基础模型:机遇与风险
Rishi Bommasani*, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon, Niladri Chatterji, Annie Chen, Kathleen Creel, Jared Quincy Davis, Dorottya Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stefano Ermon, John Etchemendy, Kawin Ethayarajh, Li Fei-Fei, Chelsea Finn, Trevor Gale, Lauren Gillespie, Karan Goel, Noah Goodman, Shelby Grossman, Neel Guha, Tatsunori Hashimoto, Peter Henderson, John Hewitt, Daniel E. Ho, Jenny Hong, Kyle Hsu, Jing Huang, Thomas Icard, Saahil Jain, Dan Jurafsky, Pratyusha Kalluri, Siddharth Karamcheti, Geoff Keeling, Fereshte Khani, Omar Khattab, Pang Wei Koh, Mark Krass, Ranjay Krishna, Rohith Kuditipudi, Ananya Kumar, Faisal Ladhak, Mina Lee, Tony Lee, Jure Leskovec, Isabelle Levent, Xiang Lisa Li, Xuechen Li, Tengyu Ma, Ali Malik, Christopher D. Manning, Suvir Mirchandani, Eric Mitchell, Zanele Munyikwa, Suraj Nair, Avanika Narayan, Deepak Narayanan, Ben Newman, Allen Nie, Juan Carlos Niebles, Hamed Nilforoshan, Julian Nyarko, Giray Ogut, Laurel Orr, Isabel Papadimitriou, Joon Sung Park, Chris Piech, Eva Portelance, Christopher Potts, Aditi Raghunathan, Rob Reich, Hongyu Ren, Frieda Rong, Yusuf Roohani, Camilo Ruiz, Jack Ryan, Christopher Ré, Dorsa Sadigh, Shiori Sagawa, Keshav Santhanam, Andy Shih, Krishnan Srinivasan, Alex Tamkin, Rohan Taori, Armin W. Thomas, Florian Tramèr, Rose E. Wang, William Wang, Bohan Wu, Jiajun Wu, Yuhuai Wu, Sang Michael Xie, Michihiro Yasunaga, Jiaxuan You, Matei Zaharia, Michael Zhang, Tianyi Zhang, Xikun Zhang, Yuhui Zhang, Lucia Zheng, Kaitlyn Zhou, Percy Liang*
基础模型研究中心 (CRFM) 斯坦福以人为本人工智能研究院 (HAI) 斯坦福大学
人工智能正经历一场范式转移,随着在广泛数据上训练(通常使用大规模自监督学习)并可适应各种下游任务的模型(例如 BERT、DALL-E、GPT-3)的兴起,我们称这些模型为“基础模型”(foundation models),以强调其至关重要但尚不完整的特性。本报告对基础模型的机遇与风险进行了详尽的阐述,涵盖了它们的能力(例如语言、视觉、机器人操作、推理、人机交互)、技术原理(例如模型架构、训练过程、数据、系统、安全性、评估、理论)、应用领域(例如法律、医疗、教育)以及社会影响(例如不平等、滥用、经济和环境影响、法律和伦理考量)。尽管基础模型基于标准的深度学习和迁移学习,但其规模导致了新的涌现能力,并且它们在众多任务中的有效性激励了同质化。同质化提供了强大的杠杆作用,但也需要谨慎,因为基础模型的缺陷会被所有下游适配模型所继承。尽管基础模型即将得到广泛部署,但由于其涌现特性,我们目前对于它们如何工作、何时失效以及它们究竟具备什么能力缺乏清晰的理解。为了解决这些问题,我们认为,关于基础模型的大部分关键研究将需要与其根本的社会技术性质相称的深入跨学科合作。
目录
- 1 引言
- 1.1 涌现与同质化
- 1.2 社会影响与基础模型生态系统
- 1.3 基础模型的未来
- 1.4 本报告概述
- 2 能力
- 2.1 语言
- 2.2 视觉
- 2.3 机器人
- 2.4 推理与搜索
- 2.5 交互
- 2.6 理解的哲学
- 3 应用
- 3.1 医疗与生物医学
- 3.2 法律
- 3.3 教育
- 4 技术
- 4.1 建模
- 4.2 训练
- 4.3 适配
- 4.4 评估
- 4.5 系统
- 4.6 数据
- 4.7 安全与隐私
- 4.8 对分布偏移的鲁棒性
- 4.9 AI 安全与对齐
- 4.10 理论
- 4.11 可解释性
- 5 社会
- 5.1 不平等与公平
- 5.2 滥用
- 5.3 环境
- 5.4 合法性
- 5.5 经济学
- 5.6 规模的伦理
- 6 结论
- 致谢
- 参考文献
1 引言
本报告调查了一种构建人工智能 (AI) 系统的新兴范式,该范式基于我们称之为“基础模型”的一类通用模型。基础模型是指任何在广泛数据上训练(通常使用大规模自监督学习)并可适应(例如微调)到广泛下游任务的模型;目前的例子包括 BERT [Devlin et al. 2019]、GPT-3 [Brown et al. 2020] 和 CLIP [Radford et al. 2021]。从技术角度来看,基础模型并不新鲜——它们基于深度神经网络和自监督学习,这两者都已经存在了几十年。然而,过去几年基础模型的巨大规模和范围扩展了我们对可能性的想象;例如,GPT-3 拥有 1750 亿个参数,可以通过自然语言提示进行适配,在未经明确训练的情况下,在广泛的任务上表现出尚可的水平 [Brown et al. 2020]。与此同时,现有的基础模型有可能加剧危害,且其特性总体上知之甚少。鉴于它们即将得到广泛部署,它们已成为激烈审查的主题 [Bender et al. 2021]。
