微调语言模型即零样本学习者
Jason Wei*, Maarten Bosma*, Vincent Y. Zhao*, Kelvin Guu*, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, 和 Quoc V. Le Google Research
摘要
本文探讨了一种提高语言模型零样本学习能力的简单方法。我们证明,指令微调(instruction tuning)——即在通过指令描述的数据集集合上对语言模型进行微调——能够显著提高模型在未见任务上的零样本性能。
我们采用了一个具有 137B 参数的预训练语言模型,并利用自然语言指令模板将其在超过 60 个 NLP 数据集上进行了指令微调。我们评估了这个被称为 FLAN 的指令微调模型在未见任务类型上的表现。FLAN 显著提高了其未经修改的对应模型的性能,并在我们评估的 25 个数据集中的 20 个上超越了零样本 175B GPT-3。FLAN 在 ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA 和 StoryCloze 上甚至以较大优势超越了少样本 GPT-3。消融研究表明,微调数据集的数量、模型规模以及自然语言指令是指令微调成功的关键。
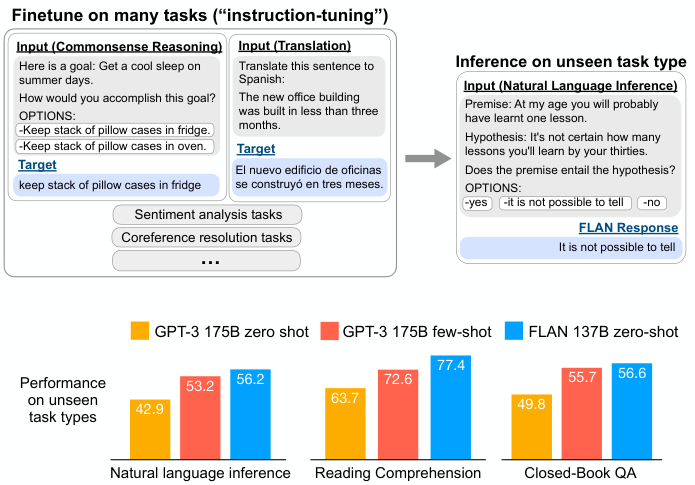
图 1: 上图:指令微调与 FLAN 的概览。指令微调在以指令形式表述的任务混合集上对预训练语言模型进行微调。在推理时,我们在未见任务类型上进行评估;例如,我们可以在指令微调期间未见过 NLI 任务的情况下,评估模型在自然语言推理(NLI)上的表现。下图:零样本 FLAN 与零样本及少样本 GPT-3 在我们评估的十种未见任务类型中的三种上的性能对比,指令微调在这三种任务上显著提高了性能。NLI 数据集:ANLI R1–R3, CB, RTE。阅读理解数据集:BoolQ, MultiRC, OBQA。闭卷问答数据集:ARC-easy, ARC-challenge, NQ, TriviaQA。
1 引言
大规模语言模型(LMs),如 GPT-3 (Brown et al., 2020),已被证明在少样本学习方面表现出色。然而,它们在零样本学习方面的表现却不尽如人意。例如,GPT-3 在阅读理解、问答和自然语言推理等任务上的零样本性能远低于其少样本性能。一个潜在的原因是,在没有少样本示例的情况下,模型更难在与预训练数据格式不相似的提示(prompts)上表现良好。
在本文中,我们探索了一种提高大型语言模型零样本性能的简单方法,这将扩大其受众范围。我们利用了一个直觉,即 NLP 任务可以通过自然语言指令来描述,例如“这段电影评论的情感是正面的还是负面的?”或“将‘how are you’翻译成中文。”我们采用了一个 137B 参数的预训练语言模型,并进行了指令微调——即在通过自然语言指令表达的 60 多个 NLP 数据集的混合集上对模型进行微调。我们将由此产生的模型称为 FLAN(Finetuned Language Net)。
为了评估 FLAN 在未见任务上的零样本性能,我们将 NLP 数据集根据任务类型进行聚类,并在指令微调 FLAN 时保留每个聚类用于评估,而在所有其他聚类上进行训练。例如,如图 1 所示,为了评估 FLAN 执行自然语言推理的能力,我们在其他一系列 NLP 任务(如常识推理、翻译和情感分析)上对模型进行指令微调。由于此设置确保了 FLAN 在指令微调期间没有见过任何自然语言推理任务,我们随后评估其执行零样本自然语言推理的能力。
我们的评估表明,FLAN 显著提高了基础 137B 参数模型的零样本性能。FLAN 的零样本性能在我们评估的 25 个数据集中的 20 个上超过了 175B 参数 GPT-3 的零样本性能,甚至在 ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA 和 StoryCloze 上以较大优势超过了 GPT-3 的少样本性能。在消融研究中,我们发现增加指令微调中的任务聚类数量可以提高在未见任务上的性能,并且指令微调的益处仅在模型规模足够大时才会显现。
指令微调是一种简单的方法,如图 2 所示,它结合了预训练-微调和提示范式的吸引人之处,通过使用微调监督来改善语言模型对推理时文本交互的响应。我们的实证结果展示了语言模型仅通过指令描述来执行任务的潜力。用于加载 FLAN 指令微调数据集的源代码已在 https://github.com/google-research/flan 公开。
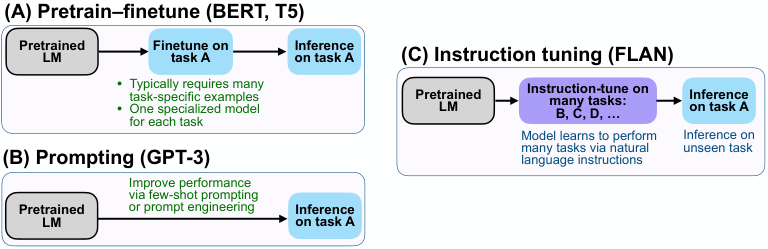
图 2: 比较指令微调与预训练-微调和提示。
2 FLAN:指令微调提高零样本学习能力
指令微调的动机是提高语言模型响应 NLP 指令的能力。其思想是,通过使用监督来教导 LM 执行通过指令描述的任务,LM 将学会遵循指令,即使对于未见任务也能做到这一点。为了评估在未见任务上的性能,我们将数据集按任务类型分组为聚类,并在指令微调所有剩余聚类的同时,保留每个任务聚类用于评估。
2.1 任务与模板
由于从头开始创建一个包含许多任务的指令微调数据集将非常耗费资源,我们将研究界现有的数据集转换为指令格式。我们将 Tensorflow Datasets 上公开的 62 个文本数据集(包括语言理解和语言生成任务)聚合成一个单一的混合集。图 3 展示了这些数据集——每个数据集被归类为十二个任务聚类之一,同一聚类中的数据集属于相同的任务类型。每个数据集的描述、大小和示例在附录 G 中展示。
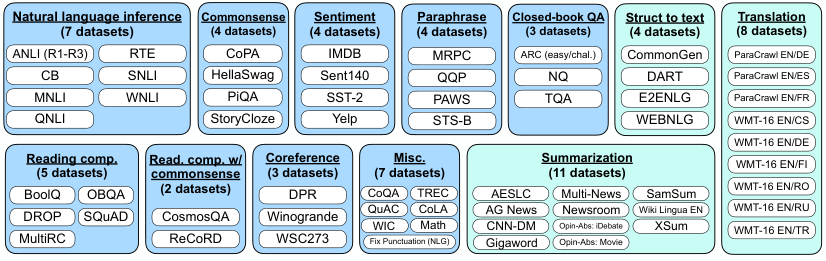
图 3: 本文使用的数据集和任务聚类(蓝色为 NLU 任务;青色为 NLG 任务)。
