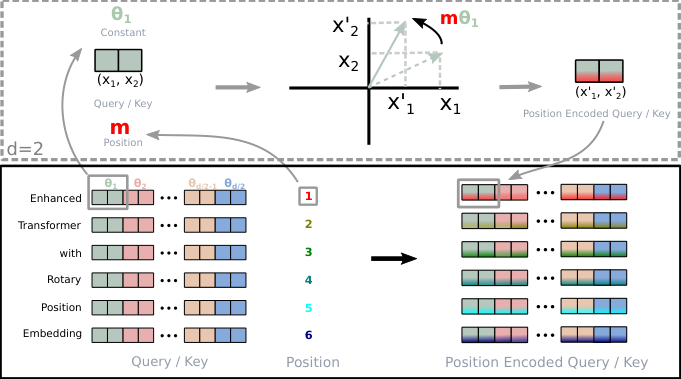
RoFormer:具有旋转位置嵌入的增强型 Transformer
Jianlin Su , Yu Lu , Shengfeng Pan
Zhuiyi Technology Co., Ltd.
Shenzhen
{bojonesu, julianlu, nickpan}@wezhuiyi.com
Ahmed Murtadha , Bo Wen , Yunfeng Liu
Zhuiyi Technology Co., Ltd.
Shenzhen
{mengjiayi, brucewen, glenliu}@wezhuiyi.com
2023年11月9日
摘要
位置编码在 Transformer 架构中已被证明是有效的。它为序列中不同位置的元素之间的依赖关系建模提供了有价值的监督。在本文中,我们首先研究了将位置信息整合到基于 Transformer 的语言模型学习过程中的各种方法。然后,我们提出了一种名为旋转位置嵌入(Rotary Position Embedding, RoPE)的新方法,以有效地利用位置信息。具体而言,所提出的 RoPE 通过旋转矩阵对绝对位置进行编码,同时在自注意力公式中结合了显式的相对位置依赖关系。值得注意的是,RoPE 具备多种有价值的特性,包括序列长度的灵活性、随着相对距离增加而衰减的词元间依赖关系,以及使线性自注意力具备相对位置编码的能力。最后,我们在各种长文本分类基准数据集上评估了这种带有旋转位置嵌入的增强型 Transformer(称为 RoFormer)。实验表明,它始终优于其替代方案。此外,我们还提供了理论分析来解释一些实验结果。RoFormer 已集成到 Huggingface 中:https://huggingface.co/docs/transformers/model_doc/roformer。
关键词 :预训练语言模型 · 位置信息编码 · 预训练 · 自然语言处理
1 引言
词语的顺序对于自然语言理解具有重要价值。基于循环神经网络(RNNs)的模型通过沿时间维度递归计算隐藏状态来编码词元的顺序。基于卷积神经网络(CNNs)的模型(Gehring 等人 [2017])通常被认为是位置无关的,但最近的研究(Islam 等人 [2020])表明,常用的填充(padding)操作可以隐式地学习位置信息。最近,基于 Transformer(Vaswani 等人 [2017])构建的预训练语言模型(PLMs)在各种自然语言处理(NLP)任务中取得了最先进的性能,包括上下文表示学习(Devlin 等人 [2019])、机器翻译(Vaswani 等人 [2017])和语言建模(Radford 等人 [2019])等。与基于 RNN 和 CNN 的模型不同,PLMs 利用自注意力机制来语义地捕获给定语料库的上下文表示。因此,PLMs 在并行化方面比 RNNs 取得了显著改进,并且与 CNNs 相比,提高了对更长词元间关系的建模能力1 ^1 1
1 ^1 1
值得注意的是,当前的 PLMs 自注意力架构已被证明是位置无关的(Yun 等人 [2020])。基于这一主张,人们提出了各种方法将位置信息编码到学习过程中。一方面,通过预定义函数生成的绝对位置编码(Vaswani 等人 [2017])被添加到上下文表示中,同时还有可训练的绝对位置编码(Gehring 等人 [2017], Devlin 等人 [2019], Lan 等人 [2020], Clark 等人 [2020], Radford 等人 [2019], Radford 和 Narasimhan [2018])。另一方面,以往的工作(Parikh 等人 [2016], Shaw 等人 [2018], Huang 等人 [2018], Dai 等人 [2019], Yang 等人 [2019], Raffel 等人 [2020], Ke 等人 [2020], He 等人 [2020], Huang 等人 [2020])侧重于相对位置编码,通常将相对位置信息编码到注意力机制中。除了这些方法外,Liu 等人 [2020] 的作者提出了从神经 ODE(Chen 等人 [2018a])的角度对位置编码的依赖性进行建模,Wang 等人 [2020] 的作者提出了在复数空间中对位置信息进行建模。尽管这些方法有效,但它们通常将位置信息添加到上下文表示中,从而使其不适用于线性自注意力架构。
在本文中,我们引入了一种名为旋转位置嵌入(RoPE)的新方法,以将位置信息利用到 PLMs 的学习过程中。具体而言,RoPE 通过旋转矩阵对绝对位置进行编码,同时在自注意力公式中结合了显式的相对位置依赖关系。请注意,所提出的 RoPE 通过多种有价值的特性优于现有方法,包括序列长度的灵活性、随着相对距离增加而衰减的词元间依赖关系,以及使线性自注意力具备相对位置编码的能力。在各种长文本分类基准数据集上的实验结果表明,带有旋转位置嵌入的增强型 Transformer(即 RoFormer)与基线替代方案相比可以提供更好的性能,从而证明了所提出的 RoPE 的有效性。
简而言之,我们的贡献有以下三个方面:
我们研究了现有的相对位置编码方法,发现它们大多基于将位置编码添加到上下文表示的分解思想。我们引入了一种名为旋转位置嵌入(RoPE)的新方法,将位置信息利用到 PLMs 的学习过程中。其核心思想是通过将上下文表示与旋转矩阵相乘来编码相对位置,并具有清晰的理论解释。
我们研究了 RoPE 的特性,并证明它随着相对距离的增加而衰减,这对于自然语言编码是理想的。我们认为,以往基于相对位置编码的方法与线性自注意力不兼容。
我们在各种长文本基准数据集上评估了所提出的 RoFormer。我们的实验表明,它始终比其替代方案取得更好的性能。一些预训练语言模型的实验可在 GitHub 上获得:https://github.com/ZhuiyiTechnology/roformer。
本文其余部分的组织结构如下。我们在第 2 节中建立了自注意力架构中位置编码问题的形式化描述,并回顾了以往的工作。然后,我们在第 3 节中描述了旋转位置编码(RoPE)并研究了其特性。我们在第 4 节中报告了实验结果。最后,我们在第 5 节中总结本文。
2 背景与相关工作
2.1 预备知识
设 S N = { w i } i = 1 N S_N = \{w_i\}_{i=1}^N S N = { w i } i = 1 N N N N w i w_i w i i i i S N S_N S N E N = { x i } i = 1 N E_N = \{x_i\}_{i=1}^N E N = { x i } i = 1 N x i ∈ R d x_i \in \mathbb{R}^d x i ∈ R d w i w_i w i d d d
q m = f q ( x m , m ) k n = f k ( x n , n ) v n = f v ( x n , n ) , (1) \begin{aligned}
\boldsymbol{q}_m &= f_q(\boldsymbol{x}_m, m) \\
\boldsymbol{k}_n &= f_k(\boldsymbol{x}_n, n) \\
\boldsymbol{v}_n &= f_v(\boldsymbol{x}_n, n),
\end{aligned} \tag{1} q m k n v n = f q ( x m , m ) = f k ( x n , n ) = f v ( x n , n ) , ( 1 ) 其中 q m , k n \boldsymbol{q}_m, \boldsymbol{k}_n q m , k n v n \boldsymbol{v}_n v n f q , f k f_q, f_k f q , f k f v f_v f v m m m n n n
a m , n = exp ( q m ⊺ k n d ) ∑ j = 1 N exp ( q m ⊺ k j d ) o m = ∑ n = 1 N a m , n v n (2) \begin{aligned}
a_{m,n} &= \frac{\exp(\frac{\boldsymbol{q}_m^\intercal \boldsymbol{k}_n}{\sqrt{d}})}{\sum_{j=1}^N \exp(\frac{\boldsymbol{q}_m^\intercal \boldsymbol{k}_j}{\sqrt{d}})} \\
\boldsymbol{o}_m &= \sum_{n=1}^N a_{m,n} \boldsymbol{v}_n
\end{aligned} \tag{2} a m , n o m = ∑ j = 1 N exp ( d q m ⊺ k j ) exp ( d q m ⊺ k n ) = n = 1 ∑ N a m , n v n ( 2 ) 现有的基于 Transformer 的位置编码方法主要集中在选择合适的函数来构成公式 (1)。
2.2 绝对位置嵌入
公式 (1) 的一种典型选择是:
f t : t ∈ { q , k , v } ( x i , i ) : = W t : t ∈ { q , k , v } ( x i + p i ) , (3) f_{t:t \in \{q,k,v\}}(\boldsymbol{x}_i, i) := \boldsymbol{W}_{t:t \in \{q,k,v\}}(\boldsymbol{x}_i + \boldsymbol{p}_i), \tag{3} f t : t ∈ { q , k , v } ( x i , i ) := W t : t ∈ { q , k , v } ( x i + p i ) , ( 3 ) 其中 p i ∈ R d \boldsymbol{p}_i \in \mathbb{R}^d p i ∈ R d x i \boldsymbol{x}_i x i d d d p i ∈ { p t } t = 1 L \boldsymbol{p}_i \in \{\boldsymbol{p}_t\}_{t=1}^L p i ∈ { p t } t = 1 L L L L p i \boldsymbol{p}_i p i
{ p i , 2 t = sin ( k / 10000 2 t / d ) p i , 2 t + 1 = cos ( k / 10000 2 t / d ) (4) \begin{cases}