1.1 涌现与同质化
基础模型的重要性可以用两个词来概括:涌现(emergence)和同质化(homogenization)。涌现意味着系统的行为是隐式诱导的,而不是显式构建的;它既是科学兴奋的源泉,也是对意外后果的焦虑来源。同质化表明了在广泛应用中构建机器学习系统的方法论的整合;它为许多任务提供了强大的杠杆作用,但也造成了单点故障。为了更好地理解涌现和同质化,让我们回顾一下它们在过去 30 年 AI 研究中的兴起。
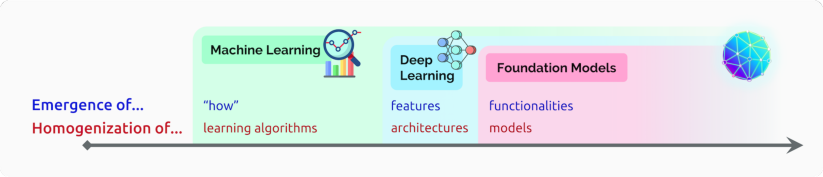 图 1. AI 的发展史一直伴随着涌现和同质化的增加。随着机器学习的引入,任务的执行方式从示例中涌现(自动推断);随着深度学习的出现,用于预测的高级特征涌现出来;而随着基础模型,甚至像上下文学习(in-context learning)这样的高级功能也涌现出来。与此同时,机器学习同质化了学习算法(例如逻辑回归),深度学习同质化了模型架构(例如卷积神经网络),而基础模型同质化了模型本身(例如 GPT-3)。
图 1. AI 的发展史一直伴随着涌现和同质化的增加。随着机器学习的引入,任务的执行方式从示例中涌现(自动推断);随着深度学习的出现,用于预测的高级特征涌现出来;而随着基础模型,甚至像上下文学习(in-context learning)这样的高级功能也涌现出来。与此同时,机器学习同质化了学习算法(例如逻辑回归),深度学习同质化了模型架构(例如卷积神经网络),而基础模型同质化了模型本身(例如 GPT-3)。
机器学习。 当今大多数 AI 系统都由机器学习驱动,其中预测模型在历史数据上进行训练,并用于进行未来预测。机器学习在 AI 领域内的兴起始于 20 世纪 90 年代,代表了 AI 系统构建方式的显著转变:与其指定如何解决任务,不如让学习算法根据数据诱导它——即“如何做”从学习的动态中涌现出来。机器学习也代表了迈向同质化的一步:广泛的应用现在可以由单一的通用学习算法(如逻辑回归)来驱动。
尽管机器学习在 AI 中无处不在,但自然语言处理 (NLP) 和计算机视觉中语义复杂的任务(如问答或对象识别,其中输入是句子或图像)仍然需要领域专家执行“特征工程”——即编写特定领域的逻辑,将原始数据转换为更适合流行机器学习方法的更高级特征(例如计算机视觉中的 SIFT [Lowe 1999])。
深度学习。 2010 年左右,深度神经网络在“深度学习” [LeCun et al. 2015] 的旗号下复兴,开始在机器学习领域获得关注。深度学习受到更大的数据集、更多的计算(特别是 GPU 的可用性)和更大的胆识的推动。深度神经网络将在原始输入(例如像素)上进行训练,更高级的特征将通过训练涌现出来(这一过程被称为“表征学习”)。这导致了标准基准测试性能的巨大提升,例如 AlexNet [Krizhevsky et al. 2012] 在 ImageNet 数据集 [Deng et al. 2009] 上的开创性工作。深度学习也反映了向同质化的进一步转变:与其为每个应用拥有定制的特征工程流水线,相同的深度神经网络架构可以用于许多应用。
基础模型。 基础模型在 NLP 中表现最为强烈,因此我们暂时将故事集中在那里。话虽如此,正如深度学习在计算机视觉中普及但存在于其之外一样,我们将基础模型理解为一种通用的 AI 范式,而不是以任何方式特定于 NLP。到 2018 年底,NLP 领域即将经历另一场地震式的变化,标志着基础模型时代的开始。在技术层面上,基础模型由迁移学习 [Thrun 1998] 和规模(scale)实现。迁移学习的思想是获取从一个任务(例如图像中的对象识别)中学到的“知识”,并将其应用于另一个任务(例如视频中的活动识别)。在深度学习中,预训练是迁移学习的主导方法:模型在代理任务上进行训练(通常只是手段),然后通过微调适配到感兴趣的下游任务。
迁移学习使基础模型成为可能,但规模使其强大。规模需要三个要素:(i) 计算机硬件的改进——例如,GPU 吞吐量和内存过去四年增加了 10 倍 (§4.5: 系统);(ii) Transformer 模型架构 [Vaswani et al. 2017] 的开发,它利用硬件的并行性来训练比以前更具表现力的模型 (§4.1: 建模);以及 (iii) 更多训练数据的可用性。
数据可用性的重要性和利用数据的能力不可低估。使用带注释数据集的迁移学习至少十年来一直是常见做法,例如计算机视觉社区在 ImageNet 数据集 [Deng et al. 2009] 上进行图像分类的预训练。然而,注释的非平凡成本对预训练的好处施加了实际限制。
另一方面,在自监督学习中,预训练任务是从未注释的数据中自动导出的。例如,用于训练 BERT [Devlin et al. 2019] 的掩码语言建模任务是在给定周围上下文的情况下预测句子中缺失的单词(例如,我喜欢 ____ 芽)。自监督任务不仅更具可扩展性(仅依赖未标记数据),而且它们旨在强制模型预测输入的部分,使其比在更有限的标签空间上训练的模型更丰富,且可能更有用。
自监督学习在深度学习早期就已占据主导地位 [Hinton et al. 2006],但随着标记数据集变得越来越大,它在十年间很大程度上被纯监督学习所取代。
自词嵌入 [Turian et al. 2010; Mikolov et al. 2013; Pennington et al. 2014] 以来,自监督学习取得了相当大的进展,它将每个单词与一个上下文无关的向量相关联,为广泛的 NLP 模型提供了基础。此后不久,基于自回归语言建模(给定前一个单词预测下一个单词)的自监督学习 [Dai and Le 2015] 变得流行。这产生了在上下文中表示单词的模型,例如 GPT [Radford et al. 2018]、ELMo [Peters et al. 2018] 和 ULMFiT [Howard and Ruder 2018]。
自监督学习发展的下一波浪潮——BERT [Devlin et al. 2019]、GPT-2 [Radford et al. 2019]、RoBERTa [Liu et al. 2019]、T5 [Raffel et al. 2019]、BART [Lewis et al. 2020a]——紧随其后,采用了 Transformer 架构,结合了更强大的句子双向编码器,并扩展到更大的模型和数据集。
虽然人们可以纯粹通过自监督学习的视角来看待这最后一波技术发展,但在 BERT 引入前后,存在一个社会学上的转折点。2019 年之前,使用语言模型的自监督学习本质上是 NLP 中的一个子领域,它与其他 NLP 的发展并行进行。2019 年之后,使用语言模型的自监督学习更多地成为了 NLP 的基质,因为使用 BERT 已成为常态。单一模型可以用于如此广泛的任务的接受度标志着基础模型时代的开始。
