LoRA:大型语言模型的低秩自适应 (Low-Rank Adaptation)
Edward Hu*, Yelong Shen*, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen Microsoft Corporation {edwardhu, yeshe, phwallis, zeyuana, yuanzhil, swang, luw, wzchen}@microsoft.com yuanzhil@andrew.cmu.edu (版本 2)
摘要
自然语言处理的一个重要范式包括在通用领域数据上进行大规模预训练,并针对特定任务或领域进行适配。随着我们预训练的模型规模越来越大,对所有模型参数进行重训练的“全量微调”变得越来越不可行。以 GPT-3 175B 为例,部署每个拥有 175B 参数的独立微调模型实例的成本高得令人望而却步。我们提出了低秩自适应(Low-Rank Adaptation,简称 LoRA),它冻结预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,从而大大减少了下游任务的可训练参数数量。与使用 Adam 微调的 GPT-3 175B 相比,LoRA 可以将可训练参数数量减少 10,000 倍,并将 GPU 内存需求减少 3 倍。尽管可训练参数更少、训练吞吐量更高,且与适配器(adapters)不同,不会引入额外的推理延迟,但 LoRA 在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 上的模型质量表现与微调相当甚至更好。我们还对语言模型适配中的秩亏(rank-deficiency)问题进行了实证研究,这揭示了 LoRA 的有效性。我们发布了一个软件包,旨在促进 LoRA 与 PyTorch 模型的集成,并提供了我们在 RoBERTa、DeBERTa 和 GPT-2 上的实现和模型检查点,地址为:https://github.com/microsoft/LoRA。
1 引言
自然语言处理中的许多应用依赖于将一个大规模预训练语言模型适配到多个下游应用中。这种适配通常通过微调(fine-tuning)来完成,即更新预训练模型的所有参数。微调的主要缺点是新模型包含与原始模型相同数量的参数。随着每隔几个月就有更大的模型被训练出来,这对于 GPT-2 (Radford et al., b) 或 RoBERTa large (Liu et al., 2019) 来说仅仅是“不便”,但对于拥有 1750 亿可训练参数的 GPT-3 (Brown et al., 2020) 来说,则演变成了一个关键的部署挑战。
许多人试图通过仅适配部分参数或为新任务学习外部模块来缓解这一问题。这样,我们只需要为每个任务存储和加载少量特定于任务的参数,并附加到预训练模型上,从而在部署时大大提高了操作效率。然而,现有的技术通常会通过增加模型深度或减少模型可用的序列长度 (Li & Liang, 2021; Lester et al., 2021; Hambardzumyan et al., 2020; Liu et al., 2021) 来引入推理延迟 (Houlsby et al., 2019; Rebuffi et al., 2017)(第 3 节)。更重要的是,这些方法通常无法达到微调的基准水平,在效率和模型质量之间造成了权衡。
我们从 Li et al. (2018a); Aghajanyan et al. (2020) 的研究中获得灵感,这些研究表明,学习到的过参数化模型实际上位于一个较低的内在维度上。我们假设模型适配过程中的权重变化也具有较低的“内在秩”,从而引出了我们提出的低秩自适应(LoRA)方法。如图 1 所示,LoRA 允许我们通过在适配过程中优化密集层变化的秩分解矩阵,间接地训练神经网络中的某些密集层,同时保持预训练权重冻结。以 GPT-3 175B 为例,我们证明了即使在全秩(即 )高达 12,288 的情况下,极低的秩(即图 1 中的 可以为 1 或 2)也已足够,这使得 LoRA 在存储和计算上都非常高效。
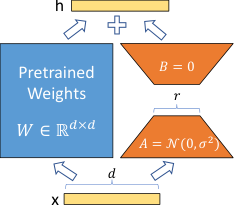
LoRA 具有几个关键优势:
- 预训练模型可以被共享,并用于为不同任务构建许多小的 LoRA 模块。我们可以冻结共享模型,并通过替换图 1 中的矩阵 和 来高效地切换任务,从而显著降低存储需求和任务切换开销。
- LoRA 使训练更高效,并在使用自适应优化器时将硬件准入门槛降低了多达 3 倍,因为我们不需要计算大多数参数的梯度或维护优化器状态。相反,我们只优化注入的、小得多的低秩矩阵。
- 我们简单的线性设计允许在部署时将可训练矩阵与冻结权重合并,通过构造,与全量微调模型相比,不会引入任何推理延迟。
