学习视频帧表征以便它们可以被轻松预测的提议。这些提议通常仅限于学习低级特征,并且通常使用通过解码器的重构作为防止崩溃的方法 (Goroshin et al., 2015a; Srivastava et al., 2015)。一些作者提议使用时间不变性(或一致性)将图像区域的内容与其实例化参数分离开来 (Wiskott and Sejnowski, 2002; Gregor and LeCun, 2010a; Goroshin et al., 2015b)。
至少有一项最近的工作已将非对比 SSL 方法应用于机器人控制的联合嵌入架构,并取得了一些成功 (Pari et al., 2021; ?)。
应用于联合嵌入和预测的对比方法已成功应用于语音识别 (Baevski et al., 2020)(参见 (Mohamed et al., 2022) 以获取 SSL 到语音的最新综述)。
为了执行状态轨迹预测,最近的工作提倡使用 Transformer,正如本文所提出的那样。Transformer 是表征交互中离散对象动态的理想选择,并已成功应用于汽车轨迹的预测 (Mercat et al., 2020)。
一个有趣的提议是轨迹 Transformer 架构,其中 Transformer 被馈入整个片段的预测状态序列 (Janner et al., 2021)。注意力模式可以被约束,以便强制系统只关注过去,从而可以以因果方式操作(不看未来),并训练以从先前观察或预测的状态、动作和成本中预测下一个状态、动作和成本。
分层规划是一个很大程度上未解决的问题。Wayne 和 Abbott 提出了一种架构,该架构使用一系列训练有素的前向模型,为较低层级指定中间目标 (Wayne and Abbott, 2014)。一些最近的工作根据姿态参数为机器人指定中间目标 (Gehring et al., 2021)。一个更近期的提议是 Director 系统 (Hafner et al., 2022),它包含一个通过强化学习端到端训练的分层世界模型和规划架构。
训练智能体的内在动机思想已在机器人技术背景下进行了研究 (Gottlieb et al., 2013)。内在成本的存在提供了一种可微且有效的方法来引导智能体遵循某些行为并学习某些技能。
7.2 能量模型和联合嵌入架构
对于许多作者来说,能量模型 (EBM) 指定了一个概率模型,其分布是能量函数的归一化负指数。
在本文中,EBM 指定了一个更广泛的模型类别,它们将能量函数视为根本,并通过学习直接操纵其景观。过去已经提出了许多直接操纵能量的方法。事实上,所有传统的基于优化的学习方法都可以解释为能量模型 (LeCun et al., 2006)。特别是,结构预测问题的判别训练方法可以表述为 EBM (LeCun et al., 1998; LeCun et al., 2006)。
大多数用于无监督或自监督学习的 EBM 方法都是对比式的。最早的例子是玻尔兹曼机 (Hinton and Sejnowski, 1983),它是一个对比训练的概率生成式能量模型。
以对比方法和互信息最大化方法训练的联合嵌入架构 (JEA) 历史悠久。第一个非对比 JEA 是 (Becker and Hinton, 1992),它基于最大化来自两个分支的表征之间的互信息度量,这两个分支看到了相同场景的不同视图。也许 JEA 的第一个对比方法是所谓的“孪生网络” (Bromley et al., 1994)。这是为了验证手写笔上的手写签名而进行对比训练的。
JEA 的思想在十多年里基本未被触及,直到它在我的小组 (Chopra et al., 2005; Hadsell et al., 2006) 和 Geoffrey Hinton 的小组 (Goldberger et al., 2005) 的一系列论文中被复兴。随着深度学习的重生,一些论文将 JEA 用于细粒度识别,包括人脸识别 (Taigman et al., 2014)。
随着 SSL 方法的出现,使用对比训练的 JEA 在过去几年中呈爆炸式增长,方法包括 PIRL (Misra and Maaten, 2020)、MoCo 和 MoCo-v2 (He et al., 2020; Chen et al., 2020b) 以及 SimCLR (Chen et al., 2020a)。
有些方法可以被视为“蒸馏”方法,其中孪生网络的一个分支是教师,其输出被用作另一个分支的目标。这包括输出向量被量化为离散聚类原型的方法(参见 (Caron et al., 2020) 及其前身)。