基础模型导致了前所未有的同质化水平:几乎所有最先进的 NLP 模型现在都是从少数几个基础模型(如 BERT、RoBERTa、BART、T5 等)中适配而来的。虽然这种同质化产生了极高的杠杆作用(基础模型的任何改进都可以带来整个 NLP 领域的直接收益),但它也是一种负债;所有 AI 系统都可能继承少数基础模型的相同问题偏差 [Bolukbasi et al. 2016; Caliskan et al. 2017; Abid et al. 2021, inter alia]——参见 §5.1: 公平性,§5.6: 伦理以获取进一步讨论。
我们也开始看到跨研究社区的同质化。例如,类似的基于 Transformer 的序列建模方法现在应用于文本 [Devlin et al. 2019; Radford et al. 2019; Raffel et al. 2019]、图像 [Dosovitskiy et al. 2020; Chen et al. 2020d]、语音 [Liu et al. 2020d]、表格数据 [Yin et al. 2020]、蛋白质序列 [Rives et al. 2021]、有机分子 [Rothchild et al. 2021] 和强化学习 [Chen et al. 2021b; Janner et al. 2021]。这些例子指向了一个可能的未来,即我们拥有一套统一的工具,用于在广泛的模态中开发基础模型 [Tamkin et al. 2021b]。
除了方法的同质化之外,我们还看到了跨研究社区的实际模型的同质化,即多模态模型——例如,在语言和视觉数据上训练的基础模型 [Luo et al. 2020; Kim et al. 2021a; Cho et al. 2021; Ramesh et al. 2021; Radford et al. 2021]。数据在某些领域自然是多模态的——例如医疗保健中的医学图像、结构化数据、临床文本 (§3.1: 医疗保健)。因此,多模态基础模型是融合关于某个领域的所有相关信息,并适配到也跨越多种模式的任务的自然方式(图 2)。
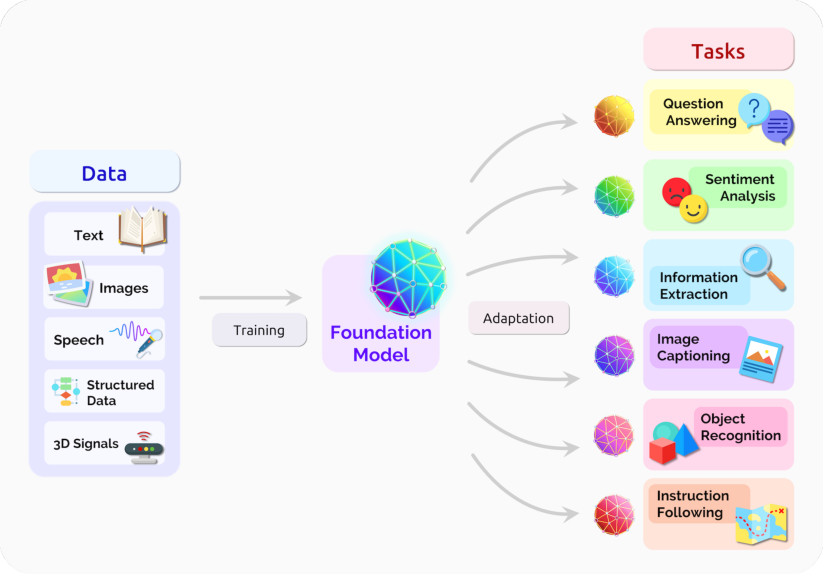 图 2. 基础模型可以集中来自各种模态的所有数据的信息。这一个模型然后可以适配到广泛的下游任务。
图 2. 基础模型可以集中来自各种模态的所有数据的信息。这一个模型然后可以适配到广泛的下游任务。
基础模型也导致了由规模带来的惊人涌现。例如,GPT-3 [Brown et al. 2020] 拥有 1750 亿个参数,相比 GPT-2 的 15 亿个参数,允许上下文学习(in-context learning),其中语言模型可以通过简单地提供提示(任务的自然语言描述)来适配到下游任务,这是一种既没有专门训练也没有预料到会出现的涌现属性。
同质化和涌现以一种潜在的不安方式相互作用。同质化可能为许多任务特定数据非常有限的领域提供巨大的收益——参见在几个此类领域中呈现的机遇(例如 §3.1: 医疗保健,§3.2: 法律,§3.3: 教育);另一方面,模型中的任何缺陷都会被所有适配模型盲目继承 (§5.1: 公平性,§5.6: 伦理)。由于基础模型的力量来自其涌现的品质,而不是其显式的构建,现有的基础模型很难理解 (§4.4: 评估,§4.10: 理论,§4.11: 可解释性),并且它们具有意想不到的失效模式 (§4.7: 安全性,§4.8: 鲁棒性)。由于涌现对基础模型的能力和缺陷产生了巨大的不确定性,通过这些模型进行激进的同质化是一项冒险的业务。从伦理 (§5.6: 伦理) 和 AI 安全 (§4.9: AI 安全) 的角度来看,降低风险是基础模型进一步发展的核心挑战。
1.1.1 命名。
我们引入“基础模型”一词来填补描述我们正在见证的范式转移的空白;我们简要回顾了我们做出这一决定的部分理由。现有术语(例如预训练模型、自监督模型)部分捕捉了这些模型的技术维度,但未能以一种对机器学习之外的人来说易于理解的方式捕捉到范式转移的意义。特别是,基础模型指定了一类在社会学影响方面具有独特性,以及它们如何赋予 AI 研究和部署广泛转变的模型。相比之下,在技术上预示了基础模型的预训练和自监督形式,未能阐明我们希望强调的实践转变。
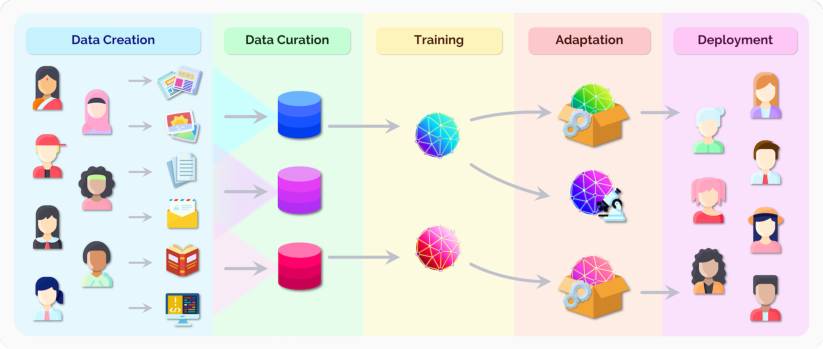 图 3. 在推理基础模型的社会影响之前,重要的是要了解它们是跨越从数据创建到部署的更广泛生态系统的一部分。在两端,我们强调了人作为基础模型训练数据的最终来源的作用,但也作为任何利益和危害的下游接受者。深思熟虑的数据管理和适配应该是任何 AI 系统负责任开发的一部分。最后,请注意,适配基础模型的部署是一个独立于其构建的决策,这可能是为了研究。
图 3. 在推理基础模型的社会影响之前,重要的是要了解它们是跨越从数据创建到部署的更广泛生态系统的一部分。在两端,我们强调了人作为基础模型训练数据的最终来源的作用,但也作为任何利益和危害的下游接受者。深思熟虑的数据管理和适配应该是任何 AI 系统负责任开发的一部分。最后,请注意,适配基础模型的部署是一个独立于其构建的决策,这可能是为了研究。
此外,虽然在撰写本文时许多标志性的基础模型都是语言模型,但“语言模型”一词对我们的目的来说太窄了:正如我们所描述的,基础模型的范围远不止语言。我们还考虑了“通用模型”和“多用途模型”等术语,它们捕捉到了这些模型可以服务于多个下游任务的重要方面,但两者都未能捕捉到它们未完成的特性和对适配的需求。诸如“任务无关模型”之类的术语可以捕捉训练方式,但未能捕捉到对下游应用的重大影响。
我们选择了新术语“基础模型”来标识本报告主题的模型和新兴范式。特别是,“基础”一词指定了这些模型所扮演的角色:基础模型本身是不完整的,但作为许多任务特定模型通过适配构建的共同基础。我们还选择“基础”一词来暗示架构稳定性、安全性和保障的重要性:构建不良的基础是灾难的根源,而执行良好的基础是未来应用的可靠基石。目前,我们强调我们并不完全理解基础模型所提供的基础的性质或质量;我们无法表征该基础是否值得信赖。因此,这是研究人员、基础模型提供商、依赖基础模型的应用开发人员、政策制定者以及整个社会需要解决的关键问题。
1.2 社会影响与基础模型生态系统
基础模型因其令人印象深刻的性能和能力而在科学上很有趣,但使它们成为关键研究对象的事实是,它们正迅速被整合到 AI 系统的现实部署中,对人们产生深远的影响。例如,拥有 40 亿用户的 Google 搜索现在依赖像 BERT [Devlin et al. 2019] 这样的基础模型作为其信号之一。
