基于专家混合模型(MoE)的高效大规模语言建模
Mikel Artetxe*, Shruti Bhosale*, Naman Goyal*, Todor Mihaylov*, Myle Ott*, Sam Shleifer*, Xi Victoria Lin, Jingfei Du, Srinivasan Iyer, Ramakanth Pasunuru, Giri Anantharaman, Xian Li, Shuohui Chen, Halil Akin, Mandeep Baines, Louis Martin, Xing Zhou, Punit Singh Koura, Brian O’Horo, Jeff Wang, Luke Zettlemoyer, Mona Diab, Zornitsa Kozareva, Ves Stoyanov Meta AI
摘要
专家混合(Mixture of Experts, MoE)层通过条件计算实现了语言模型的高效扩展。本文对自回归 MoE 语言模型在多种设置下的扩展方式进行了详细的实证研究,包括:域内和域外语言建模、零样本(zero-shot)和少样本(few-shot)启动(priming),以及全样本微调(full-shot fine-tuning)。除了微调之外,我们发现 MoE 在计算效率上显著更高。在较为适中的训练预算下,MoE 模型可以使用少约 4 倍的计算量达到与稠密(dense)模型相当的性能。这种差距随规模扩大而缩小,但我们最大的 MoE 模型(1.1T 参数)在计算量相当的情况下,始终优于稠密模型(6.7B 参数)。总体而言,这种性能差距在不同任务和领域间差异巨大,这表明 MoE 和稠密模型在泛化方式上存在差异,值得未来进一步研究。我们将代码和模型公开以供研究使用。
1 引言
大型语言模型(LMs)在针对 NLP 任务进行微调后,展现出了卓越的准确性和泛化能力(Peters 等人,2018;Devlin 等人,2019;Liu 等人,2019;Lan 等人,2020;Raffel 等人,2020)。它们还具备零样本和少样本学习能力(Brown 等人,2020),能够泛化到训练期间未见过的任务。在所有这些设置中,提高 LM 准确率的一种可靠方法是扩展规模:增加参数数量和训练及推理过程中使用的计算量(Raffel 等人,2020;Brown 等人,2020;Fedus 等人,2021)。事实上,一些泛化特性仅在超大规模模型中才会涌现,包括显著改进的零样本和少样本学习(Brown 等人,2020)。
不幸的是,训练最先进语言模型所需的计算资源相应增长,这对许多研究界成员来说是一个障碍(Schwartz 等人,2019)。人们还担心训练和部署此类模型相关的环境成本(Strubell 等人,2019;Gupta 等人,2021;Bender 等人,2021;Patterson 等人,2021),这促使人们研究更高效的模型设计(Lepikhin 等人,2021;Fedus 等人,2021;Lewis 等人,2021)。
稀疏模型允许在不增加相关计算成本的情况下增加可学习参数的数量。例如,稀疏门控专家混合(MoE)(Lepikhin 等人,2021)已成功用于语言建模和机器翻译(Lepikhin 等人,2021;Lewis 等人,2021;Roller 等人,2021),但尚未证明其在微调(Fedus 等人,2021)以及零样本和少样本学习方面的有效性。
2 背景与相关工作
2.1 大型语言模型 / GPT-3
NLP 领域的进步主要由在大型文本数据集上预训练的日益庞大的语言模型(LMs)推动。虽然已经提出了许多变体,但此类 LM 主要基于 Transformer 架构(Vaswani 等人,2017)。模型通过隐藏部分输入进行预训练:按顺序从左到右预测下一个单词,掩盖文本中的单词(Devlin 等人,2019;Liu 等人,2019),或扰动和/或掩盖跨度(Lewis 等人,2020;Raffel 等人,2020)。由此产生的模型可以通过在监督数据上进行微调,快速适应以高准确度执行新任务(Devlin 等人,2019;Liu 等人,2019)。
最近,GPT-3(Brown 等人,2020)证明了大型 LM 可以通过上下文学习在不进行微调的情况下执行零样本和少样本学习。值得注意的是,许多此类上下文零样本和少样本学习行为在规模扩大时会涌现或增强。与我们的工作同时,Rae 等人(2022)和 Smith 等人(2022)进一步探索了稠密语言模型的扩展。
2.2 稀疏模型