对于每个数据集,我们手动编写了十个独特的模板,使用自然语言指令来描述该数据集的任务。虽然这十个模板中的大多数描述了原始任务,但为了增加多样性,对于每个数据集,我们还包含了最多三个“反转任务”的模板(例如,对于情感分类,我们包含了要求生成电影评论的模板)。然后,我们在所有数据集的混合集上对预训练语言模型进行指令微调,每个数据集的示例通过随机选择的指令模板进行格式化。图 4 展示了自然语言推理数据集的多个指令模板。

图 4: 描述自然语言推理任务的多个指令模板。
2.2 评估划分
我们关注 FLAN 在指令微调中未见过的任务上的表现,因此定义什么是“未见任务”至关重要。虽然一些先前的工作通过禁止相同数据集出现在训练中来定义未见任务,但我们使用了一种更保守的定义,利用了图 3 中的任务聚类。在这项工作中,我们仅在评估时将数据集 视为未见,如果 所属的任何任务聚类中的数据集在指令微调期间均未出现。例如,如果 是一个蕴含任务,那么指令微调中就不会出现任何蕴含数据集,我们在所有其他聚类上进行了指令微调。因此,为了在 个任务聚类上评估零样本 FLAN,我们指令微调了 个模型,其中每个模型保留一个不同的任务聚类用于评估。
注:在评估阅读理解与常识聚类时,阅读理解和常识推理均从指令微调中剔除。相反,在评估阅读理解或常识推理时,阅读理解与常识聚类未用于指令微调。在评估 NLI 任务时,我们也从指令微调中剔除了释义聚类,反之亦然。
2.3 带选项的分类
给定任务的输出空间要么是几个类别之一(分类),要么是自由文本(生成)。由于 FLAN 是仅解码器语言模型的指令微调版本,它自然以自由文本形式响应,因此生成任务不需要进一步修改。
对于分类任务,先前的工作 (Brown et al., 2020) 使用了一种排名分类(rank classification)方法,其中,例如,仅考虑两个输出(“yes”和“no”),并取概率较高的一个作为模型的预测。虽然此过程在逻辑上是合理的,但它是不完美的,因为答案的概率质量在表达每个答案的方式之间可能存在不期望的分布(例如,大量表达“yes”的替代方式可能会降低分配给“yes”的概率质量)。因此,我们包含了一个选项后缀,我们在分类任务的末尾附加标记 OPTIONS,并附上该任务的输出类别列表。这使得模型在响应分类任务时知道期望哪些选择。选项的使用示例见图 1 中的 NLI 和常识示例。
2.4 训练细节
模型架构与预训练。 在我们的实验中,我们使用 LaMDA-PT,这是一个 137B 参数的密集从左到右、仅解码器的 Transformer 语言模型 (Thoppilan et al., 2022)。该模型在网页文档集合(包括计算机代码)、对话数据和维基百科上进行预训练,使用 SentencePiece 库 (Kudo & Richardson, 2018) 分词为 2.49T BPE 标记,词汇量为 32k。大约 10% 的预训练数据是非英语的。注意,LaMDA-PT 仅具有语言模型预训练(对比 LaMDA,它是针对对话进行微调的)。
指令微调过程。 FLAN 是 LaMDA-PT 的指令微调版本。我们的指令微调流水线混合了所有数据集并从每个数据集中随机采样。为了平衡不同数据集的大小,我们将每个数据集的训练示例限制为 30k,并遵循示例比例混合方案 (Raffel et al., 2020),最大混合率为 3k。我们使用 Adafactor 优化器 (Shazeer & Stern, 2018) 以 的学习率对所有模型进行 30k 梯度步数的微调,批大小为 8,192 个标记。微调中使用的输入和目标序列长度分别为 1024 和 256。我们使用打包(packing)(Raffel et al., 2020) 将多个训练示例组合成一个序列,使用特殊的 EOS 标记分隔输入和目标。此指令微调在具有 128 个核心的 TPUv3 上耗时约 60 小时。对于所有评估,我们报告在训练 30k 步后的最终检查点上的结果。
3 结果
我们评估 FLAN 在自然语言推理、阅读理解、闭卷问答、翻译、常识推理、指代消解和结构转文本任务上的表现。如 §2.2 所述,我们通过将数据集分组为任务聚类并在指令微调所有剩余聚类的同时保留每个聚类用于评估(即每个评估任务聚类使用不同的检查点)来评估未见任务。对于每个数据集,我们评估所有模板的平均性能,这代表了给定典型自然语言指令时的预期性能。由于有时可以使用开发集进行手动提示工程 (Brown et al., 2020),对于每个数据集,我们还使用具有最佳开发集性能的模板获得测试集性能。
为了比较,我们使用与 GPT-3 相同的提示报告了 LaMDA-PT 的零样本和少样本结果(因为 LaMDA-PT 在没有指令微调的情况下不适合自然指令)。该基线提供了指令微调帮助程度的最直接消融。指令微调显著改善了 LaMDA-PT 在大多数数据集上的表现。
我们还展示了 GPT-3 175B (Brown et al., 2020) 和 GLaM 64B/64E (Du et al., 2021) 的零样本性能,如其各自论文中所报告的那样。使用最佳开发模板,零样本 FLAN 在 25 个数据集中的 20 个上优于零样本 GPT-3,甚至在 10 个数据集上超过了 GPT-3 的少样本性能。使用最佳开发模板,零样本 FLAN 在 19 个可用数据集中的 13 个上优于零样本 GLaM,在 11 个数据集上优于单样本 GLaM。
注:在此混合方案中,最大混合率为 3,000 意味着数据集不会因超过 3,000 个示例而获得额外的采样权重。
总体而言,我们观察到指令微调在自然地表述为指令的任务(例如 NLI、QA、翻译、结构转文本)上非常有效,而在直接表述为语言建模的任务(其中指令在很大程度上是多余的,例如格式化为完成不完整句子或段落的常识推理和指代消解任务)上效果较差。自然语言推理、阅读理解、闭卷问答和翻译的结果总结在图 5 中,并在下面描述。

