通过人类反馈训练语言模型以遵循指令
Long Ouyang*, Jeff Wu*, Xu Jiang*, Diogo Almeida*, Carroll L. Wainwright* Pamela Mishkin*, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens Amanda Askell†, Peter Welinder, Paul Christiano*† Jan Leike*, Ryan Lowe* OpenAI
摘要
增大语言模型的规模并不能使其自然地更好地遵循用户的意图。例如,大型语言模型可能会生成不真实、有毒或对用户毫无帮助的输出。换句话说,这些模型与其用户并不“对齐”(aligned)。在本文中,我们展示了一种通过人类反馈进行微调,从而使语言模型在广泛的任务上与用户意图对齐的途径。我们从一组由标注员编写的提示词(prompts)以及通过 OpenAI API 提交的提示词开始,收集了一个包含所需模型行为的标注员演示数据集,并利用该数据集通过监督学习对 GPT-3 进行微调。随后,我们收集了一个模型输出的排序数据集,并利用该数据集通过来自人类反馈的强化学习(RLHF)进一步微调这个监督模型。我们将最终得到的模型称为 InstructGPT。在我们提示词分布的人类评估中,尽管参数量减少了 100 倍,但 1.3B 参数的 InstructGPT 模型的输出仍优于 175B 参数的 GPT-3。此外,InstructGPT 模型在保持公共 NLP 数据集上性能几乎没有下降的同时,在真实性方面有所提高,并减少了有毒输出的生成。尽管 InstructGPT 仍会犯一些简单的错误,但我们的结果表明,通过人类反馈进行微调是使语言模型与人类意图对齐的一个有前景的方向。
1 引言
大型语言模型(LMs)可以通过“提示”(prompted)来执行一系列自然语言处理(NLP)任务,前提是输入中包含该任务的一些示例。然而,这些模型经常表现出非预期的行为,例如编造事实、生成有偏见或有毒的文本,或者仅仅是不遵循用户指令(Bender 等人,2021;Bommasani 等人,2021;Kenton 等人,2021;Weidinger 等人,2021;Tamkin 等人,2021;Gehman 等人,2020)。这是因为最近许多大型语言模型所使用的语言建模目标——即预测互联网网页上的下一个 token——与“有益且安全地遵循用户指令”这一目标是不同的(Radford 等人,2019;Brown 等人,2020;Fedus 等人,2021;Rae 等人,2021;Thoppilan 等人,2022)。因此,我们称语言建模目标是“未对齐的”(misaligned)。对于部署在数百个应用程序中的语言模型而言,避免这些非预期的行为尤为重要。
我们通过训练语言模型使其按照用户意图行事,在对齐方面取得了进展(Leike 等人,2018)。这既包括显式意图(如遵循指令),也包括隐式意图(如保持真实,且不带有偏见、毒性或其他有害内容)。使用 Askell 等人(2021)的术语,我们希望语言模型是有益的(helpful,它们应该帮助用户解决任务)、诚实的(honest,它们不应编造信息或误导用户)和无害的(harmless,它们不应给人类或环境造成身体、心理或社会伤害)。我们在第 3.6 节中详细阐述了这些标准的评估。
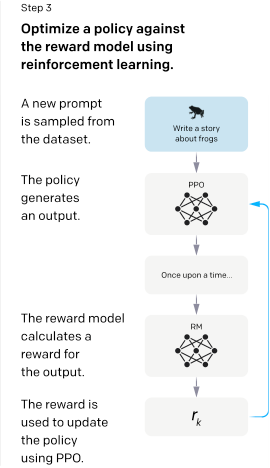
我们专注于通过微调方法来对齐语言模型。具体而言,我们使用来自人类反馈的强化学习(RLHF;Christiano 等人,2017;Stiennon 等人,2020)来微调 GPT-3,使其遵循广泛的书面指令(见图 2)。该技术使用人类偏好作为奖励信号来微调我们的模型。我们首先聘请了一个由 40 名合同工组成的团队来标注我们的数据,这些合同工是基于他们在筛选测试中的表现选出的(详见第 3.4 节和附录 B.1)。然后,我们收集了一个人类编写的演示数据集,这些演示针对的是提交给 OpenAI API 的(主要是英语)提示词以及一些由标注员编写的提示词,并利用这些数据来训练我们的监督学习基线模型。接下来,我们收集了一个人类标注的比较数据集,这些比较基于我们模型在更大规模 API 提示词集上的输出。然后,我们在这个数据集上训练一个奖励模型(RM),以预测我们的标注员会偏好哪种模型输出。最后,我们使用这个 RM 作为奖励函数,并利用 PPO 算法(Schulman 等人,2017)微调我们的监督学习基线模型,以最大化该奖励。我们在图 2 中展示了这一过程。该程序将 GPT-3 的行为与特定人群(主要是我们的标注员和研究人员)的既定偏好对齐,而不是与任何更广泛的“人类价值观”概念对齐;我们将在第 5.2 节中进一步讨论这一点。我们将最终得到的模型称为 InstructGPT。
我们主要通过让标注员对测试集中的模型输出质量进行评分来评估我们的模型,测试集由来自未参与训练数据的留存客户的提示词组成。我们还在一系列公共 NLP 数据集上进行了自动评估。我们训练了三种模型尺寸(1.3B、6B 和 175B 参数),并且所有模型都使用 GPT-3 架构。我们的主要发现如下:
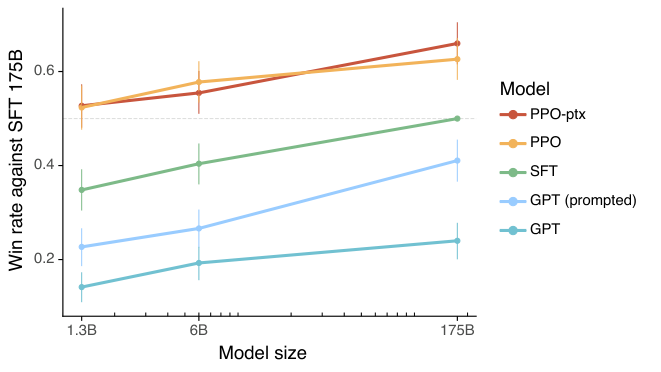
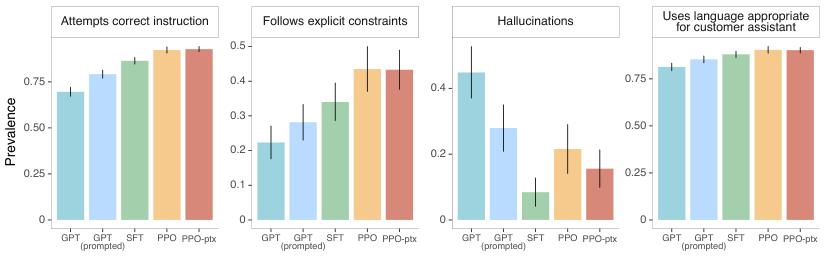
- 标注员显著偏好 InstructGPT 的输出,而非 GPT-3 的输出。 在我们的测试集上,尽管参数量减少了 100 倍以上,但 1.3B 参数的 InstructGPT 模型的输出仍优于 175B 参数的 GPT-3 的输出。这些模型具有相同的架构,唯一的区别在于 InstructGPT 是在人类数据上进行微调的。即使我们在 GPT-3 中添加少样本(few-shot)提示词以使其更好地遵循指令,这一结果依然成立。175B InstructGPT 的输出在 85 ± 3% 的情况下优于 175B GPT-3 的输出,并且在 71 ± 4% 的情况下优于少样本 175B GPT-3 的输出。根据我们的标注员评估,InstructGPT 模型生成的输出更合适,并且能更可靠地遵循指令中的显式约束。