近年来,出现了一些新的非对比方法,例如 BYOL (Grill et al., 2020)。但本文提倡的非对比方法通过最大化嵌入的信息内容来防止崩溃。这包括 Barlow Twins (Zbontar et al., 2021)、VICReg (Bardes et al., 2021)、基于白化的方法 (Ermolov et al., 2021) 和最大编码率缩减方法(参见 (Dai et al., 2022) 及其参考文献)。
7.3 人类和动物认知
与人类学习相比,当前机器学习方法的局限性是显而易见的 (Lake et al., 2017a; Zaadnoordijk et al., 2022)。
幼儿很快就能学习抽象概念 (Murphy, 2002),以及允许他们导航、形成目标并规划复杂动作序列以实现这些目标的模型 (Gopnik and Meltzoff, 1997; Spelke and Kinzler, 2007; Carey, 2009; Gopnik et al., 2001)。
在认知科学中,大脑构建预测性世界模型的思想是一个普遍的思想,并激发了在机器中重现该过程的尝试 (Lake et al., 2017b; Orhan et al., 2020)。一些努力致力于构建视频数据集,以测试机器和婴儿的直观物理常识 (Riochet et al., 2019)。
规划能力是人类智能的一个研究充分的特征 (Mattar and Lengyel, 2022)。有证据表明,人们构建简化的世界表征进行规划,其中不相关的细节被抽象掉 (Ho et al., 2022)。
意识是一个相当投机的话题,因为定义什么是意识很困难。我不会推测所提出的架构的某个版本是否可能拥有可同化为意识的属性,而只会提到 Dehaene 及其合作者的工作,他们提出了两种他们称为 C1 和 C2 的意识类型。C1 主要与注意力的调节有关,而 C2 需要一种自我监控能力,也许可以同化为配置器模块在本文提案中需要做的事情 (Dehaene et al., 2021)。
8 讨论、局限性、更广泛的相关性
构建本文提案的认知架构,实例化所有细节,并使系统为非平凡任务工作,将不是一项容易的任务。成功之路很可能布满了不可预见的障碍。可能需要许多年才能全部解决。
8.1 提出的模型缺少什么?
需要做大量艰苦的工作来实例化所提出的架构并将其转化为功能系统。在所提出的架构规范内,可能存在看似无法解决的缺陷和陷阱。
第一个问题是分层 JEPA 是否可以从视频中构建和训练。它能学习第 4.1 节中提到的抽象概念层次结构吗?
关于 JEPA 的一个有些悬而未决的问题是,如何精确地正则化潜在变量以最小化其信息内容。提出了许多可能的机制:使潜在变量离散、低维、稀疏或随机。但不清楚哪种方法最终会是最好的。
目前的提案没有规定参与者推断潜在变量实例化和最优动作序列的特定方式。虽然所有模块的可微性使得原则上可以使用基于梯度的优化来推断最优动作序列,但优化问题在实践中可能非常困难。特别是,当动作空间是离散的,或者从动作到成本的函数高度非平滑时,基于梯度的方法可能无效,需要使用其他(无梯度)搜索方法(动态规划、信念传播、MCTS、SAT 等)。
在 Mode-2 规划/推理中实例化潜在变量的多个配置可能需要本文提案中未描述的额外机制。人类似乎被赋予了一种自发地循环通过感知替代解释的能力,正如内克尔立方体和其他具有几种同样合理的解释的视觉错觉所证明的那样。在本文模型的背景下,模糊感知的不同解释可能由潜在变量的不同值来表征。虽然人们可以想象许多探索性机制来系统地探索潜在变量值的空间,但这里没有描述这样的机制。
本文提案没有指定各种模块的架构细节。例如,预测器很可能需要在其微架构中进行某种动态路由和门控电路。用于低级表征的预测器可能必须专门化,以表征短期内可能发生的表征的小转换。处理更高级别表征的预测器模块可能需要更通用的架构来操作对象及其关系。但本文提案中没有指定这些。
类似地,短期记忆的精确架构和功能,以及它如何被用来表征关于世界状态的信念,有些模糊。原始记忆网络系统及其后继者包含了一个想法,即神经网络可以使用关联记忆作为工作记忆,在计算周期之间存储和检索关于世界状态的信念 (Bordes et al., 2015; Sukhbaatar et al., 2015)。但要使这样的架构为复杂的规划和控制工作可能很困难。
在当前提案的所有最不被理解的方面中,配置器模块是最神秘的。特别是,在规划复杂任务时,配置器应该识别子目标序列并配置智能体以连续完成这些子目标。具体如何做到这一点没有指定。
这仅仅是可预见问题的列表,但随着所提出的系统被组合在一起,许多问题和挑战将不可避免地浮出水面。
8.2 所提方法的更广泛相关性
尽管所提出的架构并非专门设计用于模拟人类和其他动物的自主智能、推理和学习,但人们可以得出一些相似之处。以下内容有些投机,旨在作为一种方式来连接激发本文工作的认知科学和神经科学中的一些概念。
8.2.1 这种架构能否成为动物智能模型的基础?