图 5: FLAN 与 LaMDA-PT 137B、GPT-3 175B 和 GLaM 64B/64E 在自然语言推理、阅读理解、闭卷问答和翻译上的零样本性能对比。FLAN 的性能是每个任务最多 10 个指令模板的平均值。监督模型要么是 T5、BERT,要么是翻译模型(在附录的表 2 和表 1 中指定)。
自然语言推理 (NLI)。 在五个 NLI 数据集上,模型必须确定在给定前提下假设是否为真,FLAN 以较大优势超越了所有基线。正如 Brown et al. (2020) 所指出的,GPT-3 在 NLI 上表现不佳的一个原因可能是 NLI 示例不太可能自然地出现在无监督训练集中,因此被尴尬地表述为句子的延续。对于 FLAN,我们将 NLI 表述为更自然的问题“Does
阅读理解。 在阅读理解任务中,模型被要求回答关于所提供段落的问题,FLAN 在 MultiRC (Khashabi et al., 2018) 和 OBQA (Mihaylov et al., 2018) 上优于基线。在 BoolQ (Clark et al., 2019a) 上,FLAN 以较大优势优于 GPT-3,尽管 LaMDA-PT 在 BoolQ 上已经实现了高性能。
闭卷问答。 对于闭卷问答,它要求模型在没有访问包含答案的特定信息的情况下回答关于世界的问题,FLAN 在所有四个数据集上都优于 GPT-3。与 GLaM 相比,FLAN 在 ARC-e 和 ARC-c (Clark et al., 2018) 上表现更好,在 NQ (Lee et al., 2019; Kwiatkowski et al., 2019) 和 TQA (Joshi et al., 2017) 上表现略低。
翻译。 与 GPT-3 类似,LaMDA-PT 的训练数据约 90% 是英语,并包含一些未专门用于训练模型执行机器翻译的其他语言文本。我们还评估了 FLAN 在 GPT-3 论文中评估的三个数据集上的机器翻译性能:来自 WMT’14 的法英翻译 (Bojar et al., 2014),以及来自 WMT’16 的德英和罗英翻译 (Bojar et al., 2016)。与 GPT-3 相比,FLAN 在所有六项评估中都优于零样本 GPT-3,尽管在大多数情况下其表现不及少样本 GPT-3。与 GPT-3 类似,FLAN 在翻译成英语方面表现强劲,并与监督翻译基线相比表现良好。然而,从英语翻译成其他语言相对较弱,正如预期的那样,因为 FLAN 使用了英语 SentencePiece 分词器,且大部分预训练数据是英语。
附加任务。 尽管我们在上述任务聚类中看到了强劲的结果,但指令微调的一个局限性是它不能提高许多语言建模任务(例如,表述为句子补全的常识推理或指代消解任务)的性能。对于七个常识推理和指代消解任务(见附录表 2),FLAN 仅在七个任务中的三个上优于 LaMDA-PT。这一负面结果表明,当下游任务与原始语言建模预训练目标相同时(即指令在很大程度上是多余的情况),指令微调是没有用的。最后,我们在附录的表 2 和表 1 中报告了情感分析、释义检测和结构转文本的结果,以及 GPT-3 结果不可用的其他数据集。通常,零样本 FLAN 优于零样本 LaMDA-PT,并与少样本 LaMDA-PT 相当或更好。
4 消融研究与进一步分析
4.1 指令微调聚类的数量
由于我们论文的核心问题是指令微调如何提高模型在未见任务上的零样本性能,在第一次消融中,我们检查了性能如何受到指令微调中使用的聚类和任务数量的影响。对于此设置,我们保留 NLI、闭卷问答和常识推理作为评估聚类,并使用剩余的七个聚类进行指令微调。我们展示了从一个到七个指令微调聚类的结果,其中聚类按每个聚类的任务数量递减的顺序添加。
图 6 展示了这些结果。正如预期的那样,我们观察到随着我们添加额外的聚类和任务到指令微调中(情感分析聚类除外),三个保留聚类的平均性能有所提高,这证实了我们提出的指令微调方法在新型任务上的零样本性能的益处。更有趣的是,对于我们测试的七个聚类,性能似乎没有饱和,这意味着随着更多聚类添加到指令微调中,性能可能会进一步提高。值得注意的是,此消融不允许我们得出关于哪个指令微调聚类对每个评估聚类贡献最大的结论,尽管我们看到情感分析聚类的增加值最小。

图 6: 添加额外的任务聚类到指令微调中可提高在保留任务聚类上的零样本性能。评估任务如下。常识:CoPA, HellaSwag, PiQA, 和 StoryCloze。NLI:ANLI R1–R3, QNLI, RTE, SNLI, 和 WNLI。闭卷问答:ARC-easy, ARC-challenge, Natural Questions, 和 TriviaQA。
4.2 缩放定律
正如 Brown et al. (2020) 表明语言模型的零样本和少样本能力对于更大的模型有显著提高,我们接下来探索指令微调的益处如何受到模型规模的影响。使用与先前消融研究相同的聚类划分,我们评估了指令微调对 422M、2B、8B、68B 和 137B 参数模型的影响。
图 7 展示了这些结果。我们看到,对于 100B 参数量级的两个模型,指令微调显著提高了在保留任务上的性能,正如我们论文中先前结果所预期的那样。然而,8B 及更小模型的行为令人深思——指令微调实际上损害了在保留任务上的性能。这一结果的一个潜在解释可能是,对于小规模模型,学习指令微调期间使用的约 40 个任务填满了整个模型容量,导致这些模型在新任务上表现更差。在这种潜在解释下,对于更大规模的模型,指令微调填满了一些模型容量,但也教导了这些模型如何遵循指令,从而允许它们利用剩余的容量泛化到新任务。
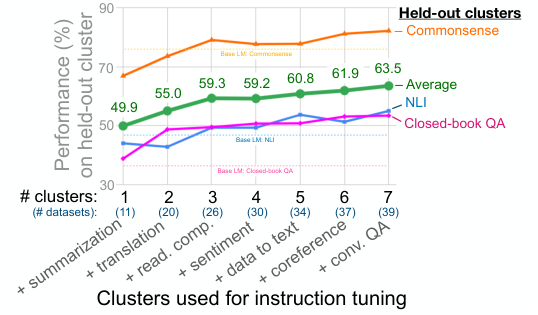
图 7: 指令微调帮助大型模型泛化到新任务,但对于小型模型,它实际上损害了对未见任务的泛化,这可能是因为所有模型容量都用于学习指令微调任务的混合。
4.3 指令的作用