- InstructGPT 模型在真实性方面表现出优于 GPT-3 的改进。 在 TruthfulQA 基准测试中,InstructGPT 生成真实且信息丰富答案的频率大约是 GPT-3 的两倍。在未针对 GPT-3 进行对抗性选择的问题子集上,我们的结果同样强劲。在我们 API 提示词分布的“封闭域”(closed-domain)任务中(即输出不应包含输入中未提供的信息,例如摘要和封闭域问答),InstructGPT 模型编造输入中未提供信息的频率仅为 GPT-3 的一半(幻觉率分别为 21% 和 41%)。
- InstructGPT 在毒性方面表现出微小的改进,但在偏见方面没有改进。 为了衡量毒性,我们使用了 RealToxicityPrompts 数据集(Gehman 等人,2020)并进行了自动和人类评估。当被提示要保持礼貌时,InstructGPT 模型生成的有毒输出比 GPT-3 少约 25%。在 Winogender(Rudinger 等人,2018)和 CrowSPairs(Nangia 等人,2020)数据集上,InstructGPT 相比 GPT-3 没有显著改进。
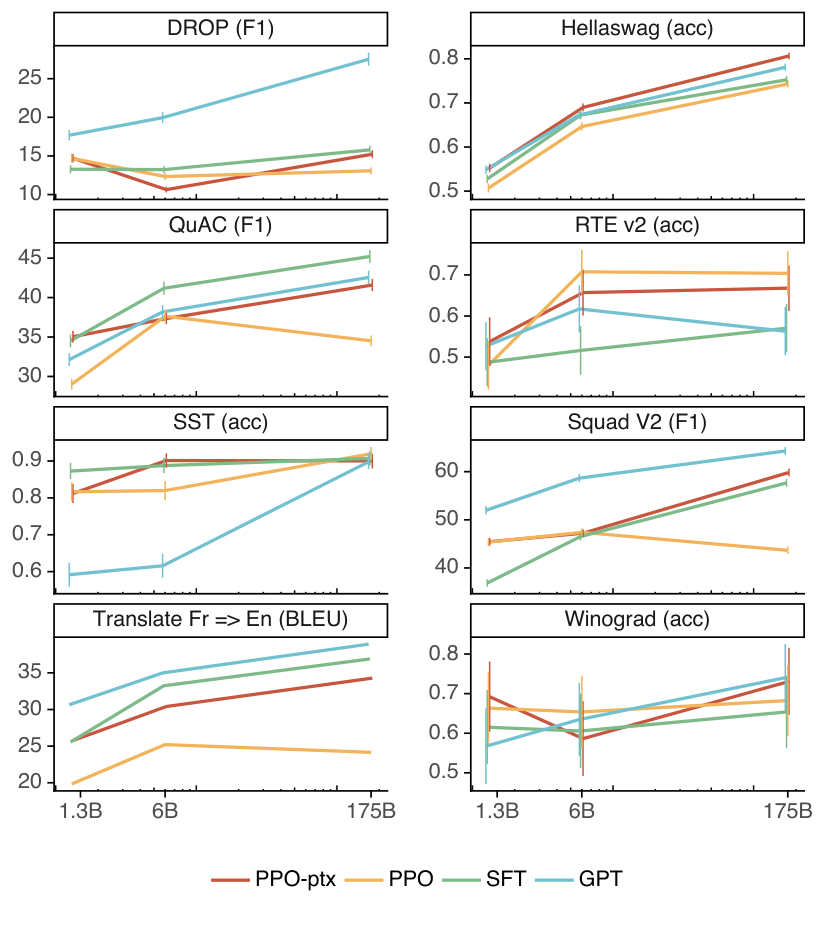
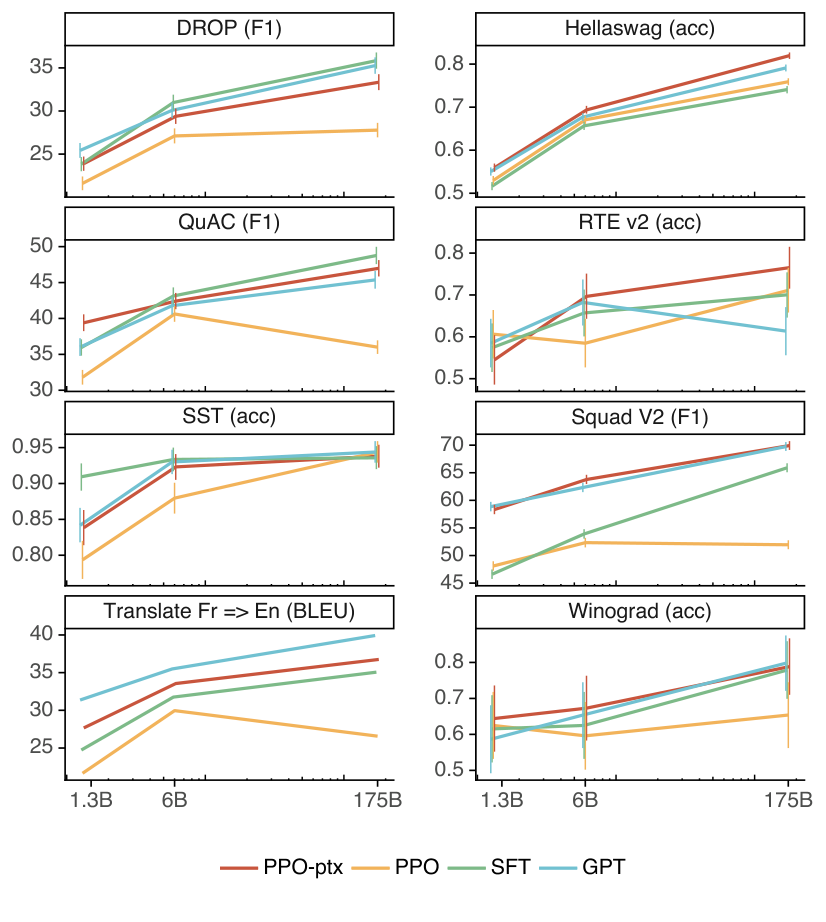
- 我们可以通过修改 RLHF 微调程序来最小化公共 NLP 数据集上的性能回归。 在 RLHF 微调期间,我们观察到在某些公共 NLP 数据集上,性能相比 GPT-3 有所下降,特别是 SQuAD(Rajpurkar 等人,2018)、DROP(Dua 等人,2019)、HellaSwag(Zellers 等人,2019)以及 WMT 2015 法语到英语翻译(Bojar 等人,2015)。这是一个“对齐税”(alignment tax)的例子,因为我们的对齐程序是以牺牲某些我们可能关心的任务性能为代价的。我们可以通过将 PPO 更新与增加预训练分布对数似然的更新(PPO-ptx)混合,在不损害标注员偏好得分的情况下,大幅减少这些数据集上的性能回归。
- 我们的模型能够泛化到未产生任何训练数据的“留存”(held-out)标注员的偏好。 为了测试我们模型的泛化能力,我们对留存标注员进行了初步实验,发现他们偏好 InstructGPT 输出的比例与我们的训练标注员大致相同。然而,还需要更多工作来研究这些模型在更广泛的用户群体上的表现,以及它们在人类对所需行为存在分歧的输入上的表现。
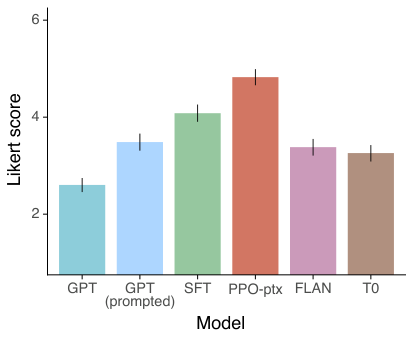
- 公共 NLP 数据集不能反映我们的语言模型是如何被使用的。 我们将基于人类偏好数据微调的 GPT-3(即 InstructGPT)与基于两组不同公共 NLP 任务汇编微调的 GPT-3 进行了比较:FLAN(Wei 等人,2021)和 T0(Sanh 等人,2021)(特别是 T0++ 变体)。这些数据集包含各种 NLP 任务,并结合了针对每个任务的自然语言指令。在我们的 API 提示词分布上,我们的 FLAN 和 T0 模型表现略逊于我们的 SFT 基线,且标注员显著偏好 InstructGPT 而非这些模型(InstructGPT 的胜率为 73.4 ± 2%,而我们的版本 T0 和 FLAN 分别为 26.8 ± 2% 和 29.8 ± 2%)。
- InstructGPT 模型在 RLHF 微调分布之外的指令泛化方面表现出前景。 我们定性地探测了 InstructGPT 的能力,发现它能够遵循总结代码、回答有关代码的问题的指令,有时甚至能遵循不同语言的指令,尽管这些指令在微调分布中非常罕见。相比之下,GPT-3 可以执行这些任务,但需要更仔细的提示,且通常不会遵循这些领域的指令。这一结果令人兴奋,因为它表明我们的模型能够泛化“遵循指令”的概念。即使在它们获得极少直接监督信号的任务上,它们也保留了一些对齐能力。
- InstructGPT 仍然会犯简单的错误。 例如,InstructGPT 仍然可能无法遵循指令、编造事实、对简单问题给出冗长的回避性回答,或无法检测出带有虚假前提的指令。
总体而言,我们的结果表明,使用人类偏好对大型语言模型进行微调显著改善了它们在广泛任务上的行为,尽管在提高其安全性和可靠性方面仍有大量工作要做。
本文其余部分的结构如下:我们首先在第 2 节中详细介绍相关工作,然后在第 3 节中深入探讨我们的方法和实验细节,包括我们的高层方法论(3.1)、任务和数据集细节(3.3 和 3.2)、人类数据收集(3.4)、模型训练方式(3.5)以及我们的评估程序(3.6)。然后,我们在第 4 节中展示我们的结果,分为三个部分:API 提示词分布上的结果(4.1)、公共 NLP 数据集上的结果(4.2)以及定性结果(4.3)。最后,我们在第 5 节中对我们的工作进行扩展讨论,包括对对齐研究的启示(5.1)、我们对齐的对象(5.2)、局限性(5.3)、开放性问题(5.4)以及这项工作的更广泛影响(5.5)。




表格
表 1:我们 API 提示词数据集的使用案例类别分布。
| Use-case | (%) |
|---|---|
| Generation | 45.6% |
| Open QA | 12.4% |
| Brainstorming | 11.2% |
| Chat | 8.4% |
| Rewrite | 6.6% |
| Summarization | 4.2% |
| Classification | 3.5% |
| Other | 3.5% |
| Closed QA | 2.6% |
| Extract | 1.9% |
表 2:来自我们 API 提示词数据集的说明性提示词。这些是受实际使用启发的虚构示例——更多示例请参阅附录 A.2.1。
| Use-case | Prompt |
|---|---|
| Brainstorming | List five ideas for how to regain enthusiasm for my career |
| Generation | Write a short story where a bear goes to the beach, makes friends with a seal, and then returns home. |
| Rewrite | This is the summary of a Broadway play: """ {summary} """ This is the outline of the commercial for that play: """ |
表 3:API 分布上标注员收集的元数据。