p_{i,2t} &= \sin(k/10000^{2t/d}) \\
p_{i,2t+1} &= \cos(k/10000^{2t/d})
\end{cases} \tag{4} { p i , 2 t p i , 2 t + 1 = sin ( k /1000 0 2 t / d ) = cos ( k /1000 0 2 t / d ) ( 4 ) 其中 p i , 2 t p_{i,2t} p i , 2 t d d d p i \boldsymbol{p}_i p i 2 t 2t 2 t
2.3 相对位置嵌入
Shaw 等人 [2018] 的作者应用了公式 (1) 的不同设置,如下所示:
f q ( x m ) : = W q x m f k ( x n , n ) : = W k ( x n + p ~ r k ) f v ( x n , n ) : = W v ( x n + p ~ r v ) (5) \begin{aligned}
f_q(\boldsymbol{x}_m) &:= \boldsymbol{W}_q \boldsymbol{x}_m \\
f_k(\boldsymbol{x}_n, n) &:= \boldsymbol{W}_k(\boldsymbol{x}_n + \tilde{\boldsymbol{p}}_r^k) \\
f_v(\boldsymbol{x}_n, n) &:= \boldsymbol{W}_v(\boldsymbol{x}_n + \tilde{\boldsymbol{p}}_r^v)
\end{aligned} \tag{5} f q ( x m ) f k ( x n , n ) f v ( x n , n ) := W q x m := W k ( x n + p ~ r k ) := W v ( x n + p ~ r v ) ( 5 ) 其中 p ~ r k , p ~ r v ∈ R d \tilde{\boldsymbol{p}}_r^k, \tilde{\boldsymbol{p}}_r^v \in \mathbb{R}^d p ~ r k , p ~ r v ∈ R d r = clip ( m − n , r min , r max ) r = \text{clip}(m - n, r_{\min}, r_{\max}) r = clip ( m − n , r m i n , r m a x ) m m m n n n q m ⊺ k n \boldsymbol{q}_m^\intercal \boldsymbol{k}_n q m ⊺ k n
q m ⊺ k n = x m ⊺ W q ⊺ W k x n + x m ⊺ W q ⊺ W k p n + p m ⊺ W q ⊺ W k x n + p m ⊺ W q ⊺ W k p n , (6) \boldsymbol{q}_m^\intercal \boldsymbol{k}_n = \boldsymbol{x}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{x}_n + \boldsymbol{x}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{p}_n + \boldsymbol{p}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{x}_n + \boldsymbol{p}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{p}_n, \tag{6} q m ⊺ k n = x m ⊺ W q ⊺ W k x n + x m ⊺ W q ⊺ W k p n + p m ⊺ W q ⊺ W k x n + p m ⊺ W q ⊺ W k p n , ( 6 ) 其核心思想是用其正弦编码的相对对应项 p ~ m − n \tilde{\boldsymbol{p}}_{m-n} p ~ m − n p n \boldsymbol{p}_n p n u \boldsymbol{u} u v \boldsymbol{v} v p m \boldsymbol{p}_m p m W k \boldsymbol{W}_k W k x n \boldsymbol{x}_n x n p n \boldsymbol{p}_n p n W k \boldsymbol{W}_k W k W k ′ \boldsymbol{W}_k' W k ′