在最后的消融研究中,我们探索了微调期间指令的作用,因为一种可能性是性能增益完全来自多任务微调,而模型在没有指令的情况下也能表现得同样好。因此,我们考虑了两种没有指令的微调设置。在“无模板”设置中,仅向模型提供输入和输出(例如,对于翻译,输入将是“The dog runs.”,输出将是“Le chien court.”)。在“数据集名称”设置中,每个输入都预置了任务和数据集的名称(例如,对于翻译成法语,输入将是“[Translation: WMT’14 to French] The dog runs.”)。
我们将这两个消融与 FLAN 的微调过程进行了比较,后者使用了自然指令(例如,“Please translate this sentence to French: ‘The dog runs.’”)。我们对图 5 中的四个保留聚类进行了评估。对于无模板设置,我们在零样本推理期间使用了 FLAN 指令(因为如果我们不使用模板,模型将不知道执行什么任务)。对于仅在数据集名称上微调的模型,我们报告了 FLAN 指令的零样本性能以及使用数据集名称的性能。图 8 展示了结果——两种消融配置的表现都明显差于 FLAN,这表明使用指令进行训练对于未见任务上的零样本性能至关重要。
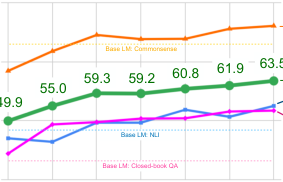
图 8: 使用从微调(FT)中移除指令的模型进行的消融研究结果。
4.4 带少样本示例的指令
到目前为止,我们专注于零样本设置下的指令微调。在这里,我们研究当推理时可以使用少样本示例时,如何使用指令微调。少样本设置的格式建立在零样本格式之上。对于某些输入 和输出 ,令 表示零样本指令。然后,给定 个少样本示例 和一个新的输入 ,少样本设置的指令格式为“”,其中 表示插入分隔符标记的字符串连接。在训练和推理时,示例都是从训练集中随机抽取的,示例数量上限为 16,且总序列长度小于 960 个标记。我们的实验使用与 §3 相同的任务划分和评估过程,使得未见任务的少样本示例仅在推理时使用。
如图 9 所示,与零样本 FLAN 相比,少样本示例提高了所有任务聚类的性能。示例对于具有大/复杂输出空间的任务(如结构转文本、翻译和闭卷问答)特别有效,这可能是因为示例帮助模型更好地理解输出格式。此外,对于所有任务聚类,少样本 FLAN 的模板间标准差更低,表明对提示工程的敏感性降低。
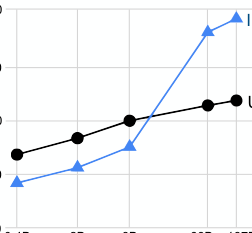
图 9: 添加少样本示例到 FLAN 是提高指令微调模型性能的补充方法。橙色条表示每个任务聚类在数据集级别平均的模板间标准差。
4.5 指令微调促进提示微调
正如我们已经看到指令微调提高了模型响应指令的能力,随之而来的是,如果 FLAN 确实更适合执行 NLP 任务,那么它在执行推理时使用软提示(soft prompts)时也应该实现更好的性能,软提示由通过提示微调优化的预置连续变量表示 (Li & Liang, 2021; Lester et al., 2021)。作为进一步分析,我们根据 §2.2 中的聚类划分,为每个 SuperGLUE (Wang et al., 2019a) 任务训练了连续提示,使得在任务 上进行提示微调时,在指令微调期间没有见过与 相同聚类的任务。我们的提示微调设置遵循 Lester et al. (2021) 的过程,除了我们使用 10 的提示长度、1e-4 的权重衰减,并且没有在注意力分数上使用 dropout;我们在初步实验中发现这些变化提高了 LaMDA-PT 的性能。
图 10 展示了这些提示微调实验的结果,包括使用全监督训练集和仅有 32 个训练示例的低资源设置。我们看到在所有场景中,提示微调与 FLAN 的配合比与 LaMDA-PT 的配合更好。在许多情况下,特别是在低资源设置中,对 FLAN 进行提示微调甚至比对 LaMDA-PT 进行提示微调实现了超过 10% 的改进。这一结果以另一种方式例证了指令微调如何产生一个更适合执行 NLP 任务的检查点。
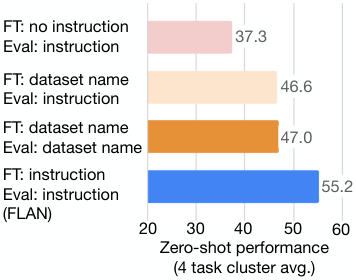
图 10: 指令微调模型对来自提示微调的连续输入响应更好。当在给定数据集上进行提示微调时,在指令微调期间没有见过与该数据集相同聚类的任务。显示的性能是 SuperGLUE 开发集上的平均值。
5 相关工作
我们的工作涉及几个广泛的研究领域,包括零样本学习、提示、多任务学习以及用于 NLP 应用的语言模型 (Radford et al., 2019; Raffel et al., 2020; Brown et al., 2020; Efrat & Levy, 2020; Aghajanyan et al., 2021; Li & Liang, 2021, inter alia)。我们在扩展的相关工作部分(附录 D)中描述了这些广泛领域的先前工作,在这里我们描述了两个范围较窄、可能与我们工作关系最密切的子领域。
我们要求模型响应指令的方式类似于基于 QA 的任务表述 (Kumar et al., 2016; McCann et al., 2018),其旨在通过将 NLP 任务表述为上下文上的 QA 来统一它们。虽然这些方法与我们的非常相似,但它们主要关注多任务学习而不是零样本学习,并且——正如 Liu et al. (2021) 所指出的——它们通常不是由利用预训练 LM 中的现有知识所驱动的。此外,我们的工作在模型规模和任务范围方面都超越了 Chai et al. (2020) 和 Zhong et al. (2021) 等近期工作。