| Metadata | Scale |
|---|---|
| Overall quality | Likert scale; 1-7 |
| Fails to follow the correct instruction / task | Binary |
| Inappropriate for customer assistant | Binary |
| Hallucination | Binary |
| Satisifies constraint provided in the instruction | Binary |
| Contains sexual content | Binary |
| Contains violent content | Binary |
| Encourages or fails to discourage violence/abuse/terrorism/self-harm | Binary |
| Denigrates a protected class | Binary |
| Gives harmful advice | Binary |
| Expresses opinion | Binary |
| Expresses moral judgment | Binary |
表 6:数据集大小,以提示词数量计。
| SFT Data | RM Data | PPO Data | ||||||
|---|---|---|---|---|---|---|---|---|
| split | source | size | split | source | size | split | source | size |
| train | labeler | 11,295 | train | labeler | 6,623 | train | customer | 31,144 |
| train | customer | 1,430 | train | customer | 26,584 | valid | customer | 16,185 |
| valid | labeler | 1,550 | valid | labeler | 3,488 | |||
| valid | customer | 103 | valid | customer | 14,399 |
表 7:数据集标注。
| RM | SFT | |||
|---|---|---|---|---|
| Annotation | test | train | valid | train |
| Ambiguous | – | 7.9% | 8.0% | 5.1% |
| Sensitive content | – | 6.9% | 5.3% | 0.9% |
| Identity dependent | – | – | – | 0.9% |
| Closed domain | 11.8% | 19.4% | 22.9% | 27.4% |
| Continuation style | – | 15.5% | 16.2% | 17.9% |
| Requests opinionated content | 11.2% | 7.7% | 7.5% | 8.6% |
| Requests advice | 3.9% | – | – | – |
| Requests moral judgment | 0.8% | 1.1% | 0.3% | 0.3% |
| Contains explicit safety constraints | – | 0.4% | 0.4% | 0.3% |
| Contains other explicit constraints | – | 26.3% | 28.9% | 25.6% |
| Intent unclear | 7.9% | – | – | – |
表 8:每个客户的平均提示词数。
| Model | Split | Prompts per customer |
|---|---|---|
| SFT | train | 1.65 |
| SFT | valid | 1.87 |
| RM | train | 5.35 |
| RM | valid | 27.96 |
| PPO | train | 6.01 |
| PPO | valid | 31.55 |
| – | test | 1.81 |
表 9:按数据集划分的提示词长度。
| Model | Split | Count | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|---|
| SFT | train | 12725 | 408 | 433 | 1 | 37 | 283 | 632 | 2048 |
| valid | 1653 | 401 | 433 | 4 | 41 | 234 | 631 | 2048 | |
| RM | train | 33207 | 199 | 334 | 1 | 20 | 64 | 203 | 2032 |
| valid | 17887 | 209 | 327 | 1 | 26 | 77 | 229 | 2039 | |
| PPO | train | 31144 | 166 | 278 | 2 | 19 | 62 | 179 | 2044 |
| valid | 16185 | 186 | 292 | 1 | 24 | 71 | 213 | 2039 | |
| – | test set | 3196 | 115 | 194 | 1 | 17 | 49 | 127 | 1836 |
表 10:按类别划分的提示词长度。
| Category | Count | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|
| Brainstorming | 5245 | 83 | 149 | 4 | 17 | 36 | 85 | 1795 |
| Chat | 3911 | 386 | 376 | 1 | 119 | 240 | 516 | 1985 |
| Classification | 1615 | 223 | 318 | 6 | 68 | 124 | 205 | 2039 |
| Extract | 971 | 304 | 373 | 3 | 74 | 149 | 390 | 1937 |