我们必须暂停并询问:这种社会影响的本质是什么?在本报告中,我们探讨了这一问题的许多方面:社会不平等的潜在加剧 (§5.1: 公平性)、由于能力提高带来的经济影响 (§5.5: 经济学)、由于计算需求增加带来的环境影响 (§5.3: 环境)、放大虚假信息的潜在担忧 (§5.2: 滥用)、由于强大的生成能力带来的法律后果 (§5.4: 合法性)、由于同质化产生的伦理问题,以及基础模型开发和部署的更广泛的政治经济学 (§5.6: 伦理)。鉴于基础模型的易变性和它们未映射的能力,我们如何负责任地预测和解决它们引发的伦理和社会考量?一个反复出现的主题是,推理部署给特定用户的特定系统的社会影响,比推理基础模型的社会影响更容易,因为基础模型可以适配到任何数量的不可预见的下游系统。
在尝试回答这些问题之前,我们需要奠定一些基础。首先,让我们区分基础模型的研究和基础模型的部署。公众所知的大部分是基础模型研究——通过学术论文、演示和排行榜上的进展。虽然知识的生产可以在塑造未来方面发挥至关重要的作用,但直接的社会影响是通过这些模型的实际部署,这受到专有数据上专有实践的支配。有时部署是通过新产品——例如,基于 OpenAI 的 Codex 模型 [Chen et al. 2021f] 的 GitHub Copilot,但通常是通过对现有产品的升级(例如,使用 BERT 的 Google 搜索)。研究模型通常没有经过广泛测试,并且可能具有未知的失效模式;应该在不适合部署的研究模型上放置警告标签。另一方面,实际影响人们生活的已部署基础模型应该受到更严格的测试和审计。
为了进一步了解基础模型的研究和部署,我们必须缩小范围,考虑这些基础模型所处的完整生态系统,从数据创建到实际部署。重要的是要注意,基础模型只是 AI 系统的一个组件(尽管是一个越来越重要的组件)。简化来看,我们可以根据之前的阶段序列来思考基础模型的生态系统,扩展了之前的训练和适配阶段。适当地,由于我们对社会影响感兴趣,人占据了流水线的两端。这种生态系统视图使我们能够看到关于基础模型的不同问题(例如,基础模型是否合乎伦理)实际上应该针对不同的阶段来回答。
(1) 数据创建:数据创建本质上是一个以人为中心的过程:所有数据都是由人创建的,大多数数据至少隐式地是关于人的。有时数据是由人为了其他人以电子邮件、文章、照片等形式创建的,有时它是人的测量(例如基因组数据)或人所居住环境的测量(例如卫星图像)。重要的是要注意,所有数据都有所有者,并且是出于某种目的而创建的(该目的可能包括也可能不包括训练基础模型)。 (2) 数据管理:数据随后被管理成数据集。没有单一的自然数据分布;即使是最宽松的互联网爬取也需要一些选择和后过滤。在尊重法律和伦理约束的同时确保数据的相关性和质量至关重要,但也具有挑战性。虽然这在工业界得到了认可,但在 AI 研究中却未得到充分重视 (§4.6: 数据)。 (3) 训练:在这些管理的数据集上训练基础模型是 AI 研究中著名的核心,尽管它只是众多阶段之一。 (4) 适配:在机器学习研究的背景下,适配是关于基于基础模型创建一个执行某种任务(例如文档摘要)的新模型。对于部署,适配是关于创建一个系统,这可能需要许多不同的模块、自定义规则(例如对输出空间的限制)或分类器(例如用于毒性分类),以及与其他互补信号的组合(例如,问答模型生成的答案将根据相关文档进行验证)。例如,如果下游采取了适当的预防措施,能够生成有毒内容的问题模型可能是可以容忍的。额外的应用特定逻辑对于减轻危害至关重要。 (5) 部署:AI 系统的直接社会影响发生在它部署给人们时。虽然我们不想部署在可疑数据上训练的潜在有害基础模型,但在研究中允许它们以推进科学理解可能仍然有价值,尽管仍然必须谨慎行事。更一般地说,在大规模部署中进行逐步发布是标准做法,其中部署发生在越来越多的用户群体中;这可以部分减轻任何潜在的危害。
虽然本报告是关于基础模型的,但重要的是要注意,许多影响来自流水线中其他阶段做出的决策,并且在每个阶段都需要深思熟虑的监控和干预。虽然大型组织可能拥有整个流水线,但每个阶段可能由不同的组织执行,例如,专门为应用开发人员可以使用的各种领域创建定制基础模型的公司。
思考生态系统,行动模型。 虽然社会影响取决于整个生态系统,但能够推理基础模型的社会影响仍然很重要,因为许多研究人员和从业者的权限仅限于训练阶段。这很困难,因为基础模型是未完成的中间对象,有时由完全不同的实体出于不可预见的目的适配到许多下游应用。我们需要的是两件事:(i) 用于一组代表性潜在下游评估的代理指标 (§4.4: 评估),以及 (ii) 记录这些指标的承诺 [Mitchell et al. 2019],类似于金属和塑料等材料的数据表,可以适配到许多下游用例。
表征基础模型的潜在下游社会影响具有挑战性,需要对技术生态系统和社会有深刻的理解。如果不认识到基础模型将如何部署,就无法完全评估其危害 (§5.1: 公平性),如果不考虑丰富的社会和历史背景,就无法仅定义自动指标。
1.3 基础模型的未来
基础模型已经展示了原始潜力,但我们仍处于早期阶段。尽管它们已部署到现实世界中,但这些模型在很大程度上仍是知之甚少的原型。即使是专业规范——罗伯特·默顿(Robert Merton)所说的科学精神 [Merton 1979]——围绕基础模型也是不发达的。例如,对于何时模型“安全”发布或社区应如何应对方法论不端行为等基本问题,缺乏共识。鉴于基础模型的未来因此充满了不确定性,一个大问题是:谁将决定这个未来?
学科多样性。 基础模型背后的技术基于机器学习、优化、NLP、计算机视觉和其他领域数十年的研究。这些技术贡献来自学术界和工业研究实验室。然而,构建基础模型本身的研究几乎完全发生在工业界——大型科技公司(如 Google、Facebook、Microsoft 或 Huawei)或初创公司(如 OpenAI 或 AI21 Labs),尽管 AI2 是一个显著的例外 [Peters et al. 2018; Zellers et al. 2019b]。
技术进步的狂热步伐和由于集中化导致的根深蒂固,引起了除技术专家外,还需要人文学家和社会科学家关注的强烈担忧。我们不应依赖仅在技术架构和部署决策做出后才进行的伦理和社会后果的事后审计。相反,我们需要从一开始就将社会考量和伦理设计深入注入基础模型及其周围生态系统的技术开发中。学术机构的独特之处在于它们在同一屋檐下拥有最广泛的学科,从而汇集了计算机科学家、社会科学家、经济学家、伦理学家、法律学者等。鉴于学科多样性在理解和解决结合技术、伦理、法律、社会和政治维度的问题方面的重要性 [Hong and Page 2004; Solomon 2006; Steel et al. 2018],我们因此认为学术界在以促进其社会利益和减轻其社会危害的方式开发基础模型方面发挥着至关重要的作用,并确定在生态系统的每个阶段(§1.2: 生态系统)中,从数据管理到部署的行动应该被严格禁止的背景。