稠密模型扩展的一个缺点是计算成本越来越高。为了更有效地增加模型容量,人们开发了条件计算策略(Bengio 等人,2013;Davis 和 Arel,2013;Cho 和 Bengio,2014;Bengio 等人,2015),其中每个输入仅激活模型的一个子集。最近的工作(Lewis 等人,2021;Lepikhin 等人,2021;Fedus 等人,2021;Fan 等人,2021)研究了适用于 Transformer 模型的不同条件计算策略。在这项工作中,我们专注于稀疏门控专家混合(MoE)模型(Shazeer 等人,2017;Lepikhin 等人,2021)。稀疏 MoE 模型将每个交替 Transformer 层中的稠密前馈网络块替换为 MoE 层。MoE 层有一个路由门,用于学习将哪些 token 映射到哪一组专家(我们使用 top-2 专家)。为了确保可扩展性和训练效率,通常还会像 Lepikhin 等人(2021)那样在交叉熵损失中加入加权门控损失项,以鼓励 token 在专家之间均匀分布。与我们的工作同时,Du 等人(2021)、Rajbhandari 等人(2022)和 Clark 等人(2022)也研究了 MoE 扩展。
2.3 零样本和少样本学习
最近的工作(Schick 和 Schütze,2021a;Radford 等人,2019)通过将任务输入重构为完形填空式的提示补全任务,成功地直接评估了 LM 在未见任务上的表现(零样本学习)。这与传统的通过添加任务特定头并进行监督微调来增强 LM 的方法形成对比(Devlin 等人,2019;Raffel 等人,2020)。
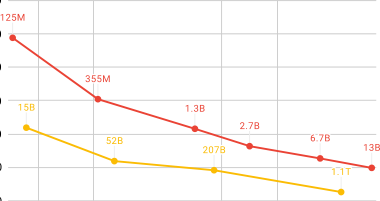
表 1:稠密模型和专家混合(MoE)模型详情。
size:参数数量,cost:训练 ZFLOPs,l:层数,h:隐藏维度,e:专家数量。所有模型均使用 2048 个 token 的序列长度训练 300B 个 token。同一行内的模型大致相当。我们通过分析估算训练成本(见附录 G)。
| 模型类型 | size | cost | l | h | e |
|---|---|---|---|---|---|
| GPT-3 (dense) | 125M | 0.36 | 12 | 768 | – |
| 355M | 1.06 | 24 | 1024 | – | |
| 760M | 2.13 | 24 | 1536 | – | |
| 1.3B | 3.57 | 24 | 2048 | – | |
| 2.7B | 7.08 | 32 | 2560 | – | |
| 6.7B | 17.12 | 32 | 4096 | – | |
| 13B | 32.67 | 40 | 5120 | – | |
| 175B | 430.17 | 96 | 12288 | – | |
| Ours (dense) | 125M | 0.36 | 12 | 768 | – |
| 355M | 1.06 | 24 | 1024 | – | |
| 1.3B | 3.57 | 24 | 2048 | – | |
| 2.7B | 7.08 | 32 | 2560 | – | |
| 6.7B | 17.12 | 32 | 4096 | – | |
| 13B | 32.67 | 40 | 5120 | – | |
| Ours (MoE) | 15B | 0.43 | 12 | 768 | 512 |
| 52B | 1.30 | 24 | 1024 | 512 | |
| 207B | 4.53 | 24 | 2048 | 512 | |
| 1.1T | 22.27 | 32 | 4096 | 512 |
3 实验设置
3.1 模型
我们训练了自回归(仅解码器)Transformer 模型,其大小和架构大致与 Brown 等人(2020)探索的模型相匹配。模型大小总结在表 1 中。我们使用预归一化 Transformer 块(Baevski 和 Auli,2019;Child 等人,2019)和 GELU 激活函数(Hendrycks 和 Gimpel,2016)。我们与 Brown 等人(2020)的不同之处在于:(1) 我们仅使用稠密注意力,而他们交替使用稠密和局部带状稀疏注意力;(2) 我们按照 Shortformer(Press 等人,2020)的方法,使用正弦位置嵌入来训练模型。
我们还训练了与我们的稠密模型配置相对应的 MoE 模型(见表 1 中的第三组列),以便在浮点运算(FLOPs)数量方面进行大致匹配的比较。我们的 MoE 模型遵循 Lepikhin 等人(2021)提出的设计,采用交替的稠密层和专家层以及 top-2 专家选择。我们在每个专家层中使用 512 个专家()。每个专家具有 个 token 的容量,其中 是我们设置为 2 的容量因子, 是以 token 为单位的总批次大小。容量是指路由到每个专家的最大 token 数量。一旦某个专家在给定批次中达到容量,额外的 token 将被视为“溢出”,其表示通过残差连接传递。