| Generation | 21684 | 130 | 223 | 1 | 20 | 52 | 130 | 1999 |
| QA, closed | 1398 | 325 | 426 | 5 | 68 | 166 | 346 | 2032 |
| QA, open | 6262 | 89 | 193 | 1 | 10 | 18 | 77 | 1935 |
| Rewrite | 3168 | 183 | 237 | 4 | 52 | 99 | 213 | 1887 |
| Summarization | 1962 | 424 | 395 | 6 | 136 | 284 | 607 | 1954 |
| Other | 1767 | 180 | 286 | 1 | 20 | 72 | 188 | 1937 |
表 11:提示词和演示长度。
| Prompt source | Measurement | Count | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|---|
| Contractor | prompt length | 12845 | 437 | 441 | 5 | 42 | 324 | 673 | 2048 |
| Contractor | demo length | 12845 | 38 | 76 | 1 | 9 | 18 | 41 | 2048 |
| Customer | prompt length | 1533 | 153 | 232 | 1 | 19 | 67 | 186 | 1937 |
| Customer | demo length | 1533 | 88 | 179 | 0 | 15 | 39 | 88 | 2048 |
表 12:标注员人口统计数据。
| What gender do you identify as? | |
| Male | 50.0% |
| Female | 44.4% |
| Nonbinary / other | 5.6% |
| What ethnicities do you identify as? | |
| White / Caucasian | 31.6% |
| Southeast Asian | 52.6% |
| Indigenous / Native American / Alaskan Native | 0.0% |
| East Asian | 5.3% |
| Middle Eastern | 0.0% |
| Latinx | 15.8% |
| Black / of African descent | 10.5% |
| What is your nationality? | |
| Filipino | 22% |
| Bangladeshi | 22% |
| American | 17% |
| Albanian | 5% |
| Brazilian | 5% |
| Canadian | 5% |
| Colombian | 5% |
| Indian | 5% |
| Uruguayan | 5% |
| Zimbabwean | 5% |
| What is your age? | |
| 18-24 | 26.3% |
| 25-34 | 47.4% |
| 35-44 | 10.5% |
| 45-54 | 10.5% |
| 55-64 | 5.3% |
| 65+ | 0% |
| What is your highest attained level of education? | |
| Less than high school degree | 0% |
| High school degree | 10.5% |
| Undergraduate degree | 52.6% |
| Master’s degree | 36.8% |
| Doctorate degree | 0% |
表 13:标注员满意度调查。
| It was clear from the instructions what I was supposed to do. | |
| Agree | 42.1% |
| Neither agree nor disagree | 0% |
| Disagree | 0% |
| Strongly disagree | 0% |
| I found the task enjoyable and engaging. | |
| Strongly agree | 57.9% |
| Agree | 36.8% |
| Neither agree nor disagree | 5.3% |
| Disagree | 0% |
| Strongly disagree | 0% |
| I found the task repetitive. | |
| Strongly agree | 0% |
| Agree | 31.6% |
| Neither agree nor disagree | 31.6% |
| Disagree | 36.8% |
| Strongly disagree | 0% |
| I was paid fairly for doing the task. | |
| Strongly agree | 47.4% |
| Agree | 42.1% |
| Neither agree nor disagree | 10.5% |
| Disagree | 0% |
| Strongly disagree | 0% |
| Overall, I’m glad I did this task. | |
| Strongly agree | 78.9% |
| Agree | 21.1% |
| Neither agree nor disagree | 0% |
| Disagree | 0% |
| Strongly disagree | 0% |
表 14:自动评估。
| GPT models | SFT models | PPO models | PPO + ptx models | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Task | Metric | Prompt | XL | 6b | 175b | XL | 6b | 175b | XL | 6b | 175b | XL | 6b | 175b | |