激励机制。 设计、开发和部署基础模型的政治经济学为每个阶段的决策提供了不可避免的激励结构。人们和机构如何响应激励是经济学的一门基础课。市场驱动的商业激励可以与社会利益很好地结合:使基础模型更准确、可靠、安全和高效,同时搜索各种潜在用例可以产生巨大的社会效用。然而,商业激励也可能导致市场失灵和在股东无法捕捉创新价值的领域投资不足。正如制药行业几乎没有动力投入大量资源用于疟疾治疗的研究和开发,因为穷人买不起药物一样,科技行业几乎没有动力投入大量资源用于旨在改善贫困和边缘化人群状况的技术 [Reich et al. 2021]。更重要的是,商业激励可能导致公司忽视社会外部性 [Acemoglu 2021; Reich et al. 2021],例如劳动力技术替代、民主所需的知识生态系统的健康、计算资源的成本以及向非民主政权出售技术以获取利润。最后,任何公司都没有动力创建一个开放、去中心化的生态系统来开发基础模型,从而鼓励广泛参与。
相比之下,大学长期且根深蒂固的研究使命是知识的生产和传播以及全球公共产品的创造 [Kerr 2001; Rhoten and Calhoun 2011; Nussbaum 2010]。我们相信,学术界在塑造基础模型的开发方面处于独特的地位,以确保我们捕捉到具有巨大社会利益的方向,而这些方向可能不会被工业界优先考虑。
可访问性的丧失。 不幸的是,由于可访问性的丧失,学术界无法以尽可能充分的方式参与。深度学习革命中经常被忽视的影响之一是可重复性和开放科学的增加:公开共享代码和数据集,以及 TensorFlow [Abadi et al. 2016] 和 PyTorch [Paszke et al. 2019] 等软件包使人们更容易协作并建立在彼此的工作之上,这日益成为常态。像 ML 可重复性挑战以及主要会议采用的可重复性检查表 [Pineau et al. 2020] 等倡议,以及 CodaLab Worksheets 等平台,帮助推进了社区的可重复性标准。这导致了技术创新和进步的激增。
基础模型开始扭转这一积极趋势。有些模型(例如 GPT-3)根本没有发布(只有有限人群的 API 访问权限)。甚至数据集(例如 GPT-2 的数据集)也没有发布。虽然训练好的模型可能可用(例如 BERT),但基础模型的实际训练对绝大多数 AI 研究人员来说是不可用的,因为计算成本更高且工程要求复杂。
一些有意义的研究仍然可以通过在学术预算范围内训练较小的模型来完成,事实上,缩放定律 [Kaplan et al. 2020] 预测的惊人规律性使得这在规模差异是定量(例如准确性上升)的情况下成为一种可行的策略。然而,由于这些基础模型的涌现性质,一些功能(如上下文学习)仅在足够规模的模型中得到证明,因此需要规模来提出正确的问题。
也有可能富有成效地研究已经发布的预先存在的模型;事实上,这导致了 NLP 内部的一个大型子社区来探测这些模型 [Rogers et al. 2020; Manning et al. 2020]。拥有现有模型的访问权限对于驱动下游应用或识别缺陷(例如偏差)可能很有用,但这可能不足以让我们为基础模型设计更好的架构或训练目标来修复这些缺陷(例如减轻偏差)。值得反思的是,当今多少 NLP 研究是基于 BERT 的,这是一个特定的(且有些随意的)基础模型。鉴于需要将社会意识和伦理设计注入这些模型的构建中,我们可能需要构建看起来与当今存在的基础模型完全不同的基础模型。这将需要大规模的密集实验。
EleutherAI 和 Hugging Face 的 BigScience 项目等社区努力正试图训练大型基础模型,但工业界可以训练的私有模型与对社区开放的模型之间的差距如果不是扩大,也可能会保持巨大。此外,今天的初创公司(OpenAI、Anthropic、AI21 Labs 等)比学术界资源丰富得多,因此仍然有能力训练最大的基础模型(例如 OpenAI 的 GPT-3)。然而,大型科技公司在资源方面处于完全不同的水平,特别是在其市场地位带来的基础设施、用户和数据方面。基础模型的根本集中性质意味着开发它们的进入门槛将继续上升,以至于即使是初创公司,尽管它们很敏捷,也会发现难以竞争,这一趋势反映在搜索引擎的发展中 [Radinsky 2015]。
缩小资源差距的一种方法是政府投资公共基础设施。我们可以以哈勃太空望远镜和大型强子对撞机等大科学项目为灵感,这些项目的巨额投资使基础科学发现成为可能,而这些发现原本是不可能的。人们可以想象一个类似的计算基础设施,学术界对基础模型的研究将从中受益匪浅。在美国,新兴的“国家研究云”倡议是朝着这个方向迈出的一步。
另一种互补的方法是依赖志愿者计算,其中数十亿计算设备(节点)中的任何一个都可以连接到中央服务器并贡献计算。Folding@home 项目已成功实施了这种方法来模拟蛋白质动力学 [Beberg et al. 2009]。最近,Learning@home 项目正试图利用志愿者计算来训练基础模型 [Ryabinin and Gusev 2020]。节点之间的高延迟连接和训练基础模型的高带宽要求使其成为一个开放的技术挑战。
总结。 推动基础模型的能力和规模存在巨大的经济激励,因此我们预计未来几年技术将稳步进步。但主要依赖涌现行为的技术是否适合广泛部署给人们尚不清楚。显而易见的是,我们需要谨慎,现在是建立将使基础模型负责任的研究和部署的专业规范的时候了。学术界和工业界需要在这方面进行合作:工业界最终会对基础模型如何部署做出具体决策,但我们也应该依靠学术界,凭借其学科多样性和围绕知识生产和社会利益的非商业激励,为基础模型的开发和部署提供既在技术上又在伦理上扎实的独特指导。
1.4 本报告概述
2021 年 3 月,我们在斯坦福大学创建了一个由对基础模型某些方面感兴趣的学生、教职员工和研究人员组成的非正式社区。从一开始,该社区不仅包括 AI 研究人员,还包括那些渴望将基础模型应用于其领域(例如医疗保健和法律)的人,以及那些对社会问题(例如伦理和经济学)感兴趣的人。随着讨论的进行,我们注意到在相互理解方面存在许多差距——技术如何工作、工业界如何开发基础模型、如何思考伦理问题等,而现有文献只涵盖了零碎的部分。因此,我们希望提供一幅更全面的基础模型图景,识别机遇与风险,并为未来负责任的基础模型开发建立建设性的愿景。
本报告的撰写是一项实验:我们有 100 多名来自不同背景的人聚在一起,撰写了一份涵盖基础模型广泛方面的单一报告。本报告的大部分内容是对现有工作的调查,但通过多次讨论,我们将其统一在一份报告中,以突出所有的跨学科联系。
结构。 本报告分为 26 个部分,每一部分讨论基础模型的一个方面。这些部分分为四个部分:能力 (§2: 能力)、应用 (§3: 应用)、技术 (§4: 技术) 和社会 (§5: 社会),尽管各部分之间存在许多联系。这些联系突出了一个综合方法,其中技术和能力的开发方式对现实社会问题敏感,同时受到应用的启发并扎根于应用中。
虽然我们试图捕捉围绕基础模型的大多数重要主题,但本报告不可避免地是不完整的,特别是随着该领域的快速发展。例如,许多应用(例如自然科学、音乐、金融、农业)没有包括在内,尽管它们很可能像我们选择讨论的应用一样受到影响。研究基础模型如何与神经科学、认知科学和心理学研究相关联以解释智能,并帮助计算社会科学努力理解社会,也将是很有趣的。