q m ⊺ k n = x m ⊺ W q ⊺ W k x n + x m ⊺ W q ⊺ W k ′ p ~ m − n + u ⊺ W q ⊺ W k x n + v ⊺ W q ⊺ W k ′ p ~ m − n (7) \boldsymbol{q}_m^\intercal \boldsymbol{k}_n = \boldsymbol{x}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{x}_n + \boldsymbol{x}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k' \tilde{\boldsymbol{p}}_{m-n} + \boldsymbol{u}^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{x}_n + \boldsymbol{v}^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k' \tilde{\boldsymbol{p}}_{m-n} \tag{7} q m ⊺ k n = x m ⊺ W q ⊺ W k x n + x m ⊺ W q ⊺ W k ′ p ~ m − n + u ⊺ W q ⊺ W k x n + v ⊺ W q ⊺ W k ′ p ~ m − n ( 7 ) 值得注意的是,通过设置 f v ( x j ) : = W v x j f_v(\boldsymbol{x}_j) := \boldsymbol{W}_v \boldsymbol{x}_j f v ( x j ) := W v x j
q m ⊺ k n = x m ⊺ W q ⊺ W k x n + b i , j (8) \boldsymbol{q}_m^\intercal \boldsymbol{k}_n = \boldsymbol{x}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{x}_n + b_{i,j} \tag{8} q m ⊺ k n = x m ⊺ W q ⊺ W k x n + b i , j ( 8 ) 其中 b i , j b_{i,j} b i , j
q m ⊺ k n = x m ⊺ W q ⊺ W k x n + p m ⊺ U q ⊺ U k p n + b i , j (9) \boldsymbol{q}_m^\intercal \boldsymbol{k}_n = \boldsymbol{x}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{x}_n + \boldsymbol{p}_m^\intercal \boldsymbol{U}_q^\intercal \boldsymbol{U}_k \boldsymbol{p}_n + b_{i,j} \tag{9} q m ⊺ k n = x m ⊺ W q ⊺ W k x n + p m ⊺ U q ⊺ U k p n + b i , j ( 9 ) He 等人 [2020] 的作者认为,两个词元的相对位置只能通过公式 (6) 的中间两项完全建模。因此,绝对位置嵌入 p m \boldsymbol{p}_m p m p n \boldsymbol{p}_n p n p ~ m − n \tilde{\boldsymbol{p}}_{m-n} p ~ m − n
q m ⊺ k n = x m ⊺ W q ⊺ W k x n + x m ⊺ W q ⊺ W k p ~ m − n + p ~ m − n ⊺ W q ⊺ W k x n (10) \boldsymbol{q}_m^\intercal \boldsymbol{k}_n = \boldsymbol{x}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{x}_n + \boldsymbol{x}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \tilde{\boldsymbol{p}}_{m-n} + \tilde{\boldsymbol{p}}_{m-n}^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{W}_k \boldsymbol{x}_n \tag{10} q m ⊺ k n = x m ⊺ W q ⊺ W k x n + x m ⊺ W q ⊺ W k p ~ m − n + p ~ m − n ⊺ W q ⊺ W k x n ( 10 ) 对 Radford 和 Narasimhan [2018] 的四种相对位置嵌入变体的比较表明,类似于公式 (10) 的变体在其他三种中效率最高。总的来说,所有这些方法都试图在公式 (2) 的自注意力设置下,基于公式 (3) 的分解来修改公式 (6),这最初是由 Vaswani 等人 [2017] 提出的。它们通常引入直接将位置信息添加到上下文表示中。与此不同,我们的方法旨在在某些约束下从公式 (1) 推导出相对位置编码。接下来,我们展示通过将相对位置信息与上下文表示的旋转相结合,所推导出的方法更具可解释性。
3 提出的方法
在本节中,我们讨论所提出的旋转位置嵌入(RoPE)。我们首先在第 3.1 节中形式化相对位置编码问题,然后在第 3.2 节中推导 RoPE,并在第 3.3 节中研究其特性。
3.1 形式化