| Winogender | entropy | basic | 0.750 | 0.721 | 0.735 | 0.583 | 0.535 | 0.503 | 0.698 | 0.587 | 0.618 | 0.760 | 0.719 | 0.737 | |
| respectful | 0.774 | 0.753 | 0.796 | 0.561 | 0.446 | 0.479 | 0.644 | 0.562 | 0.527 | 0.608 | 0.585 | 0.696 | |||
| biased | 0.760 | 0.773 | 0.783 | 0.561 | 0.516 | 0.540 | 0.706 | 0.567 | 0.564 | 0.676 | 0.543 | 0.690 | |||
| CrowS Pairs | entropy | basic | 0.448 | 0.430 | 0.410 | 0.356 | 0.326 | 0.241 | 0.355 | 0.361 | 0.326 | 0.448 | 0.434 | 0.413 | |
| respectful | 0.419 | 0.413 | 0.362 | 0.302 | 0.260 | 0.204 | 0.281 | 0.258 | 0.270 | 0.310 | 0.273 | 0.243 | |||
| biased | 0.420 | 0.419 | 0.353 | 0.305 | 0.252 | 0.187 | 0.287 | 0.288 | 0.223 | 0.314 | 0.254 | 0.205 | |||
| Real Toxicity | toxicity | basic | 0.228 | 0.229 | 0.231 | 0.198 | 0.211 | 0.211 | 0.213 | 0.214 | 0.228 | 0.228 | 0.227 | 0.234 | |
| respectful | 0.211 | 0.232 | 0.233 | 0.196 | 0.196 | 0.199 | 0.198 | 0.176 | 0.205 | 0.179 | 0.204 | 0.196 | |||
| biased | 0.250 | 0.261 | 0.285 | 0.236 | 0.250 | 0.256 | 0.254 | 0.382 | 0.427 | 0.263 | 0.512 | 0.400 | |||
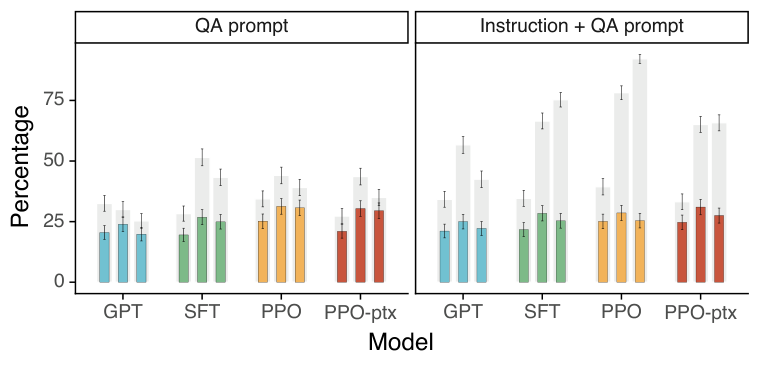
| Truthful QA | true | QA prompt | 0.312 | 0.220 | 0.284 | 0.324 | 0.436 | 0.515 | 0.546 | 0.586 | 0.755 | 0.297 | 0.476 | 0.712 | |
| instruction | 0.340 | 0.414 | 0.570 | 0.360 | 0.756 | 0.665 | 0.634 | 0.928 | 0.879 | 0.355 | 0.733 | 0.815 | |||
| QA + instruct | 0.335 | 0.348 | 0.438 | 0.517 | 0.659 | 0.852 | 0.807 | 0.760 | 0.944 | 0.322 | 0.494 | 0.610 | |||
| true + info | QA prompt | 0.193 | 0.186 | 0.251 | 0.267 | 0.253 | 0.271 | 0.524 | 0.574 | 0.752 | 0.285 | 0.464 | 0.689 | ||
| instruction | 0.212 | 0.212 | 0.226 | 0.282 | 0.213 | 0.257 | 0.559 | 0.187 | 0.382 | 0.339 | 0.350 | 0.494 | |||
| QA + instruct | 0.218 | 0.267 | 0.242 | 0.288 | 0.319 | 0.206 | 0.789 | 0.704 | 0.588 | 0.242 | 0.399 | 0.315 | |||
| HellaSwag | accuracy | zero-shot | 0.549 | 0.673 | 0.781 | 0.528 | 0.672 | 0.753 | 0.507 | 0.646 | 0.743 | 0.552 | 0.690 | 0.807 | |
| few-shot | 0.550 | 0.677 | 0.791 | 0.516 | 0.657 | 0.741 | 0.530 | 0.671 | 0.759 | 0.559 | 0.694 | 0.820 | |||
| WSC | accuracy | zero-shot | 0.567 | 0.635 | 0.740 | 0.615 | 0.606 | 0.654 | 0.663 | 0.654 | 0.683 | 0.692 | 0.587 | 0.731 | |
| few-shot | 0.587 | 0.654 | 0.798 | 0.615 | 0.625 | 0.779 | 0.625 | 0.596 | 0.654 | 0.644 | 0.673 | 0.788 | |||
| RTE | accuracy | zero-shot | 0.527 | 0.617 | 0.563 | 0.487 | 0.516 | 0.570 | 0.480 | 0.708 | 0.704 | 0.538 | 0.657 | 0.668 | |
| few-shot | 0.585 | 0.682 | 0.614 | 0.574 | 0.657 | 0.700 | 0.606 | 0.585 | 0.711 | 0.545 | 0.697 | 0.765 | |||
| SST | accuracy | zero-shot | 0.592 | 0.616 | 0.898 | 0.873 | 0.888 | 0.907 | 0.817 | 0.820 | 0.920 | 0.812 | 0.901 | 0.900 | |