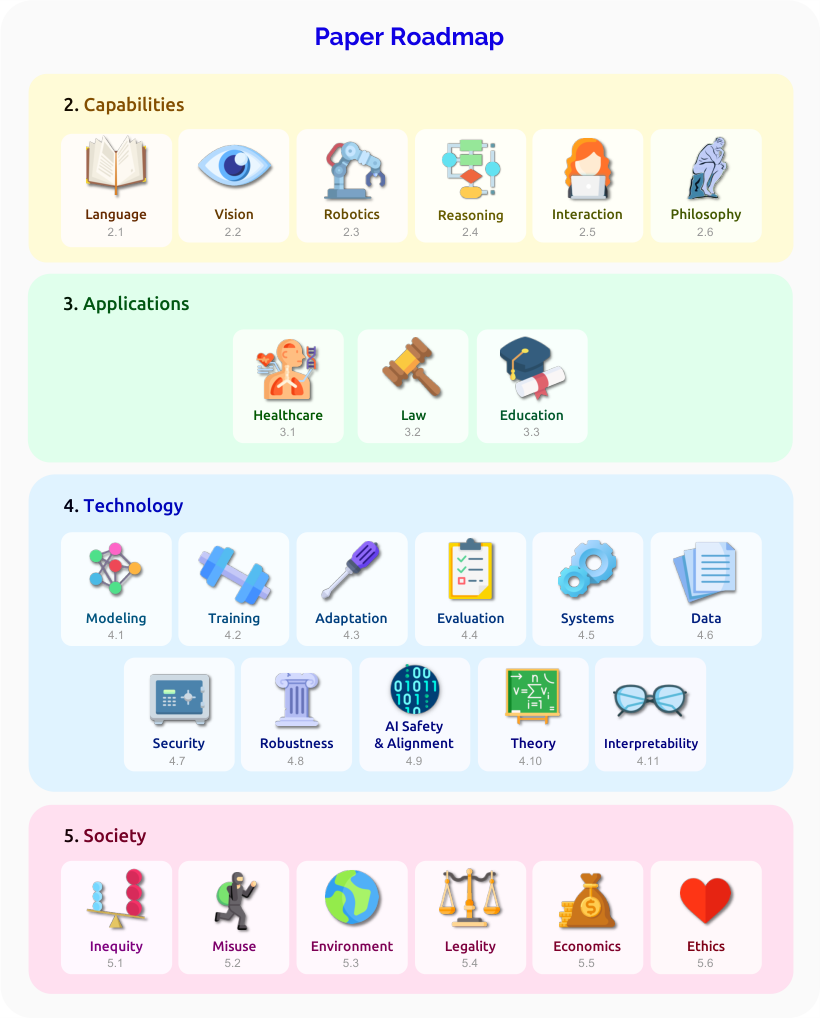 图 4. 本报告分为四个部分:能力、应用、技术和社会,其中每个部分包含一组部分,每个部分涵盖基础模型的一个方面。
图 4. 本报告分为四个部分:能力、应用、技术和社会,其中每个部分包含一组部分,每个部分涵盖基础模型的一个方面。
**研究基础模型如何与神经科学、认知科学和心理学研究相关联以解释智能,并帮助计算社会科学努力理解社会,也将是很有趣的。
作者贡献 Percy Liang 发起并概念化了整个报告的框架和结构。他和 Rishi Bommasani 共同领导了去中心化的写作工作,并对各个部分提供了指导。Drew A. Hudson 创建了报告中的所有图表,并与每个部分的作者讨论了它们的结构和内容。本报告的 26 个部分中的每一部分都由一部分作者撰写,他们的名字列在每个部分的开头。然而,有许多讨论跨越了多个部分,因此每个部分的实际贡献通常来自更广泛的群体。最后,我们指出,本报告中表达的观点并非所有作者都持有。
1.4.1 能力概述。
基础模型获得了可以驱动应用的各种能力。我们选择了讨论五种潜在能力:处理不同模态(例如语言、视觉)的能力、影响物理世界(机器人)的能力、执行推理的能力以及与人类交互(交互)的能力。最后,我们以关于其能力潜在局限性的哲学讨论作为总结。
§2.1: 语言。 NLP 作为一门学科为基础模型开辟了道路。虽然这些模型在标准基准测试中占据主导地位,但这些模型目前获得的能力与将语言作为人类交流和思想的复杂系统所具备的能力之间存在明显的差距。为了应对这一点,我们强调了语言变异(例如不同的风格、方言、语言)的全部范围,这既是机遇也是挑战,因为某些变体的数据有限。此外,儿童语言习得比基础模型的训练更具样本效率;我们研究了文本之外的信号和基础(grounding)如何帮助弥合这一差距。语言的这两个特征为未来的基础模型研究提供了明确的方向。
§2.2: 视觉。 计算机视觉引领了 AI 中深度学习的采用 [Russakovsky et al. 2015],证明了在大型带注释数据集上预训练的模型可以迁移到众多的下游设置中。现在,基础模型在计算机视觉领域兴起,它们在网络规模的原始数据而不是精选数据集上进行预训练 [例如,Radford et al. 2021]。这些模型在领域内的标准任务(如图像分类和对象检测)中显示出令人鼓舞的结果,并且在图像之外的多模态和具身数据上进行训练可能会在重大挑战(例如 3D 几何和物理理解、常识推理)上取得进展。我们还讨论了建模(例如有效扩展到视频的能力)和评估(例如更高阶能力的测量)中的一些关键挑战,以及将决定基础模型对计算机视觉未来影响的应用(例如医疗保健的环境智能)和社会考量(例如监控)。
§2.3: 机器人。 机器人研究的一个长期目标是开发能够在物理多样化环境中执行无数任务的“通用”机器人。与语言和视觉不同,语言和视觉由于拥有大量训练这些模型的原始数据以及可应用这些模型的虚拟应用而引领了基础模型的发展,机器人技术由于锚定在物理世界中而面临根本性的挑战。开发用于机器人技术的新型基础模型——其性质不同于其语言和视觉对应物——的主要挑战是获取足以促进学习的正确形式的数据:我们探索了不特定于特定环境且跨模态(例如语言、视觉)的丰富数据(例如人类的通用视频等)如何帮助弥合这一差距。这些新的机器人基础模型可以允许更容易的任务规范和学习,开启新的应用(例如更好的家庭任务机器人辅助),并提高鲁棒性和安全性(例如形式化安全评估)的重要性。
§2.4: 推理与搜索。 定理证明和程序合成等推理和搜索问题一直是 AI 中的长期挑战。组合搜索空间使得传统的基于搜索的方法难以处理。然而,众所周知,人类即使在最数学化的领域也能直观地操作 [Lakoff and Núñez 2000],事实上,像 AlphaGo 这样的现有工作已经表明深度神经网络在引导搜索空间方面是有效的。但人类也会跨任务迁移知识,从而促进更高效的适配和更抽象地推理的能力。基础模型提供了弥合这一差距的可能性:它们的多用途性质以及强大的生成和多模态能力为控制搜索固有的组合爆炸提供了新的杠杆。
§2.5: 交互。 基础模型显示出改变 AI 系统开发者和用户体验的明确潜力:由于其在适配方面的样本效率,基础模型降低了原型设计和构建 AI 应用的难度门槛,并由于其多模态和生成能力,提高了新型用户交互的上限。这提供了一种我们鼓励向前发展的协同效应:开发者可以提供更符合用户需求和价值观的应用,同时引入更动态的交互形式和反馈机会。
§2.6: 理解的哲学。 基础模型对其训练的数据能理解到什么程度?聚焦于自然语言的情况,我们确定了关于理解本质的不同立场,并探讨了它们与我们核心问题的相关性。我们的初步结论是,对未来基础模型理解自然语言的能力持怀疑态度可能为时过早,特别是在模型在多模态数据上进行训练的情况下。
1.4.2 应用概述。
目前,基础模型研究主要局限于计算机科学和 AI,基础模型及其支持的应用的影响主要集中在科技行业。展望未来,基础模型展现出明显的潜力,可以改变和扩展 AI 在科技行业之外的许多领域的覆盖范围,暗示对人们生活产生更广泛的影响。虽然有许多应用和领域需要考虑,但我们选择了三个应用——医疗保健、法律和教育——因为它们代表了我们社会的基石。为了让基础模型对这些应用领域做出重大贡献,模型将需要特定的能力 (§2: 能力) 以及技术创新 (§4: 技术) 来考虑每个领域的独特考量。此外,由于这些领域对社会功能至关重要 (§5: 社会),在这些领域应用基础模型需要处理深层的社会技术问题,例如与数据 (§4.6: 数据)、隐私 (§4.7: 安全性)、可解释性 (§4.11: 可解释性)、公平性 (§5.1: 公平性) 和伦理 (§5.6: 伦理) 相关的问题。
§3.1: 医疗与生物医学。 医疗任务(例如通过疾病治疗进行患者护理)和生物医学研究(例如新疗法的科学发现)需要有限且昂贵的专家知识。基础模型在这些领域提供了明确的机遇,因为它们拥有跨多种模态(例如图像、文本、分子)的大量数据来训练基础模型,以及由于专家时间和知识的成本而提高适配样本效率的价值。此外,基础模型可能允许为医疗保健提供者和患者与 AI 系统交互设计更好的界面 (§2.5: 交互),并且它们的生成能力暗示了药物发现等开放式研究问题的潜力。同时,它们也带来了明确的风险(例如加剧医疗数据集和试验中的历史偏差)。负责任地释放这一潜力需要深入参与社会技术问题,以及数据来源和隐私问题,以及模型可解释性和可解释性,同时对在医疗保健和生物医学中使用基础模型进行有效监管。