语言模型的成功导致了对模型遵循指令能力的萌芽研究。最近,Mishra et al. (2021) 在带有少样本示例的指令上对 140M 参数的 BART 进行了微调,并评估了其在未见任务上的少样本能力——这类似于我们 §4.4 中的少样本指令微调结果。这一有希望的结果(以及 Ye et al. (2021) 的结果,尽管它不太强调指令)表明,在任务集合上进行微调可以提高在未见任务上的少样本性能,即使在较小的模型规模下也是如此。Sanh et al. (2021) 在类似于我们的设置中对 T5 进行了微调,发现可以在 11B 参数的模型中提高零样本学习能力。在与我们相似的模型规模下,OpenAI 的 InstructGPT 模型通过微调和强化学习进行训练,以产生人类评估者更偏好的输出 (Ouyang et al., 2022)。
6 讨论
我们的论文探讨了零样本提示中的一个简单问题:在表述为指令的任务集合上对模型进行微调是否能提高其在未见任务上的性能?我们通过指令微调将这个问题付诸实践,这是一种结合了预训练-微调和提示范式吸引人之处的简单方法。我们的指令微调模型 FLAN 提高了相对于未经微调模型的性能,并在我们评估的大多数任务上超越了零样本 GPT-3。消融研究表明,在未见任务上的性能随着指令微调任务聚类的数量而提高,并且有趣的是,指令微调带来的性能提升仅在模型规模足够大时才会显现。此外,指令微调可以与其他提示方法(如少样本提示和提示微调)相结合。
大规模语言模型的多样化能力引起了人们对专家模型(每个任务一个模型)和通才模型(许多任务一个模型;Arivazhagan et al., 2019; Pratap et al., 2020)之间权衡的关注,我们的研究对此具有潜在的意义。虽然人们可能期望标记数据在改进专家模型方面发挥最自然的作用,但指令微调展示了标记数据如何用于帮助大型语言模型执行许多未见任务。换句话说,指令微调对跨任务泛化的积极影响表明,特定任务的训练是对通用语言建模的补充,并激励了对通才模型的进一步研究。
关于我们研究的局限性,在将任务分配给聚类时存在一定程度的主观性(尽管我们尝试使用文献中公认的分类),并且我们仅探索了通常为单个句子的相对简短指令的使用(对比给予众包工人的详细指令)。我们评估的一个局限性是单个示例可能出现在模型的预训练数据中,其中包括网页文档,尽管在事后分析(附录 C)中,我们没有发现任何证据表明数据重叠显著影响了结果。最后,FLAN 137B 的规模使其服务成本高昂。指令微调的未来工作可能包括收集/生成更多用于微调的任务聚类、跨语言实验、使用 FLAN 生成用于训练下游分类器的数据,以及使用微调来改善模型在偏见和公平性方面的行为 (Solaiman & Dennison, 2021)。
7 结论
本文探讨了一种提高大规模语言模型纯粹基于指令执行零样本任务能力的简单方法。我们的指令微调模型 FLAN 与 GPT-3 相比表现良好,并预示了大规模语言模型遵循指令的潜在能力。我们希望我们的论文能激发对基于指令的 NLP、零样本学习以及使用标记数据改进大型语言模型的进一步研究。
伦理考量
本工作使用了语言模型,其风险和潜在危害在 Bender & Koller (2020)、Brown et al. (2020)、Bender et al. (2021)、Patterson et al. (2021) 等人中进行了讨论。由于我们在本文中的贡献不是预训练语言模型本身,而是关于指令微调如何影响语言模型在未见任务上的零样本性能的实证研究,我们额外强调了两个相关的伦理考量。首先,我们用于微调的标记数据集可能包含不期望的偏见,这些偏见可能会传播到模型在下游任务上的零样本应用中。其次,指令微调模型可能需要更少的数据和专业知识来使用;这种较低的访问门槛可能会增加此类模型的好处和相关风险。
环境考量
我们使用与 Austin et al. (2021) 相同的预训练语言模型。预训练模型的能源成本和碳足迹分别为 451 MWh 和 26 tCO2e。用于微调 FLAN 的额外指令微调梯度步数不到预训练步数的 2%,因此估计的额外能源成本相对较小。
作者贡献
Maarten Bosma 构思了最初的想法并实现了 FLAN 的第一个版本。Vincent Zhao 对训练和评估流水线以及排名分类进行了原型设计。Kelvin Guu 提出并实现了任务聚类和使用聚类间划分进行评估的想法。Jason Wei、Maarten Bosma、Vincent Zhao 和 Adams Wei Yu 实现了 NLP 任务。Jason Wei、Vincent Zhao 和 Adams Wei Yu 执行并管理了大部分实验。Jason Wei 设计并运行了消融研究。Jason Wei、Maarten Bosma 和 Quoc V. Le 撰写了大部分论文。Jason Wei、Maarten Bosma 和 Nan Du 获得了零样本和少样本基线。Vincent Zhao 和 Kelvin Guu 设计、实现并执行了少样本 FLAN 实验。Maarten Bosma 和 Jason Wei 进行了数据污染分析。Brian Lester 运行了提示微调实验。Quoc V. Le 和 Andrew M. Dai 提供了建议、高层指导,并帮助编辑了论文。
致谢
我们感谢 Ed Chi、Slav Petrov、Dan Garrette、Ruibo Liu 和 Clara Meister 对我们的手稿提供反馈。我们感谢 Adam Roberts、Liam Fedus、Hyung Won Chung 和 Noam Shazeer 帮助调试我们的一些模型。我们感谢 Ellie Pavlick 在项目中期对研究设计的反馈。我们感谢 Daniel De Freitas Adiwardana 帮助启动该项目、提供大型语言模型建议,并让我们访问了一些计算资源。最后,我们感谢参与预训练 LaMDA-PT 的团队:Daniel De Freitas Adiwardana、Noam Shazeer、Yanping Huang、Dmitry Lepikhin、Dehao Chen、Yuanzhong Xu 和 Zhifeng Chen。