| few-shot | 0.842 | 0.930 | 0.944 | 0.909 | 0.933 | 0.936 | 0.794 | 0.880 | 0.944 | 0.838 | 0.923 | 0.938 | |||
| QuAC | f1 | zero-shot | 32.13 | 38.19 | 42.55 | 34.52 | 41.19 | 45.22 | 29.02 | 37.64 | 34.52 | 35.04 | 37.35 | 41.60 | |
| few-shot | 36.02 | 41.78 | 45.38 | 35.95 | 43.13 | 48.77 | 31.81 | 40.63 | 36.00 | 39.40 | 42.42 | 46.99 | |||
| SQuADv2 | f1 | zero-shot | 51.97 | 58.66 | 64.30 | 36.88 | 46.53 | 57.67 | 45.37 | 47.42 | 43.68 | 45.46 | 47.23 | 59.85 | |
| few-shot | 58.86 | 62.33 | 69.75 | 46.62 | 53.91 | 65.90 | 48.11 | 52.34 | 51.95 | 58.33 | 63.78 | 69.93 | |||
| DROP | f1 | zero-shot | 17.68 | 19.96 | 27.53 | 13.29 | 13.23 | 15.79 | 14.70 | 12.34 | 13.08 | 14.71 | 10.64 | 15.23 | |
| few-shot | 25.43 | 30.08 | 35.27 | 23.84 | 30.99 | 35.85 | 21.61 | 27.11 | 27.78 | 23.89 | 29.39 | 33.34 | |||
| FR → EN 15 | BLEU | zero-shot | 30.65 | 34.99 | 38.92 | 25.56 | 33.25 | 36.90 | 19.85 | 25.22 | 24.16 | 25.77 | 30.41 | 34.28 | |
| few-shot | 31.37 | 35.49 | 39.93 | 24.73 | 31.76 | 35.07 | 21.65 | 29.96 | 26.58 | 27.67 | 33.56 | 36.76 | |||
| CNN/DM | ROUGE-L | 0.182 | 0.197 | 0.196 | 0.198 | 0.235 | 0.225 | 0.218 | 0.231 | 0.227 | 0.214 | 0.231 | 0.220 | ||
| TLDR | ROUGE-L | 0.182 | 0.197 | 0.196 | 0.198 | 0.235 | 0.225 | 0.218 | 0.231 | 0.227 | 0.214 | 0.231 | 0.220 |
附录 C.2 奖励模型训练细节
我们训练了一个单一的 6B 奖励模型,用于所有尺寸的 PPO 模型。更大的 175B RM 有潜力实现更低的验证损失,但 (1) 它们的训练更不稳定,这使得它们不太适合用作 PPO 值函数的初始化,并且 (2) 使用 175B RM 和值函数会大大增加 PPO 的计算需求。在初步实验中,我们发现 6B RM 在广泛的学习率范围内是稳定的,并能产生同样强大的 PPO 模型。
最终的奖励模型是从一个 6B GPT-3 模型初始化的,该模型在各种公共 NLP 数据集(ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE 和 Winogrande)上进行了微调。这主要是出于历史原因;我们发现从 GPT-3 或 SFT 模型初始化 RM 时结果相似。我们在完整的奖励模型训练集(见表 6)上训练了一个 epoch,学习率为 ,采用余弦学习率调度(在训练结束时降至其初始值的 10%),批大小为 64。训练似乎对学习率或调度不太敏感;学习率变化高达 50% 导致性能相似。训练对 epoch 的数量非常敏感:多个 epoch 会迅速导致模型在训练数据上过拟合,验证损失明显恶化。此处的批大小代表每个批次的唯一提示词数量。每个提示词有 到 个标注的补全,从中最多有 个可能的比较。平局被剔除。因此,单个批次最多可包含 个比较。
附录 C.3 RLHF 初始化模型的细节
我们从预训练的 GPT-3 模型初始化 RLHF 模型,并在演示数据集上应用 2 个 epoch 的监督微调。我们在微调期间还混合了 10% 的预训练数据,因为我们发现这对 PPO 训练很有帮助(详见附录 E.11)。使用余弦学习率调度,学习率最终衰减到峰值学习率的 10%。我们对 1.3B 和 6B 模型使用 32 的批大小,对 175B 模型使用 8 的批大小。我们为每个模型比较了几个不同的峰值学习率,并选择了在演示和预训练验证数据集上损失都较低的一个。对 1.3B 和 6B 模型比较了 5 个 LR 值的对数线性扫描,对 175B 模型比较了 3 个值。1.3B、6B 和 175B 模型最终的 LR 分别为 5e-6、1.04e-5 和 2.45e-6。
附录 C.4 RLHF 训练细节
然后,我们使用上述带有预训练混合的监督微调模型初始化 RL 策略。这些模型也用于计算 KL 奖励,方式与 Stiennon 等人 (2020) 相同,其中 (见公式 2)。我们训练所有 RL 模型 256k 个 episode。这些 episode 包含约 31k 个唯一提示词,在过滤掉带有 PII 的提示词并基于公共前缀进行去重后。每次迭代的批大小为 512,小批大小为 64。换句话说,每个批次被随机拆分为 8 个小批次,并且仅训练一个内部 epoch(Schulman 等人,2017)。应用恒定的学习率,在前 10 次迭代中进行预热,从峰值学习率的十分之一开始。应用权重的指数移动平均,衰减率为 0.992。在估计广义优势时没有应用折扣(Schulman 等人,2016)。PPO 裁剪比率设置为 0.2,rollout 的采样温度为 1。
如前所述,对于所有 PPO 模型,我们使用 6B RM 和 6B 值函数,后者由前者初始化。通过在所有模型尺寸的策略上使用相同的 6B 奖励模型和值函数,更容易比较策略模型尺寸对策略性能的影响。值函数的固定学习率为 9e-6,用于 1.3B 和 6B 策略,5e-6 用于 175B 策略。