基于 Transformer 的语言建模通常通过自注意力机制利用单个词元的位置信息。正如公式 (2) 中所观察到的,q m ⊺ k n \boldsymbol{q}_m^\intercal \boldsymbol{k}_n q m ⊺ k n q m \boldsymbol{q}_m q m k n \boldsymbol{k}_n k n g g g x m , x n \boldsymbol{x}_m, \boldsymbol{x}_n x m , x n m − n m - n m − n
⟨ f q ( x m , m ) , f k ( x n , n ) ⟩ = g ( x m , x n , m − n ) . (11) \langle f_q(\boldsymbol{x}_m, m), f_k(\boldsymbol{x}_n, n) \rangle = g(\boldsymbol{x}_m, \boldsymbol{x}_n, m - n). \tag{11} ⟨ f q ( x m , m ) , f k ( x n , n )⟩ = g ( x m , x n , m − n ) . ( 11 ) 最终目标是找到一种等效的编码机制来求解函数 f q ( x m , m ) f_q(\boldsymbol{x}_m, m) f q ( x m , m ) f k ( x n , n ) f_k(\boldsymbol{x}_n, n) f k ( x n , n )
3.2 旋转位置嵌入
3.2.1 二维情况
我们从维度 d = 2 d=2 d = 2
f q ( x m , m ) = ( W q x m ) e i m θ f k ( x n , n ) = ( W k x n ) e i n θ g ( x m , x n , m − n ) = Re [ ( W q x m ) ( W k x n ) ∗ e i ( m − n ) θ ] (12) \begin{aligned}
f_q(\boldsymbol{x}_m, m) &= (\boldsymbol{W}_q \boldsymbol{x}_m)e^{im\theta} \\
f_k(\boldsymbol{x}_n, n) &= (\boldsymbol{W}_k \boldsymbol{x}_n)e^{in\theta} \\
g(\boldsymbol{x}_m, \boldsymbol{x}_n, m - n) &= \text{Re}[(\boldsymbol{W}_q \boldsymbol{x}_m)(\boldsymbol{W}_k \boldsymbol{x}_n)^* e^{i(m-n)\theta}]
\end{aligned} \tag{12} f q ( x m , m ) f k ( x n , n ) g ( x m , x n , m − n ) = ( W q x m ) e im θ = ( W k x n ) e in θ = Re [( W q x m ) ( W k x n ) ∗ e i ( m − n ) θ ] ( 12 ) 其中 Re [ ⋅ ] \text{Re}[\cdot] Re [ ⋅ ] ( W k x n ) ∗ (\boldsymbol{W}_k \boldsymbol{x}_n)^* ( W k x n ) ∗ ( W k x n ) (\boldsymbol{W}_k \boldsymbol{x}_n) ( W k x n ) θ ∈ R \theta \in \mathbb{R} θ ∈ R f { q , k } f_{\{q,k\}} f { q , k }
f { q , k } ( x m , m ) = ( cos m θ − sin m θ sin m θ cos m θ ) ( W { q , k } ( 11 ) W { q , k } ( 12 ) W { q , k } ( 21 ) W { q , k } ( 22 ) ) ( x m ( 1 ) x m ( 2 ) ) (13) f_{\{q,k\}}(\boldsymbol{x}_m, m) = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} W_{\{q,k\}}^{(11)} & W_{\{q,k\}}^{(12)} \\ W_{\{q,k\}}^{(21)} & W_{\{q,k\}}^{(22)} \end{pmatrix} \begin{pmatrix} x_m^{(1)} \\ x_m^{(2)} \end{pmatrix} \tag{13} f { q , k } ( x m , m ) = ( cos m θ sin m θ − sin m θ cos m θ ) ( W { q , k } ( 11 ) W { q , k } ( 21 ) W { q , k } ( 12 ) W { q , k } ( 22 ) ) ( x m ( 1 ) x m ( 2 ) ) ( 13 ) 其中 ( x m ( 1 ) , x m ( 2 ) ) (x_m^{(1)}, x_m^{(2)}) ( x m ( 1 ) , x m ( 2 ) ) x m \boldsymbol{x}_m x m g g g