参考文献
[此处省略参考文献列表,保持原论文格式]
A 附加结果
本节展示了我们评估的所有数据集的完整结果。翻译和结构转文本的结果显示在表 1 中,八个 NLU 任务聚类的结果显示在表 2 中。
我们展示了 FLAN 使用最多十个指令模板中的最佳模板以及开发集上性能最佳的模板的性能。对于 LaMDA-PT,我们使用 Brown et al. (2020) 的模板,这些模板是为 GPT-3 优化的,没有进行任何提示工程来在我们的模型上优化它们。为简单起见,我们对所有生成任务使用贪婪搜索(与 Brown et al. (2020) 中使用的束搜索相比)。与 GPT-3 不同,GPT-3 通过最佳开发集性能选择少样本示例数量 ,对于少样本 LaMDA-PT,我们选择适合 1024 个标记上下文长度的最高 ,从 中选择。
对于 DROP (Dua et al., 2019) 和 SQuADv2 (Rajpurkar et al., 2018),基于与 Brown et al. (2020) 的电子邮件通信,他们的零样本定义与我们的不同,因为他们实际上使用了示例,但仅来自与推理问题相同的段落(每个段落有多个问题)。因此,GPT-3 的零样本结果与我们的 DROP 和 SQuADv2 结果不可直接比较。我们使用 符号标记这些结果。此外,这两个数据集的答案结尾如何解析尚不清楚,因此我们使用花括号分隔符 和 ,我们期望 指示答案的结尾。
对于结构转文本,报告的 T5/mT5 结果来自 GEM 基准论文 (Gehrmann et al., 2021),尽管我们没有报告他们的 DART 结果(通过与作者的通信,我们确认他们 DART 的结果是不正确的)。虽然我们在指令微调期间使用了摘要任务聚类,但我们将摘要的评估留给未来的工作,因为大多数摘要数据集的平均输入超过了 FLAN 1024 个标记的输入长度。
| 指标 | 监督模型 | LaMDA-PT (零样本) | GPT-3 175B (零样本) | GPT-3 175B (少样本) | FLAN 137B (零样本 - 平均模板) | FLAN 137B (零样本 - 最佳开发模板) | FLAN 137B (少样本 - 平均模板) | FLAN 137B (少样本 - 最佳开发模板) | [k] | #t |
|---|---|---|---|---|---|---|---|---|---|---|
| 翻译 | ||||||||||
| WMT ’14 En→Fr BLEU | 35.0 | 11.2 | 25.2 | 31.5 | 32.9±1.1 | 33.9 | 33.9±0.2 | 33.8 | [9] | 5 |
| WMT ’14 Fr→En BLEU | 45.6 | 7.2 | 21.2 | 34.7 | 35.5±1.3 | 35.9 | 38.0±0.1 | 37.9 | [9] | 3 |
| WMT ’16 En→De BLEU | 38.6 | 7.7 | 24.6 | 26.7 | 25.4±1.8 | 27.0 | 26.8±0.4 | 26.1 | [11] | 5 |
| WMT ’16 De→En BLEU | 41.2 | 20.8 | 27.2 | 36.8 | 38.9±0.3 | 38.9 | 40.6±0.1 | 40.7 | [11] | 3 |
| WMT ’16 En→Ro BLEU | 39.9 | 3.5 | 14.1 | 22.9 | 16.7±1.6 | 18.9 | 20.5±0.1 | 20.5 | [9] | 5 |
| WMT ’16 Ro→En BLEU | 38.5 | 9.7 | 19.9 | 37.5 | 36.8±0.5 | 37.3 | 38.2±0.1 | 38.1 | [9] | 3 |
| 结构转文本 | ||||||||||
| CommonGen Rouge-1 | 64.0 | 3.9 | – | 56.7 | 54.6±2.3 | 56.3 | 56.6±0.3 | 56.4 | [16] | 6 |
| Rouge-2 | 29.4 | 1.5 | – | 29.6 | 28.8±2.4 | 27.6 | 30.9±0.7 | 29.9 | [16] | 6 |
| Rouge-L | 54.5 | 3.2 | – | 48.5 | 48.4±1.9 | 48.7 | 50.7±0.2 | 51.0 | [16] | 6 |
| DART Rouge-1 | – | 11.3 | – | 56.0 | 45.5±4.2 | 48.9 | 57.9±1.6 | 59.2 | [11] | 7 |
| Rouge-2 | – | 1.5 | – | 29.6 | 25.0±3.7 | 30.0 | 35.8±1.0 | 36.2 | [11] | 7 |
| Rouge-L | – | 3.2 | – | 48.5 | 38.4±3.8 | 43.4 | 48.5±0.9 | 48.2 | [11] | 7 |
| E2ENLG Rouge-1 | 72.6 | 6.2 | – | 56.7 | 44.8±3.9 | 51.4 | 59.1±1.3 | 59.7 | [12] | 9 |
| Rouge-2 | 47.5 | 2.5 | – | 31.4 | 24.2±3.6 | 30.1 | 33.2±1.1 | 33.6 | [12] | 9 |
| Rouge-L | 56.4 | 4.9 | – | 41.1 | 37.0±3.5 | 42.4 | 44.9±0.8 | 45.1 | [12] | 9 |
| WebNLG Rouge-1 | 83.5 | 13.9 | – | 68.3 | 50.6±4.7 | 57.7 | 68.5±2.2 | 71.2 | [10] | 8 |