所提架构中的许多模块在哺乳动物大脑中都有执行类似功能的对应物。
感知模块对应于皮层的视觉、听觉和其他感觉区域,以及一些关联区域。世界模型和评论家对应于前额叶皮层的各个部分。内在成本模块对应于基底神经节中涉及奖励的结构,包括杏仁核。可训练评论家可能对应于前额叶皮层中涉及奖励预测的部分。短期记忆的功能与已知的海马体功能重叠。配置器可能对应于前额叶皮层中执行执行控制和调节注意力的结构。参与者重组了前运动皮层中阐述和编码运动计划的区域。
预测性世界模型的思想长期以来一直是认知科学中的一个突出概念,而预测编码的思想一直是神经科学中的一个突出概念。JEPA 架构和相应的非样本对比自监督学习方法与预测编码和高效编码的思想在某种程度上是一致的。
所提出的架构有一个单一的世界模型引擎,可以由配置器针对手头的任务进行配置。我曾论证过,这不仅可以通过硬件重用带来计算优势,还可以允许知识在多个任务之间共享。人类大脑中单一、可配置的世界模型引擎的假设可能解释了为什么人类本质上一次只能执行一个“有意识的”推理和规划任务。一个高度投机的想法是,意识的错觉可能是大脑中一个类似配置器的模块的副作用,该模块监督大脑其余部分的功能并针对手头的任务对其进行配置。也许如果大脑足够大,可以包含许多独立的、不可配置的世界模型,配置器将是不必要的,意识的错觉也会消失。
动物和人类情感的基质是什么?瞬时情感(例如疼痛、快乐、饥饿等)可能是大脑结构的结果,这些结构在所提架构中发挥类似于内在成本模块的作用。其他情感,如恐惧或愉悦,可能是由功能类似于可训练评论家的大脑结构对结果的预期所致。
存在一个通过搜索最优动作来驱动智能体行为的成本模块,这表明本文提出的这类自主智能体将不可避免地拥有情感的等价物。以类似于动物和人类的方式,机器情感将是内在成本或来自可训练评论家的结果预期的产物。
8.2.2 这能成为通往机器常识的道路吗?
一种普遍的观点是,当前的任何人工智能系统都不具备任何程度的常识,即使是在家猫身上观察到的水平。动物似乎能够获得足够的关于世界如何运作的背景知识,从而表现出某种程度的常识。相比之下,人工智能系统,即使是(预)训练了自监督模式(例如从文本中),似乎也表现出非常有限的常识水平,使它们有些脆弱。
例如,大型语言模型 (LLM) 似乎拥有从书面文本中提取的惊人数量的背景知识。但许多人类常识知识并没有在任何文本中表征,而是源于我们与物理世界的互动。因为 LLM 对底层现实没有直接经验,它们表现出的常识知识类型非常浅薄,并且可能与现实脱节。
常识的一种可能表征是使用世界模型来填补空白的能力,例如预测未来,或更一般地填补感知或记忆中不可用的关于世界的信息。有了这个定义,常识就是一种从世界模型集合或从可配置以处理手头情况的单一模型引擎中涌现的能力。这种常识观完全处于“接地智能”的阵营中:常识是从低抽象层次到高抽象层次,一直到通过语言获得的知识的模型集合。
应用于可配置 H-JEPA 的 SSL 能否构成机器常识的基质?一个训练有素且配置得当的 H-JEPA 能否嵌入足够的预测知识并捕获关于世界的足够依赖关系,从而表现出某种程度的常识?
我推测,常识可能源于学习捕获世界中观察结果的自洽性和相互依赖性的世界模型,从而允许智能体填补缺失的信息并检测其世界模型的违规行为。
8.3 这全是关于缩放吗?奖励真的足够吗?
本节回顾了近年来提出的通往人类水平智能的几条潜在路径。训练用于预测文本和其他模态的大型 Transformer 架构的惊人力量导致一些人声称我们仅仅需要扩展这些模型 (Brown et al., 2020; Brown et al., 2020)。强化学习在游戏和其他简单环境中的惊人力量导致其他人声称奖励就足够了 (Silver et al., 2021)。最后,