- LoRA 与许多现有方法正交,可以与其中许多方法结合使用,例如前缀微调(prefix-tuning)。我们在附录 E 中提供了一个示例。
术语和约定 我们频繁引用 Transformer 架构并使用其维度的常规术语。我们将 Transformer 层的输入和输出维度大小称为 。我们使用 和 来指代自注意力模块中的查询/键/值/输出投影矩阵。 或 指预训练权重矩阵, 指适配期间累积的梯度更新。我们使用 来表示 LoRA 模块的秩。我们遵循 (Vaswani et al., 2017; Brown et al., 2020) 设定的约定,使用 Adam (Loshchilov & Hutter, 2019; Kingma & Ba, 2017) 进行模型优化,并使用 Transformer MLP 前馈维度 。
2 问题陈述
虽然我们的提议与训练目标无关,但我们专注于语言建模作为我们的动机用例。以下是对语言建模问题的简要描述,特别是给定特定任务提示(prompt)时条件概率的最大化。
假设我们给定一个由 参数化的预训练自回归语言模型 。例如, 可以是基于 Transformer 架构 (Vaswani et al., 2017) 的通用多任务学习器,如 GPT (Radford et al., b; Brown et al., 2020)。考虑将此预训练模型适配到下游条件文本生成任务,如摘要、机器阅读理解 (MRC) 和自然语言转 SQL (NL2SQL)。每个下游任务由上下文-目标对的训练数据集表示:,其中 和 都是标记(token)序列。例如,在 NL2SQL 中, 是自然语言查询, 是相应的 SQL 命令;对于摘要, 是文章内容, 是其摘要。
在全量微调期间,模型初始化为预训练权重 ,并通过重复遵循梯度来更新为 ,以最大化条件语言建模目标:
全量微调的主要缺点之一是,对于每个下游任务,我们学习一组不同的参数 ,其维度 等于 。因此,如果预训练模型很大(例如 亿的 GPT-3),存储和部署许多独立的微调模型实例可能具有挑战性,甚至不可行。
在本文中,我们采用了一种更具参数效率的方法,其中特定于任务的参数增量 由一组更小的参数 进一步编码,且 。因此,寻找 的任务变成了在 上进行优化:
在随后的章节中,我们建议使用低秩表示来编码 ,这在计算和内存上都是高效的。当预训练模型为 GPT-3 175B 时,可训练参数 的数量可以小至 的 0.01%。
3 现有解决方案足够好吗?
我们着手解决的问题绝非新问题。自迁移学习诞生以来,数十项工作试图使模型适配更具参数和计算效率。关于一些知名工作的综述,请参阅第 6 节。以语言建模为例,在高效适配方面有两种突出的策略:添加适配器层(adapter layers)(Houlsby et al., 2019; Rebuffi et al., 2017; Pfeiffer et al., 2021; Rücklé et al., 2020) 或优化输入层激活的某些形式 (Li & Liang, 2021; Lester et al., 2021; Hambardzumyan et al., 2020; Liu et al., 2021)。然而,这两种策略都有其局限性,特别是在大规模和延迟敏感的生产场景中。
适配器层引入推理延迟 适配器有许多变体。我们关注 Houlsby et al. (2019) 的原始设计,它每个 Transformer 块有两个适配器层,以及 Lin et al. (2020) 的较新设计,每个块只有一个适配器层,但带有额外的 LayerNorm (Ba et al., 2016)。虽然可以通过剪枝层或利用多任务设置 (Rücklé et al., 2020; Pfeiffer et al., 2021) 来降低整体延迟,但没有直接的方法可以绕过适配器层中的额外计算。由于适配器层通过具有小的瓶颈维度(有时 < 原始模型的 1%)来设计为具有很少的参数,这限制了它们可以增加的 FLOPs,因此这似乎不是一个问题。然而,大型神经网络依赖硬件并行性来保持低延迟,而适配器层必须按顺序处理。这在批处理大小通常小至 1 的在线推理设置中产生了差异。在没有模型并行的通用场景中,例如在单个 GPU 上运行 GPT-2 (Radford et al., b) medium,即使使用非常小的瓶颈维度,我们也会在使用适配器时看到明显的延迟增加(表 1)。
当我们需要像 Shoeybi et al. (2020); Lepikhin et al. (2020) 那样对模型进行分片(shard)时,这个问题会变得更糟,因为额外的深度需要更多的同步 GPU 操作,如 AllReduce 和 Broadcast,除非我们多次冗余地存储适配器参数。