| Rouge-2 | 63.6 | 6.9 | – | 46.0 | 29.8±4.2 | 35.4 | 48.0±1.5 | 49.8 | [10] | 8 |
| Rouge-L | 71.0 | 11.8 | – | 56.5 | 43.4±4.5 | 49.7 | 58.8±1.1 | 60.2 | [10] | 8 |
表 1: 翻译和结构转文本任务的结果。[k] 表示少样本示例的数量。#t 表示 FLAN 评估的模板数量。aT5-11B, cEdunov et al. (2018), dDurrani et al. (2014), eWang et al. (2019b), fSennrich et al. (2016), gLiu et al. (2020)。
| 数据集 | 随机猜测 | 监督模型 | GLaM (零样本) | LaMDA-PT (零样本) | LaMDA-PT (少样本 [k]) | GPT-3 175B (零样本) | GPT-3 175B (少样本 [k]) | FLAN 137B (零样本 - 平均模板) | FLAN 137B (零样本 - 最佳开发模板) | FLAN 137B (少样本 - 平均模板) | FLAN 137B (少样本 - 最佳开发模板 [k]) | #t |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NLI | ||||||||||||
| ANLI R1 | 33.3 | 57.4 | 40.9 | 42.4 | 39.6 [5] | 34.6 | 36.8 [50] | 47.7±1.4 | 46.4 | 44.2±2.3 | 47.9 [6] | 8 |
| ANLI R2 | 33.3 | 48.3 | 38.2 | 40.0 | 39.9 [5] | 35.4 | 34.0 [50] | 43.9±1.3 | 44.0 | 41.6±1.4 | 41.1 [6] | 8 |
| ANLI R3 | 33.3 | 43.5 | 40.9 | 40.8 | 39.3 [5] | 34.5 | 40.2 [50] | 47.0±1.3 | 48.5 | 42.8±2.2 | 46.8 [6] | 8 |
| CB | 33.3 | 93.6 | 33.9 | 73.2 | 42.9 [5] | 46.4 | 82.1 [32] | 64.1±14.7 | 83.9 | 82.6±4.4 | 82.1 [7] | 10 |
| MNLI-m | 33.3 | 92.2 | – | – | 35.7 [5] | – | – | 51.1±6.2 | 61.2 | 60.8±3.7 | 63.5 [10] | 10 |
| MNLI-mm | 33.3 | 91.9 | – | – | 37.0 [5] | – | – | 51.0±6.5 | 62.4 | 61.0±3.5 | 63.5 [10] | 10 |
| QNLI | 50.0 | 96.9 | – | – | 50.6 [5] | – | – | 59.6±4.9 | 66.4 | 62.0±1.7 | 63.3 [12] | 9 |
| RTE | 50.0 | 92.5 | 68.8 | 71.5 | 73.3 [5] | 63.5 | 72.9 [32] | 78.3±7.9 | 84.1 | 79.9±6.9 | 84.5 [8] | 10 |
| SNLI | 33.3 | 91.3 | – | – | 33.3 [5] | – | – | 43.0±7.4 | 53.4 | 62.3±2.4 | 65.6 [15] | 9 |
| WNLI | 50.0 | 94.5 | – | – | 56.3 [5] | – | – | 61.0±10.6 | 74.6 | 55.4±11.0 | 70.4 [14] | 10 |
| 阅读理解 | ||||||||||||
| BoolQ | 50.0 | 91.2 | 83.0 | 82.8 | 81.0 [1] | 60.5 | 77.5 [32] | 80.2±3.1 | 82.9 | 83.6±0.8 | 84.6 [4] | 9 |
| DROP | – | 80.5 | 54.9 | 55.2 | 3.8 [1] | 23.6† | 36.5 [20] | 21.9±0.9 | 22.7 | 22.3±1.1 | 23.9 [2] | 7 |
| MultiRC | – | 88.1 | 45.1 | 62.0 | 60.0 [5] | 72.9 | 74.8 [32] | 74.5±3.7 | 77.5 | 69.2±3.2 | 72.1 [1] | 8 |
| OBQA | 25.0 | 85.4 | 53.0 | 55.2 | 41.8 [10] | 57.6 | 65.4 [100] | 77.4±1.3 | 78.4 | 77.2±1.3 | 78.2 [16] | 7 |
| SQuADv1 | – | 96.2 | – | – | 22.7 [3] | – | – | 79.5±1.6 | 80.1 | 82.1±0.5 | 82.7 [4] | 8 |
| SQuADv2 | – | 83.4 | 68.3 | 70.0 | 11.1 [3] | 59.5† | 69.8 [16] | 40.9±1.8 | 44.2 | 40.8±0.9 | 43.1 [3] | 10 |
| 闭卷问答 | ||||||||||||
| ARC-c | 25.0 | 81.1 | 48.2 | 50.3 | 42.0 [10] | 51.4 | 51.5 [50] | 61.7±1.4 | 63.1 | 63.7±0.6 | 63.8 [13] | 7 |