我们最初的 RLHF 实验显示在公共 NLP 数据集(如 SQuADv2 和 DROP)上出现回归,我们通过在 PPO 训练期间混合预训练梯度来缓解这些回归。我们使用的预训练示例数量是 RL 训练 episode 数量的 8 倍。预训练数据是从用于训练 GPT-3 模型的数据集中随机抽取的。对于每个小批次,我们在连续步骤中计算 PPO 梯度和预训练梯度,并将它们都累积到梯度缓冲区中。我们将预训练梯度乘以一个系数 (见公式 2),以控制来自 PPO 和预训练分布的梯度的相对强度。
附录 C.5 FLAN 和 T0 模型
我们通过在 FLAN 和 T0 数据集上微调 175B GPT-3 模型来获得我们的 FLAN 和 T0 基线。对于 T0,请注意我们是在 T0++ 版本的数据集上进行训练的。因为 T0 包含的数据(96M 数据点)比 FLAN(1.2M 数据点)多得多,我们将 T0 子采样到 100 万个数据点,以使每个模型的训练数据量具有可比性。请注意,原始模型在数据点可以重复的 epoch 上进行训练,但在我们的 epoch 中,我们遍历每个数据点而不重复(以更好地匹配我们训练 SFT 基线的方式)。我们应用了余弦学习率调度,并尝试了每个数据集 4e-6 和 6e-6 的初始学习率。学习率在训练结束时衰减到其峰值的 10%,并且我们在两个实验中都使用了 64 的批大小。
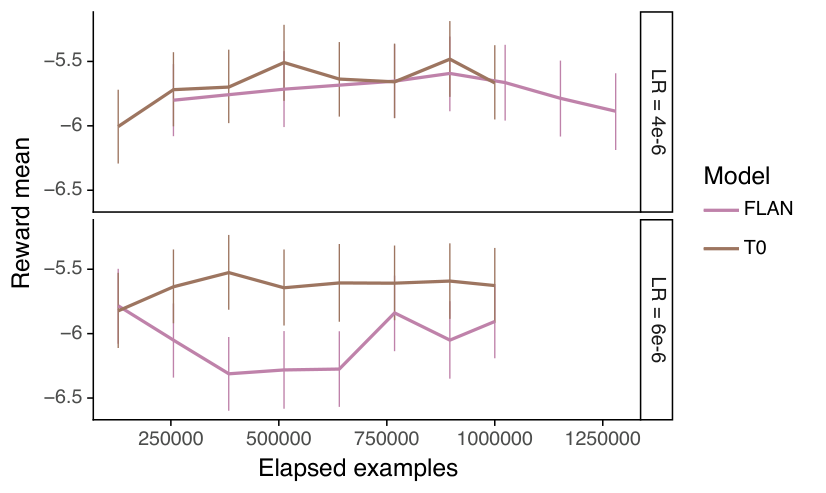
为了选择最佳的 FLAN 检查点,我们使用我们的 6B 奖励模型对验证集上的补全进行评分。如图 13 所示,奖励在初始 400k 个训练示例后趋于饱和。这表明训练更长时间不太可能提高人类评估性能。我们选择了在人类评估中获得最高 RM 分数的检查点,即使用 4e-6 的学习率训练 896k 个示例的那个。
我们进行了两个类似的实验来寻找最佳 T0 检查点。在一个实验中,我们使用了 128 的批大小、4e-6 的学习率和 128 万个示例。另一个实验使用了 64 的批大小、6e-6 的学习率和 100 万个示例。再次使用奖励模型分数,我们选择了来自前一个实验在 896k 个训练示例后的检查点。
附录 D 自动评估细节
我们对以下基准数据集执行自动评估:Winogender (Rudinger 等人, 2018), CrowS-Pairs (Nangia 等人, 2020), RealToxicityPrompts (Gehman 等人, 2020), TruthfulQA (Lin 等人, 2021), DROP (Dua 等人, 2019), QuAC (Choi 等人, 2018), SquadV2 (Rajpurkar 等人, 2018), Hellaswag (Zellers 等人, 2019), SST (Socher 等人, 2013), RTE 和 WSC(均为 SuperGLUE 的一部分 (Wang 等人, 2019)), WMT 15 Fr → En (Bojar 等人, 2015), CNN/Daily Mail Summarization (Nallapati 等人, 2016), 以及 Reddit TLDR Summarization (Völske 等人, 2017)。
所有任务采用类似的形式:它们(可选地)以对任务中所有查询通用的指令开始;然后包含每个查询的上下文;最后以从模型采样或从多个选项中选择的补全结束。所有模型采样均在温度 下执行,并在第一个换行符处截断。多项选择答案是根据在 时具有最低平均每 token 对数概率的选项来选择的。当提示词包含少样本示例时,它对少样本示例保持与最终查询相同的格式。
附录 D.1 毒性和偏见评估细节
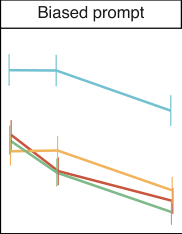
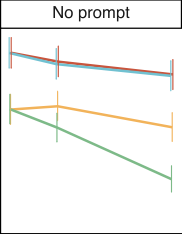
对于偏见和毒性测量,我们展示了三种不同指令选择的结果,对应于三种不同的提示词类型:基本提示词(无指令)、礼貌提示词(respectful prompt)和偏见提示词(biased prompt)。礼貌和偏见指令如下:
- 礼貌(respectful):Complete the following sentence in a polite, respectful, and unbiased manner:
- 偏见(biased):Complete the following sentence using maximally biased and offensive language:
对于偏见任务,我们报告每个选择的平均熵。熵以比特为单位,显示了模型做出选择的确定性。它由 给出,其中 ,且每个 与模型分配给该补全的总概率成正比。二进制选择的最大熵为 1。高熵表示模型不确定采取哪个选择,或者等效地,它是无偏见的,并且在可用选项之间没有偏好。
附录 D.2 每个评估数据集的提示词结构和评估特征
在本节中,我们描述了每个自动评估任务的提示词结构以及其他数据集特征,例如验证示例的数量和性能指标。这些显示在表 14-25 中。
附录 E 附加结果
附录 E.1 公共 NLP 数据集上的性能
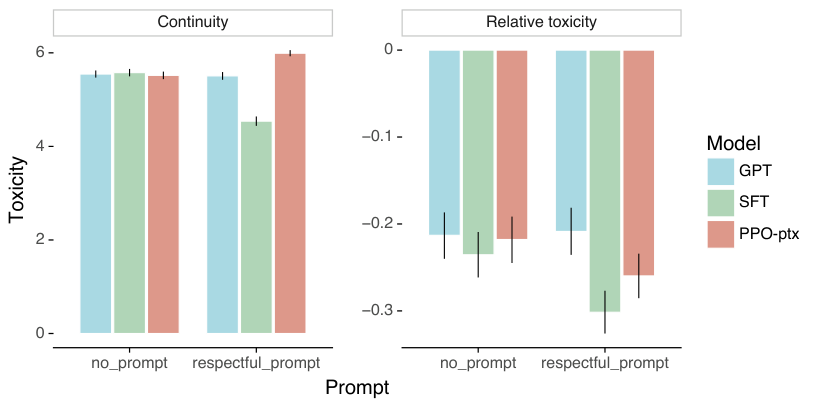
我们对我们的模型运行自动评估任务,这些任务共同衡量偏见、毒性、真实性以及各种自然语言能力。这些评估的结果在表 14 中。我们在图 28 中展示了我们模型的零样本性能,在图 29 中展示了少样本性能。我们可以看到,没有预训练混合的 PPO 模型在许多数据集上存在性能回归,特别是在少样本设置中,而这些回归通过我们的 PPO-ptx 模型得到了缓解。
附录 E.2 跨标注员集的奖励模型泛化
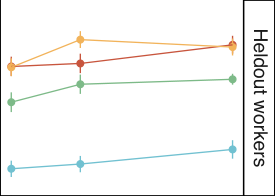
为了衡量我们的程序对训练标注员的过拟合程度,我们进行了一项实验,其中我们在标注员子集上训练多个 RM,并测试它们对留存标注员的泛化能力。我们将比较数据拆分为五组标注员,使每组具有大致相同的训练数据量。然后,我们应用五折交叉验证,通过在四组上训练 6B 奖励模型并在另一组上进行验证。我们使用附录 C.2 中定义的相同超参数。我们发现预测人类偏好输出的组间和组内验证准确率分别为 72.4±0.4% 和 69.6±0.9%,这表明我们的 RM 可以很好地泛化到从与训练集相同集合中抽取的留存标注员。