§3.2: 法律。 法律应用要求律师阅读并撰写包含不断变化的上下文和解读模糊法律标准的冗长连贯叙述。基础模型可能在这一领域提供好处:法律文件形式存在大量数据,其生成能力非常适合法律中所需的许多生成任务,但需要重大改进才能使基础模型能够可靠地对各种信息源进行推理,从而生成真实的冗长文档。正如医疗保健 (§3.1: 医疗保健) 中的情况一样,基础模型适配的样本效率在法律领域具有更高的价值,因为法律领域的专家时间和知识成本很高,这可能允许将专业知识重新分配给紧迫的正义和服务问题。负责任地为法律开发基础模型将需要对隐私进行具体考量,并突出现有基础模型的核心局限性,这些局限性将需要在其行为的来源(provenance)和其生成的真实性保证方面取得根本性进展。
§3.3: 教育。 教育是一个复杂而微妙的领域;有效的教学涉及对学生认知的推理,并应反映学生的学习目标。基础模型的性质在这里提出了尚未在 AI 教育领域实现的希望:虽然教育中的许多数据流单独来看太有限,无法训练基础模型,但利用领域外相关数据(例如互联网)的能力,以及联合利用跨多种模态(例如教科书、数学公式、图表、基于视频的教程)的数据的能力,为广泛适用于教育任务的基础模型提供了希望。如果基础模型导致教育相关能力的重大改进,那么在与开放式生成(例如问题生成)和交互式(例如对教师的反馈)方面相一致的新应用方面有明确的潜力;基础模型的样本高效适配暗示了自适应和个性化学习的更大能力。在这种情况下,需要重新考虑应用技术于教育的标志(例如学生隐私),同时某些担忧变得更加关键(例如教育中技术获取的不平等、技术辅助的剽窃)。
1.4.3 技术概述。
现在我们讨论构建更好的模型架构、训练和适配过程以及当然扩展系统背后的技术。一个关键但经常被忽视的主题是数据——它来自哪里,它的组成是什么?此外,我们希望基础模型对分布偏移具有鲁棒性,并能抵御攻击者。最后,我们希望从数学角度和经验角度理解为什么基础模型有效。
§4.1: 建模。 什么结构属性产生了基础模型?在建模部分,我们探索了基础模型背后的底层架构,并确定了 5 个关键属性。首先,我们从讨论计算模型的表现力(expressivity)开始——以捕捉和同化现实世界的信息,以及可扩展性(scalability)——以熟练处理大量高维数据。这些属性由现有的架构成功实现,例如支撑迄今为止大多数基础模型的 transformer 网络 [Vaswani et al. 2017]。然后,我们继续讨论下一代模型可能必不可少的属性,包括:多模态(multimodality)——以消费、处理并潜在地生成来自不同来源和领域的内容,内存容量(memory capacity)——以有效地存储和检索所获得的知识,最后是组合性(compositionality),以促进对新设置和环境的成功泛化。我们相信,实现基础模型所设想的全部潜力将取决于建模方面的进展,以满足这些愿望。
§4.2: 训练。 训练目标在数学上指定了模型应该如何从其训练数据中学习和获取能力。目前训练基础模型的现状涉及特定模态的目标(例如用于文本的掩码语言建模 [Devlin et al. 2019] 和用于图像的 SimCLR [Chen et al. 2020c]),这些目标通常是启发式选择的。我们设想,未来基础模型的训练目标将反映两个变化:源自系统证据和评估的原则性选择 (§4.4: 评估),以及提供跨数据源和模态的丰富、可扩展和统一训练信号的领域通用性。我们还讨论了重要的设计权衡,包括生成式与判别式训练、输入数据表示的选择,以及涉及显式目标表示的未来训练目标的潜力。
§4.3: 适配。 基础模型是中间资产;它们是不完整的,通常不应直接使用,而是需要针对特定的下游任务进行适配。适配的事实上的方法是微调,最近的研究表明轻量级微调替代方案和基于提示的方法可能实现有利的准确性-效率权衡。展望未来,我们设想了一种更广泛的适配观点,超越了仅仅专门化基础模型来执行感兴趣的任务:适配将减轻独立基础模型的缺陷(例如时间适配以反映世界随时间的变化)或引入约束(例如与被遗忘权相关的 GDPR 合规性;§4.7: 安全性);这种更广泛的适配视角与对新评估协议 (§4.4: 评估) 的需求相一致,这些协议系统地评估适配方法,同时控制适配中涉及的资源(例如运行时、内存)和访问要求。
§4.4: 评估。 评估通过提供跟踪进度、理解模型以及记录其能力和偏差的方法,为基础模型提供了上下文。基础模型挑战了机器学习中标准评估范式实现这些目标的能力,因为它们距离特定任务还有一步之遥。为了设想适合基础模型的新评估范式,我们讨论了 (a) 直接评估基础模型以测量其固有能力并告知基础模型如何训练,(b) 通过控制适配资源和访问来评估任务特定模型,以及 (c) 更广泛的评估设计,以提供超越准确性度量的更丰富上下文(例如鲁棒性 (§4.8: 鲁棒性)、公平性 (§5.1: 公平性)、效率 (§4.5: 系统)、环境影响 (§5.3: 环境))。评估实践的改革将允许评估充分服务于基础模型范式中涉及的各种目标和利益相关者。
§4.5: 系统。 虽然训练数据 (§4.6: 数据) 决定了基础模型的理论信息可用性,模型架构 (§4.1: 建模) 和训练目标 (§4.2: 训练) 决定了可以提取多少这些信息,但计算机系统决定了实际上什么是可实现的。系统是数据和模型规模扩展的关键瓶颈,这两者似乎都与能力的提高可靠地追踪。为了确保我们能够高效地(在时间和成本方面)训练下一代基础模型,我们将需要算法、模型、软件和硬件的协同设计。这种协同设计已经开始以各种形式发生,从精心调整的并行策略到检索式和混合专家模型等新架构。除了训练之外,我们还考虑在基础模型之上部署应用所需的条件(例如高效推理)。
§4.6: 数据。 数据是基础模型的生命线;这些模型的训练数据在很大程度上决定了这些模型可以获得什么能力。数据的中心地位并非基础模型所独有;最近对以数据为中心的 AI [Press 2021; Ré 2021] 的呼吁表明了管理、理解和记录用于训练机器学习模型的数据的普遍重要性。具体对于基础模型,目前的运作方式是使用未指定或不明确的原则选择训练数据,且对训练数据的性质缺乏普遍的透明度。我们认为需要一种替代方法来重新构想基础模型周围的数据生态系统:我们利用数据可视化和管理方面的工作,为基础模型提出一个数据中心(data hub)。我们阐述了这一提议如何与基础模型的许多相关数据中心考量相关:选择、管理、记录、访问、可视化和检查、质量评估以及法律监管。
§4.7: 安全与隐私。 目前,基础模型的安全和隐私在很大程度上是未知的。从根本上讲,基础模型是高杠杆的单点故障,使其成为攻击的主要目标:现有工作证明了这些模型的各种安全漏洞(例如生成不良输出的对抗性触发器)或隐私风险(例如训练数据的记忆)。此外,基础模型的通用性加剧了这些担忧,加剧了功能蔓延或双重用途(即用于非预期目的)的风险。对于安全性,我们将基础模型视为传统软件系统中的操作系统;我们讨论了迈向安全基础模型的步骤,如果实现,将为可靠的 ML 应用提供强大的抽象层。对于隐私,通过利用来自公共数据的知识迁移,基础模型可能实现对敏感数据分布更样本高效的适配,即在构建使用基础模型的应用时,隐私保护应用可能遭受较少的准确性下降。