直接优化提示(Prompt)很困难 另一个方向,以前缀微调(prefix tuning)(Li & Liang, 2021) 为例,面临着不同的挑战。我们观察到前缀微调很难优化,并且其性能在可训练参数方面呈非单调变化,这证实了原始论文中的类似观察。更根本的是,为适配预留一部分序列长度必然会减少处理下游任务可用的序列长度,我们怀疑这使得调整提示比其他方法表现更差。我们将任务性能的研究推迟到第 5 节。
| 批处理大小 | 32 | 16 | 1 |
|---|---|---|---|
| 序列长度 | 512 | 256 | 128 |
| $ | \Theta | $ | 0.5M |
| 微调/LoRA | 1449.4±0.8 | 338.0±0.6 | 19.8±2.7 |
| Adapter | 1482.0±1.0 (+2.2%) | 354.8±0.5 (+5.0%) | 23.9±2.1 (+20.7%) |
| Adapter | 1492.2±1.0 (+3.0%) | 366.3±0.5 (+8.4%) | 25.8±2.2 (+30.3%) |
表 1:GPT-2 medium 中单次前向传递的推理延迟(以毫秒为单位),取 100 次试验的平均值。我们使用 NVIDIA Quadro RTX8000。“”表示适配器层中可训练参数的数量。Adapter 和 Adapter 是适配器微调的两种变体,我们在第 5.1 节中进行了描述。适配器层引入的推理延迟在在线、短序列长度场景中可能很显著。请参阅附录 B 中的完整研究。
4 我们的方法
我们描述了 LoRA 的简单设计及其实际益处。此处概述的原则适用于深度学习模型中的任何密集层,尽管在我们的实验中,我们仅将 Transformer 语言模型中的某些权重作为动机用例。
4.1 低秩参数化更新矩阵
神经网络包含许多执行矩阵乘法的密集层。这些层中的权重矩阵通常是全秩的。在适配特定任务时,Aghajanyan et al. (2020) 表明,预训练语言模型具有较低的“内在维度”,即使随机投影到较小的子空间,仍然可以高效学习。受此启发,我们假设权重更新在适配期间也具有较低的“内在秩”。对于预训练权重矩阵 ,我们通过用低秩分解来表示其更新来约束它:,其中 ,,且秩 。在训练期间, 被冻结且不接收梯度更新,而 和 包含可训练参数。注意 和 都与相同的输入相乘,并且它们各自的输出向量按坐标相加。对于 ,我们的修改后前向传递产生:
我们在图 1 中说明了我们的重参数化。我们对 使用随机高斯初始化,对 使用零初始化,因此 在训练开始时为零。然后,我们将 缩放 ,其中 是 中的一个常数。使用 Adam 优化时,如果我们适当地缩放初始化,调整 大致等同于调整学习率。因此,我们只需将 设置为我们尝试的第一个 ,而不对其进行调整。这种缩放有助于在改变 时减少重新调整超参数的需要 (Yang & Hu, 2021)。
全量微调的泛化 更通用的微调形式允许训练预训练参数的子集。LoRA 更进一步,不需要累积的梯度更新到权重矩阵在适配期间具有全秩。这意味着当将 LoRA 应用于所有权重矩阵并训练所有偏置项时,通过将 LoRA 秩 设置为预训练权重矩阵的秩,我们大致恢复了全量微调的表达能力。换句话说,随着我们增加可训练参数的数量,训练 LoRA 大致收敛于训练原始模型,而基于适配器的方法收敛于 MLP,基于前缀的方法收敛于无法处理长输入序列的模型。
无额外推理延迟 当在生产中部署时,我们可以显式计算并存储 并照常执行推理。注意 和 都在 中。当我们切换到另一个下游任务时,我们可以通过减去 然后加上不同的 来恢复 ,这是一个内存开销极小的快速操作。至关重要的是,这保证了我们通过构造与微调模型相比不会引入任何额外的推理延迟。
4.2 将 LoRA 应用于 Transformer
原则上,我们可以将 LoRA 应用于神经网络中的任何权重矩阵子集,以减少可训练参数的数量。在 Transformer 架构中,自注意力模块中有四个权重矩阵 (),MLP 模块中有两个。我们将 (或 )视为维度为 的单个矩阵,即使输出维度通常被切分为注意力头。为了简单和参数效率,我们将研究限制为仅适配下游任务的注意力权重,并冻结 MLP 模块(因此它们在下游任务中不被训练)。我们在第 7.1 节中进一步研究了适配 Transformer 中不同类型注意力权重矩阵的效果。我们将适配 MLP 层、LayerNorm 层和偏置项的实证研究留给未来的工作。