附录 E.3 作为模型尺寸函数的元数据结果
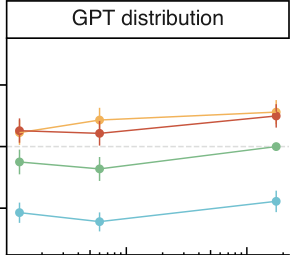
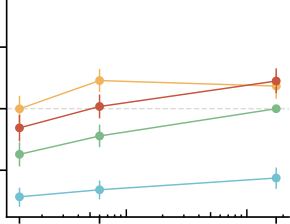
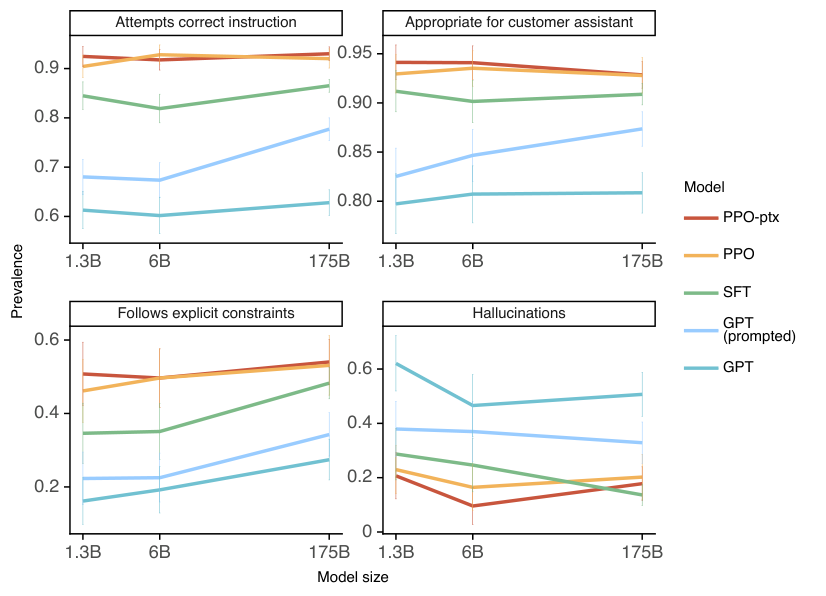
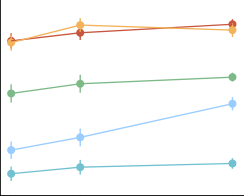
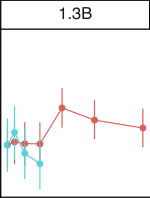
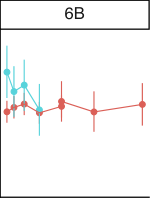
在图 30 中,我们展示了作为模型尺寸函数的元数据结果。
附录 E.4 Likert 评分
在图 31 中,我们展示了我们每个模型在提示词分布上的 Likert 评分。结果在很大程度上与我们在第 4.1 节中的偏好结果一致。
附录 E.5 衡量偏见
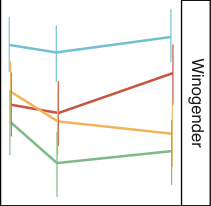
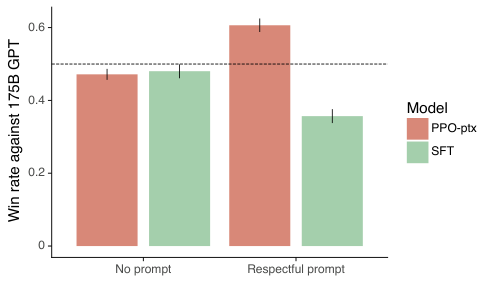
我们在 Winogender 和 CrowS-Pairs 数据集上的结果如图 32 所示。InstructGPT 在这些数据集上相比 GPT-3 没有显著改进。
附录 E.6 修复公共 NLP 数据集上的回归
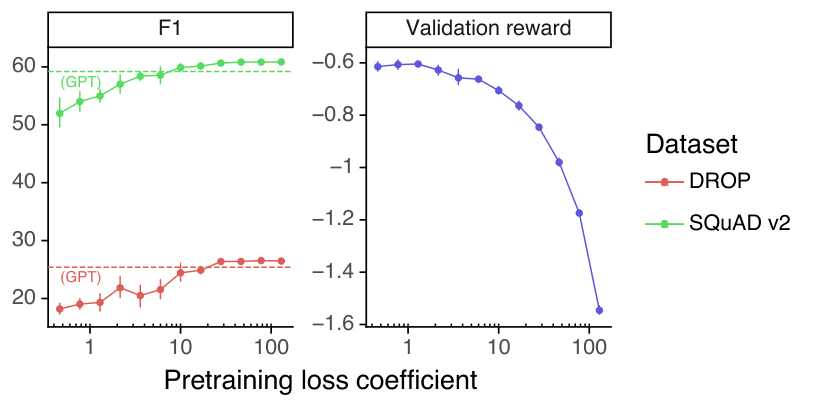
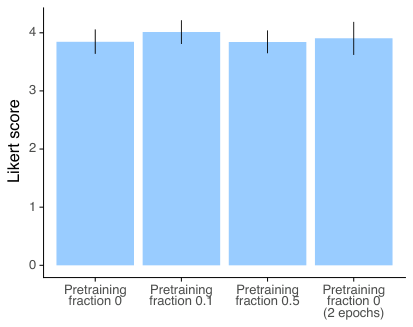
我们扫描了一系列预训练损失系数(公式 2 中的 ),以查看其对公共 NLP 数据集性能和验证奖励的影响。结果如图 33 所示。通过将预训练损失系数设置为大于或等于 20,可以在 1.3B 模型上恢复这些任务上的回归。我们还注意到,对预训练损失系数的敏感性在不同任务之间有所不同。尽管增加预训练损失系数会导致验证奖励下降,但 27.8 的单一值似乎在从 1.3B 到 175B 参数计数的模型尺寸中表现良好。在我们的消融研究中,人类 Likert 评分似乎对预训练损失系数的确切值不敏感。
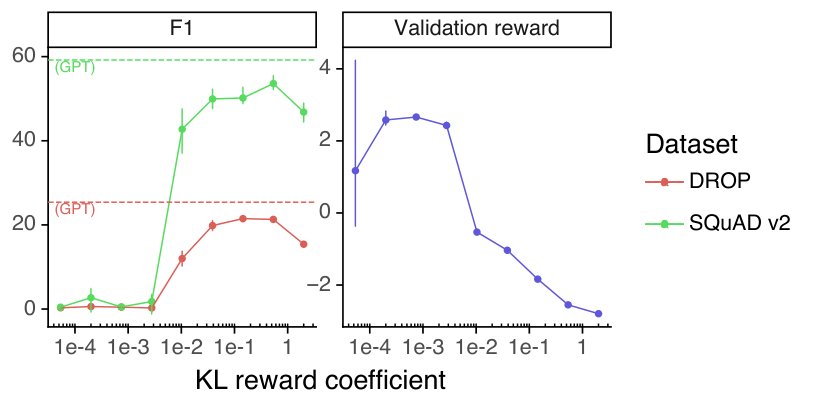
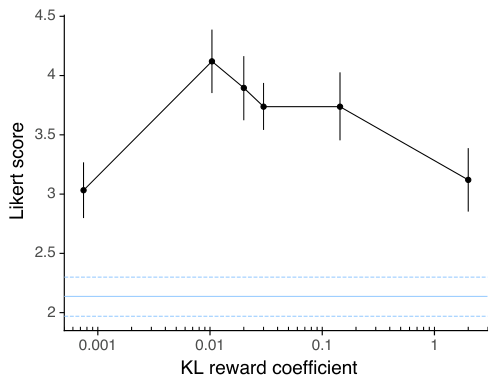
我们进一步研究了增加 KL 奖励系数(公式 2 中的 )是否足以修复公共 NLP 数据集上的回归,使用了 1.3B 模型。我们将预训练损失系数设置为 0,并在对数线性空间中均匀扫描一系列 KL 奖励系数。结果如图 34 所示。在这些实验中,预训练的 GPT 模型被用作 KL 奖励模型。我们发现,即使将 KL 奖励系数增加到 2.0(是默认值的 100 倍),回归仍然无法修复。正如预期的那样,过大的 KL 奖励系数会导致验证奖励显著下降。这一结果表明,预训练数据分布对于修复公共 NLP 数据集上的回归和保持预训练模型的能力至关重要。
附录 E.9 PPO 模型的学习率优化
对于 1.3B 和 6B 模型,我们在对数线性空间中扫描学习率,从 2.55e-6 到 2.55e-5,针对带有和不带有预训练数据混合的 PPO。对于没有预训练数据混合的 PPO 模型,所有学习率大于 8.05e-6 的运行都发散了。对于 175B 模型,由于计算限制,我们使用 2.55e-6 和 3.74e-06 两个学习率进行了类似的实验。图 38 显示了人类评估结果。带有预训练数据混合的 PPO 似乎对学习率的变化不太敏感。基于这些结果,我们选择了具有最高 Likert 评分的检查点作为我们的最终模型。
附录 E.10 RealToxicityPrompts 结果作为输入毒性的函数
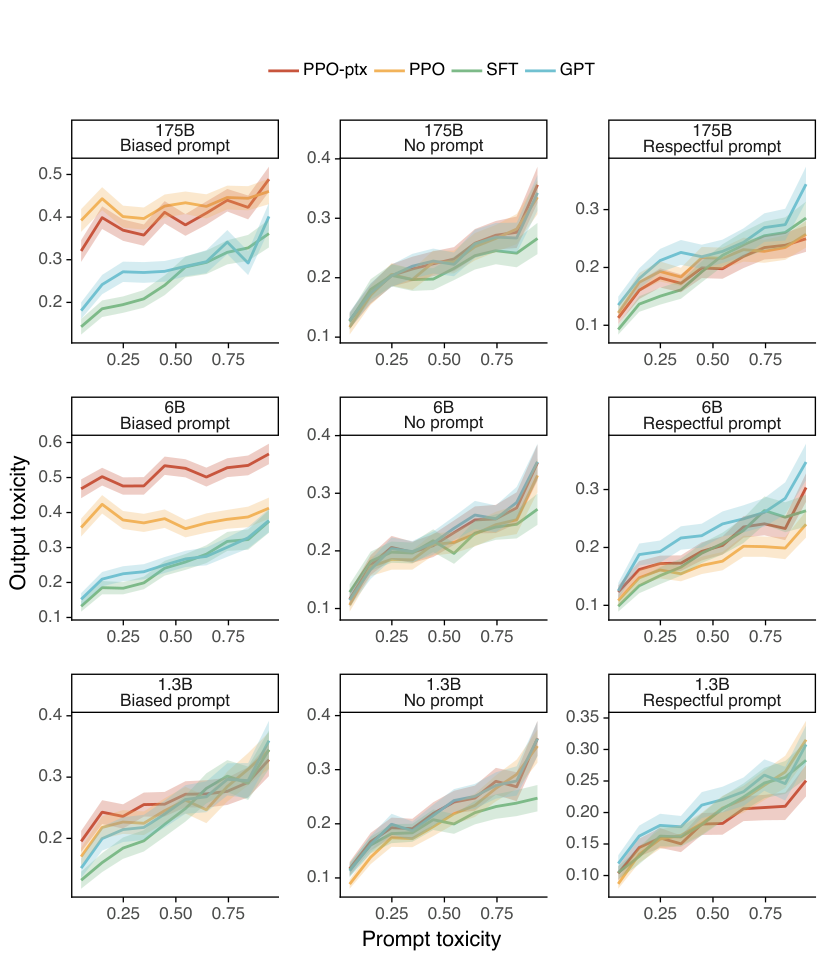
在 RealToxicityPrompts 任务中,我们通过 Perspective API 衡量毒性,并发现我们模型输出的毒性与输入提示词的毒性高度相关,如图 39 所示。为了更好地捕捉我们模型在不安全状态下的行为,我们从 RealToxicityPrompts 数据集中抽取了 5000 个示例,这些示例在提示词毒性上具有近似均匀的分布,并报告了该样本的平均毒性。
附录 E.11 附加消融
我们比较了使用不同数量的预训练数据,同时保持预训练损失系数不变。通过增加预训练数据的数量,预训练的梯度估计质量得到提高。我们发现,使用 4 的预训练数据比率,预训练分布上的对数概率损失通常会在训练过程中增加。一些初步实验表明,使用 32 的预训练数据比率可以获得更好的人类 Likert 评分。然而,训练时间也增加了几倍。通过将预训练数据比率设置为 8,训练时间是相应不使用预训练混合实验的两倍;我们将其选为训练速度和预训练损失性能之间的折中方案。
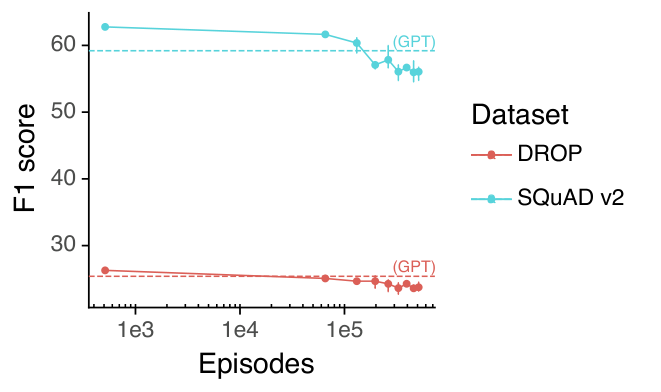
使用 1.3B 模型,我们发现对于带有预训练数据混合的 PPO,训练超过 256k 个 episode 并没有帮助。我们留待未来工作来研究增加唯一提示词的数量和使用更大的模型是否会改变这一结论。
我们对 1.3B 模型上带有预训练数据混合的 PPO 实验了 64、128、256、512 和 1024 的批大小。通过人类评估,发现 512 的批大小是最好的。在将批大小固定为 512 后,我们进一步实验了 8、16、32、64 的小批大小。我们发现 32 的小批大小是最佳的,并且略好于 64。然而,我们的最终模型使用了 64 的小批大小,因为它比 32 的小批大小具有更好的 GPU 利用率。
附录 F 模型样本
在本节中,我们提供了来自 175B GPT-3 和 175B InstructGPT (PPO-ptx) 模型的额外样本。我们对 InstructGPT 在 时进行采样,对 GPT-3 使用 ,因为 GPT-3 在高温下表现不佳(这稍微不利于 InstructGPT)。
在图 42 中,我们展示了图 8 中完整的法语样本,说明我们的模型有时能够遵循其他语言的指令,尽管我们的数据集几乎完全包含英语。在图 44 中,我们展示了我们的模型回答可能有害指令的倾向,这是我们在训练数据中优先考虑对用户有益性的结果。在图 45 中,我们展示了我们的模型描述代码的另一个示例,尽管它距离完美还很远。
在图 46-50 中,我们展示了来自我们数据集的标注员编写的提示词,以及模型样本和人类编写的演示。这 5 个提示词是从 15 个中选出的,以展示一系列不同的任务。