§4.8: 对分布偏移的鲁棒性。 标准机器学习的一个主要局限性是它产生的模型对分布偏移不鲁棒,即训练分布与测试分布(对于下游任务)不匹配。现有工作表明,适配在广泛未标记数据上训练的基础模型可以提高适配模型在各种偏移中的鲁棒性。这为提高基础模型在鲁棒性方面的训练和适配开辟了一系列有希望的方向。然而,我们不认为基础模型是鲁棒性的灵丹妙药——跨时间外推和虚假相关性等挑战不太可能得到完全解决。
§4.9: AI 安全与对齐。 确保基础模型可靠 (§4.5: 系统)、鲁棒 (§4.8: 鲁棒性) 且可解释 (§4.11: 可解释性),在考虑这些模型的潜在现实应用时变得越来越重要。除了紧迫和直接的考量外,我们还考虑了基础模型与具有更大规模风险、危害和伤害的潜在关系,随着模型能力的不断提高,这些风险、危害和伤害的相关性可能会增加。例如,我们考虑了对齐基础模型的重要性,使其不会在部署时带有错误指定的任务目标或价值观。我们还讨论了预测基础模型涌现行为(例如欺骗或战略规划的能力)的相关性,这可能会使尝试将它们适配到特定任务变得复杂,并可能需要新的可解释性 (§4.11: 可解释性) 或评估 (§4.4: 评估) 方法。
§4.10: 理论。 学习理论为应用机器学习中遇到的各种上下文提供了广泛的基础;理论提供了理解、原则和保证,以补充经验发现。目前,对基础模型的研究在很大程度上是经验性的:标准监督学习的理论虽然相对成熟,但不足以完全解释基础模型。具体而言,训练阶段和适配阶段之间的差异在基础模型范式内指出了现有理论的不足,因为这些阶段对应于(潜在的)完全不同的任务和数据分布。尽管如此,我们努力通过理论上的进展来解决这种差异,即使是在简单、有限的设置中,也将提供有用的见解。
§4.11: 可解释性。 可解释性为基础模型提供了清晰度:支撑基础模型的深度神经网络的不透明性,以及基础模型的预期普遍性,加剧了理解这些模型及其能力的需要。目前的可解释性方法通常旨在解释和说明任务特定模型的行为;基础模型的性质(即这些模型有益的广泛任务范围以及它们获得的意外涌现属性)为可解释性研究引入了新的挑战。为了框架基础模型的可解释性讨论,我们提出了“一个模型-多个模型”范式,旨在确定一个模型(基础模型)及其多个模型(其适配的衍生产品)在多大程度上共享决策构建块。除了解释所涉及的决策组件外,我们还进一步讨论了基础模型背景下的可解释性(例如模型生成的后验解释的有效性)以及驱动模型行为的机制(这可能阐明理解基础模型在多大程度上可以扩展到理解其适配的衍生产品)。鉴于我们将可解释性在基础模型研究中赋予的关键作用,我们以对可解释性和不可解释性的社会影响的评估作为总结。
1.4.4 社会概述。
我们相信,基础模型的快速发展,适配并部署到各种应用中,将对社会的健康产生深远的影响。使这些模型如此令人兴奋但也如此令人不安的是它们的任务无关性。当我们谈论部署给用户的特定系统时,社会影响更容易(但仍然不平凡)理解和推理,但当我们开发基础模型时,我们如何考虑所有可能的系统和用例的社会影响?
§5.1: 不平等与公平。 在许多上下文中,机器学习已被证明有助于并可能放大社会不平等。基础模型可能会延续这一趋势,即进一步加剧对历史上受到歧视的人们的不公正待遇。然而,理解不平等与基础模型之间的关系需要考虑基础模型的抽象性;基础模型是适配到影响用户的应用的中间资产。因此,我们划定了内在偏差,即基础模型中预示危害的属性,以及外在危害,即在构建使用基础模型的特定应用的背景下产生的危害。我们对导致这些偏差和危害的各种来源(例如训练数据、基础模型开发者缺乏多样性、更广泛的社会技术背景)进行了分类,强调了理解伦理和法律责任的来源追踪的重要性以及技术难度。我们并不认为基础模型范式中的不公平是不可避免的:为了解决基础模型产生的不公平结果,我们双重考虑了主动干预(例如反事实数据增强等技术方法)和被动追索(例如反馈传播和道德/法律责任归属的机制)。
§5.2: 滥用。 我们将基础模型滥用定义为在技术上按预期使用基础模型(例如生成语言或视频),但目的是造成社会危害(例如生成虚假信息、开发用于骚扰的深度伪造)。我们认为,基础模型的进步将导致更高质量的机器生成内容,这些内容将更容易创建并针对滥用目的进行个性化。例如,虚假信息行为者可以使用它们快速生成针对不同人口群体(例如国籍、政党、宗教等)的集合文章。虽然这些新能力可能会限制现有的有害内容人类检测方法(例如跟踪跨不同来源的类似文本),但基础模型本身可能作为自动滥用检测器提供有希望的潜力。
§5.3: 环境。 基础模型是计算昂贵的训练制度的副产品,现有的轨迹倾向于更密集的模型;这种训练所需的能量与向大气中释放更多碳以及环境退化相吻合。目前,当前的讨论集中在这些巨大的单次训练成本以及在重复使用中摊销这些成本的潜力上。我们试图通过识别塑造基础模型环境影响计算的假设来澄清这些讨论。此外,我们设想基础模型周围的生态系统需要一种多方面的方法:(a) 更计算高效的模型、硬件和能源网格都可能减轻这些模型的碳负担,(b) 环境成本应该是一个明确的因素,告知基础模型如何评估 (§4.4: 评估),以便基础模型可以与更环保的基准进行更全面的并列,以及 (c) 围绕环境影响的成本效益分析需要在整个社区内进行更大的记录和测量。
§5.4: 合法性。 基础模型目前处于脆弱的法律基础上;法律如何影响这些模型的开发和使用在很大程度上尚不清楚。不仅需要针对基础模型的法律和监管框架,还需要针对更广泛的 AI 技术的法律和监管框架,以影响、约束甚至促进研究、开发和部署中的实践。以美国法律环境为中心,其中对算法工具的现有考量仍然广泛不确定,我们强调了模型预测的责任和模型行为保护的相关问题。关于这两个问题,我们描述了法律标准将如何需要进步以解决这些问题,鉴于基础模型的中间状态(相对于面向用户的任务特定模型)。
§5.5: 经济学。 基础模型很可能由于其新颖的能力和在各种行业和职业中的潜在应用而产生重大的经济影响。我们考虑了基础模型的发展和使用对美国和全球经济未来的影响,重点关注生产力、工资不平等和所有权集中。
§5.6: 规模的伦理。 除了运行增加不平等的风险外,正如 §5.1: 公平性中所讨论的那样,基础模型的广泛采用还带来了其他伦理、政治和社会担忧。我们讨论了与基础模型应用规模相关的伦理问题,例如同质化和权力集中,以及适当的发布策略来解决这些问题。
2 能力
基础模型获得了能力,其中一些从它们的学习过程中令人惊讶地涌现出来,这些能力驱动了下游应用 (§3: 应用)。具体而言,我们讨论语言 (§2.1: 语言) 和视觉 (§2.2: 视觉) 能力,以及影响物理世界 (§2.3: 机器人)、执行推理和搜索 (§2.4: 推理) 以及与人类交互 (§2.5: 交互) 的能力。此外,我们讨论自监督(用于训练大多数当前基础模型的技术方法)在哲学上如何与理解 (§2.6: 哲学) 的能力相关联。