| ARC-e | 25.0 | 92.6 | 71.9 | 76.6 | 76.4 [10] | 68.8 | 70.1 [50] | 79.5±0.8 | 79.6 | 80.5±0.5 | 80.7 [14] | 7 |
| NQ | – | 36.6 | 21.5 | 23.9 | 3.2 [5] | 14.6 | 29.9 [64] | 18.6±2.7 | 20.7 | 27.2±0.5 | 27.6 [16] | 10 |
| TQA (wiki) | – | 60.5 | 68.8 | 71.5 | 21.9 [10] | 64.3 | 71.2 [64] | 66.5±2.6 | 68.1 | 66.5±1.0 | 67.3 [16] | 10 |
| TQA (tfds-dev) | – | 51.0 | – | – | 18.4 [10] | – | – | 55.0±2.3 | 56.7 | 57.2±0.6 | 57.8 [16] | 10 |
| 常识 | ||||||||||||
| COPA | 50.0 | 94.8 | 90.0 | 92.0 | 90.0 [10] | 91.0 | 92.0 [32] | 90.6±2.0 | 91.0 | 88.5±3.8 | 87.0 [16] | 8 |
| HellaSwag | 25.0 | 47.3 | 77.1 | 76.8 | 57.0 [10] | 78.9 | 79.3 [20] | 56.4±0.5 | 56.7 | 59.4±0.2 | 59.2 [3] | 8 |
| PIQA | 50.0 | 66.8 | 80.4 | 81.4 | 80.3* [10] | 81.0 | 82.3 [50] | 80.9*±0.8 | 80.5* | 82.1*±0.3 | 81.7* [10] | 8 |
| StoryCloze | 50.0 | 89.2 | 82.5 | 84.0 | 79.5 [10] | 83.2 | 87.7 [70] | 92.2±1.3 | 93.4 | 93.3±0.9 | 94.7 [10] | 8 |
| 情感 | ||||||||||||
| IMDB | 50.0 | 95.5 | – | – | 76.9 [1] | – | – | 94.1±0.4 | 94.3 | 94.8±0.3 | 95.0 [2] | 7 |
| Sent140 | 50.0 | 87.0 | – | – | 41.4 [5] | – | – | 69.9±2.5 | 73.5 | 68.7±1.2 | 69.3 [16] | 6 |
| SST-2 | 50.0 | 97.5 | – | – | 51.0 [5] | 71.6 | 95.6 [8] | 92.6±1.7 | 94.6 | 94.4±0.8 | 94.6 [16] | 8 |
| Yelp | 50.0 | 98.1 | – | – | 84.7 [3] | – | – | 97.8±0.2 | 98.1 | 97.9±0.1 | 98.0 [4] | 7 |
| 释义 | ||||||||||||
| MRPC | 50.0 | 90.4 | – | – | 53.7 [5] | – | – | 69.1±1.3 | 69.1 | 67.5±1.7 | 67.2 [10] | 10 |
| QQP | 50.0 | 90.6 | – | – | 34.9 [3] | – | – | 72.1±6.8 | 75.9 | 73.5±2.9 | 75.9 [16] | 7 |
| PAWS Wiki | 50.0 | 91.9 | – | – | 45.5 [5] | – | – | 61.5±6.5 | 69.4 | 66.2±0.9 | 70.2 [10] | 10 |
| 指代消解 | ||||||||||||
| DPR | 50.0 | 84.8 | – | – | 54.6 [5] | – | – | 60.3±3.5 | 66.8 | 62.4±1.6 | 63.3 [16] | 10 |
| Winogrande | 50.0 | 65.8 | 73.4 | 73.0 | 68.3 [10] | 70.2 | 77.7 [50] | 67.3±2.5 | 71.2 | 72.3±0.9 | 72.8 [16] | 10 |
| WSC273 | 50.0 | 70.0 | 86.8 | 83.9 | 81.0 [5] | 88.3 | 88.5 [32] | 80.8±3.7 | – | – | – [–] | 10 |
| 阅读理解 (常识) | ||||||||||||
| CosmosQA | 25.0 | 67.1 | – | – | 34.1 [5] | – | – | 58.4±1.3 | 60.6 | 56.7±1.3 | 56.0 [5] | 8 |
| ReCoRD | – | 93.4 | 90.3 | 90.3 | 87.8* [1] | 90.2 | 89.0 [32] | 67.8*±3.0 | 72.5* | 77.0*±2.0 | 79.0* [1] | 10 |
表 2: 八个 NLU 任务聚类的结果。所有显示的值均为准确率(或精确匹配),DROP、MultiRC 以及 SQuAD v1 和 v2 除外,它们为 F1 分数。[k] 表示少样本示例的数量。#t 表示 FLAN 评估的模板数量。aT5-11B, bBERT-large。*参见数据污染(附录 C)。WSC273 (Levesque et al., 2012) 没有训练集或验证集,因此我们不计算 FLAN 的少样本结果。对于 Trivia QA (TQA),我们报告开发集维基百科子集上的精确匹配 (EM) 以与 GPT-3 进行比较,以及完整的 TFDS 开发集结果。