Fedus 等人(2021)报告了训练大型 MoE 模型的不稳定性,并建议重新缩放初始模型权重,我们发现这没有必要。相反,我们观察到专家参数相对于稠密(数据并行)参数具有 倍小的批次大小,因此将专家梯度重新缩放了 倍。这种重新缩放与理论一致,即批次大小增加 倍应伴随学习率增加 倍(Krizhevsky,2014)。
3.2 预训练数据
我们在一组六个英语语言数据集的联合体上预训练我们的模型,包括用于预训练 RoBERTa(Liu 等人,2019)的五个数据集以及 CC100 的英语子集,总计 112B 个 token,对应 453GB。
3.3.3 MoE 加速因子
我们假设稀疏模型可以在较小的计算预算下实现相当的性能。因此,衡量 MoE 在达到特定性能水平时相对于稠密模型的高效程度是有意义的。我们估算模型在特定任务中达到性能 (对于语言建模以困惑度衡量,对于下游任务以准确率衡量)所需的 FLOPs ,无论是使用 MoE 还是稠密模型。鉴于我们只有离散的观测值,我们通过在对数尺度上进行插值来估算缺失的精确值,如下所示:
其中 , 和 是可用模型中分别低于和高于 的最接近 的性能值,而 和 是它们在 ZFLOPs 中的相应训练成本。
4 结果与分析
4.1 语言建模困惑度
我们报告了图 2 中的困惑度结果,并在图 3a 中可视化了 Pile(Gao 等人,2021)代表性子集中的加速曲线。
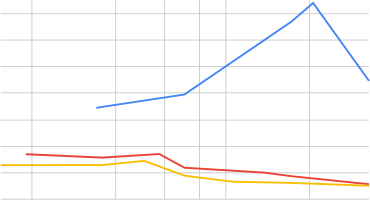
我们观察到所有 MoE 模型在所有数据集上都优于其稠密对应模型,但它们的优势在不同领域和模型之间差异巨大。MoE 在域内评估时效率最高,能够匹配使用 8-16 倍计算量训练的稠密模型的性能(见图 1)。在域外设置中,改进较为适中,在 Pile 上带来了 2-4 倍的加速。这反映在图 2 中,其中 MoE 和稠密曲线之间的差距在域外设置中要小得多。此外,MoE 相对于稠密模型的优势随规模扩大而减小:MoE 需要约 4 倍更少的计算量来匹配使用 2-6 ZFLOPs 训练的稠密模型的性能,但对于使用约 30 ZFLOPs 训练的稠密模型,加速比约为 2。
表 2:零样本启动准确率。
GPT-3 (paper) 结果取自 Brown 等人(2020),所有其他结果由我们按照 §3.3.2 所述获得。RE: ReCoRD, HS: HellaSwag, PI: PIQA, WG: WinoGrande, SC: StoryCloze, OB: OpenBookQA。由于价格高昂,我们没有在 RE 上评估最大的 GPT-3 模型 (davinci)。
| 模型 | size | RE | HS | PI | WG | SC | OB | avg |
|---|---|---|---|---|---|---|---|---|
| GPT-3 (paper) | 125M | 70.8 | 33.7 | 64.6 | 52.0 | 63.3 | 35.6 | 53.3 |
| 355M | 78.5 | 43.6 | 70.2 | 52.1 | 68.5 | 43.2 | 59.4 | |
| 760M | 82.1 | 51.0 | 72.9 | 57.4 | 72.4 | 45.2 | 63.5 | |
| 1.3B | 84.1 | 54.7 | 75.1 | 58.7 | 73.4 | 46.8 | 65.5 | |
| 2.7B | 86.2 | 62.8 | 75.6 | 62.3 | 77.2 | 53.0 | 69.5 | |
| 6.7B | 88.6 | 67.4 | 78.0 | 64.5 | 77.7 | 50.4 | 71.1 | |
| 13B | 89.0 | 70.9 | 78.5 | 67.9 | 79.5 | 55.6 | 73.6 | |
| 175B | 90.2 | 78.9 | 81.0 | 70.2 | 83.2 | 57.6 | 76.9 | |
| Ours (MoE) | 15B | 77.8 | 53.2 | 74.3 | 53.4 | 73.6 | 42.0 | 62.4 |
| 52B | 83.4 | 64.9 | 76.8 | 57.4 | 75.9 | 51.0 | 68.2 | |
| 207B | 86.0 | 70.5 | 78.2 | 60.9 | 78.1 | 50.8 | 70.7 | |
| 1.1T | 88.0 | 78.6 | 80.3 | 66.4 | 81.8 | 55.2 | 75.0 |
5 结论
我们展示了将稀疏语言模型扩展到 1.1T 参数的结果。我们观察到,在这一规模下,与稠密对应模型相比,稀疏模型在语言建模、零样本和少样本学习方面提供了更好的性能与计算权衡。虽然差距在规模扩大时开始缩小,但我们最大的稀疏模型在计算量仅为稠密模型一半的情况下,性能优于稠密模型。这些结果证实,稀疏 MoE 模型可以作为广泛使用的稠密架构的替代方案,从而节省计算量并降低模型能耗。