实际益处和局限性 最显著的益处来自内存和存储使用量的减少。对于使用 Adam 训练的大型 Transformer,如果 ,我们将 VRAM 使用量减少了多达 2/3,因为我们不需要存储冻结参数的优化器状态。在 GPT-3 175B 上,我们将训练期间的 VRAM 消耗从 1.2TB 减少到 350GB。当 且仅适配查询和值投影矩阵时,检查点大小减少了大约 10,000 倍(从 350GB 到 35MB)。这使我们能够使用明显更少的 GPU 进行训练并避免 I/O 瓶颈。另一个好处是,我们可以在部署时通过仅交换 LoRA 权重而不是所有参数,以更低的成本在任务之间切换。这允许创建许多定制模型,这些模型可以在存储预训练权重的机器上即时交换。我们还观察到在 GPT-3 175B 上训练速度提高了 25%,与全量微调相比,因为我们不需要计算绝大多数参数的梯度。
LoRA 也有其局限性。例如,如果选择将 和 吸收到 中以消除额外的推理延迟,则在单次前向传递中将不同任务的输入与不同的 和 进行批处理并不直接。虽然可以不合并权重,并为批处理中的样本动态选择要使用的 LoRA 模块,适用于延迟不是关键的场景。
5 实证实验
我们在 RoBERTa (Liu et al., 2019)、DeBERTa (He et al., 2021) 和 GPT-2 (Radford et al., b) 上评估了 LoRA 的下游任务性能,然后扩展到 GPT-3 175B (Brown et al., 2020)。我们的实验涵盖了从自然语言理解 (NLU) 到生成的广泛任务。具体来说,我们在 RoBERTa 和 DeBERTa 的 GLUE (Wang et al., 2019) 基准上进行了评估。我们遵循 Li & Liang (2021) 在 GPT-2 上的设置进行直接比较,并增加了 WikiSQL (Zhong et al., 2017)(NL 转 SQL 查询)和 SAMSum (Gliwa et al., 2019)(对话摘要)用于 GPT-3 上的大规模实验。有关我们使用的数据集的更多详细信息,请参阅附录 C。我们在所有实验中使用 NVIDIA Tesla V100。
5.1 基线
为了广泛地与其他基线进行比较,我们复制了先前工作使用的设置,并尽可能重用他们报告的数字。然而,这意味着某些基线可能仅出现在某些实验中。
微调 (FT) 是适配的常用方法。在微调期间,模型初始化为预训练权重和偏置项,所有模型参数都进行梯度更新。一个简单的变体是仅更新某些层而冻结其他层。我们包含了先前工作 (Li & Liang, 2021) 在 GPT-2 上报告的一个此类基线,它仅适配最后两层 (FT)。
仅偏置 (Bias-only) 或 BitFit 是一种基线,我们仅训练偏置向量,同时冻结其他所有内容。同时,该基线也由 BitFit (Zaken et al., 2021) 研究过。
前缀嵌入微调 (PreEmbed) 在输入标记中插入特殊标记。这些特殊标记具有可训练的词嵌入,通常不在模型的词汇表中。放置这些标记的位置会对性能产生影响。我们专注于“前缀化”(prefixing),即在提示前添加此类标记,以及“中缀化”(infixing),即在提示后附加;两者都在 Li & Liang (2021) 中进行了讨论。我们使用 (或 )表示前缀(或中缀)标记的数量。可训练参数的数量为 。
前缀层微调 (PreLayer) 是前缀嵌入微调的扩展。我们不是仅为某些特殊标记学习词嵌入(或等效地,嵌入层之后的激活),而是学习每个 Transformer 层之后的激活。从前一层计算的激活被简单地替换为可训练的激活。由此产生的可训练参数数量为 ,其中 是 Transformer 层的数量。
适配器微调 如 Houlsby et al. (2019) 所提议,在自注意力模块(和 MLP 模块)与随后的残差连接之间插入适配器层。适配器层中有两个带有偏置的全连接层,中间有一个非线性。我们将此原始设计称为 Adapter。最近,Lin et al. (2020) 提出了一种更高效的设计,适配器层仅应用于 MLP 模块之后和 LayerNorm 之后。我们称之为 Adapter。这与 Pfeiffer et al. (2021) 提出的另一种设计非常相似,我们称之为 Adapter。我们还包含了另一个称为 AdapterDrop (Rücklé et al., 2020) 的基线,它为了更高的效率丢弃了一些适配器层 (Adapter)。我们尽可能引用先前工作的数字以最大化我们比较的基线数量;它们位于第一列带有星号 (*) 的行中。在所有情况下,我们都有 ,其中 是适配器层的数量, 是可训练 LayerNorms 的数量(例如,在 Adapter 中)。
LoRA 将可训练的秩分解矩阵对与现有权重矩阵并行添加。如第 4.2 节所述,为了简单起见,我们在大多数实验中仅将 LoRA 应用于 和 。可训练参数的数量由秩 和原始权重的形状决定:,其中 是我们应用 LoRA 的权重矩阵的数量。
(注:由于篇幅限制,此处仅翻译了论文的前 6 页内容。如需后续章节的翻译,请继续发送后续内容。)