3.2.2 一般形式
为了将我们在二维的结果推广到任何 x i ∈ R d \boldsymbol{x}_i \in \mathbb{R}^d x i ∈ R d d d d d d d d / 2 d/2 d /2 f { q , k } f_{\{q,k\}} f { q , k }
f { q , k } ( x m , m ) = R Θ , m d W { q , k } x m (14) f_{\{q,k\}}(\boldsymbol{x}_m, m) = \boldsymbol{R}_{\Theta,m}^d \boldsymbol{W}_{\{q,k\}} \boldsymbol{x}_m \tag{14} f { q , k } ( x m , m ) = R Θ , m d W { q , k } x m ( 14 ) 其中
R Θ , m d = ( cos m θ 1 − sin m θ 1 0 0 ⋯ 0 0 sin m θ 1 cos m θ 1 0 0 ⋯ 0 0 0 0 cos m θ 2 − sin m θ 2 ⋯ 0 0 0 0 sin m θ 2 cos m θ 2 ⋯ 0 0 ⋮ ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 0 0 0 ⋯ cos m θ d / 2 − sin m θ d / 2 0 0 0 0 ⋯ sin m θ d / 2 cos m θ d / 2 ) (15) \boldsymbol{R}_{\Theta,m}^d = \begin{pmatrix} \cos m\theta_1 & -\sin m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ \sin m\theta_1 & \cos m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ 0 & 0 & \cos m\theta_2 & -\sin m\theta_2 & \cdots & 0 & 0 \\ 0 & 0 & \sin m\theta_2 & \cos m\theta_2 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2} & -\sin m\theta_{d/2} \\ 0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2} & \cos m\theta_{d/2} \end{pmatrix} \tag{15} R Θ , m d = cos m θ 1 sin m θ 1 0 0 ⋮ 0 0 − sin m θ 1 cos m θ 1 0 0 ⋮ 0 0 0 0 cos m θ 2 sin m θ 2 ⋮ 0 0 0 0 − sin m θ 2 cos m θ 2 ⋮ 0 0 ⋯ ⋯ ⋯ ⋯ ⋱ ⋯ ⋯ 0 0 0 0 ⋮ cos m θ d /2 sin m θ d /2 0 0 0 0 ⋮ − sin m θ d /2 cos m θ d /2 ( 15 ) 是带有预定义参数 Θ = { θ i = 10000 − 2 ( i − 1 ) / d , i ∈ [ 1 , 2 , . . . , d / 2 ] } \Theta = \{\theta_i = 10000^{-2(i-1)/d}, i \in [1, 2, ..., d/2]\} Θ = { θ i = 1000 0 − 2 ( i − 1 ) / d , i ∈ [ 1 , 2 , ... , d /2 ]}
q m ⊺ k n = ( R Θ , m d W q x m ) ⊺ ( R Θ , n d W k x n ) = x m ⊺ W q ⊺ R Θ , n − m d W k x n (16) \boldsymbol{q}_m^\intercal \boldsymbol{k}_n = (\boldsymbol{R}_{\Theta,m}^d \boldsymbol{W}_q \boldsymbol{x}_m)^\intercal (\boldsymbol{R}_{\Theta,n}^d \boldsymbol{W}_k \boldsymbol{x}_n) = \boldsymbol{x}_m^\intercal \boldsymbol{W}_q^\intercal \boldsymbol{R}_{\Theta,n-m}^d \boldsymbol{W}_k \boldsymbol{x}_n \tag{16} q m ⊺ k n = ( R Θ , m d W q x m ) ⊺ ( R Θ , n d W k x n ) = x m ⊺ W q ⊺ R Θ , n − m d W k x n ( 16 ) 其中 R Θ , n − m d = ( R Θ , m d ) ⊺ R Θ , n d \boldsymbol{R}_{\Theta,n-m}^d = (\boldsymbol{R}_{\Theta,m}^d)^\intercal \boldsymbol{R}_{\Theta,n}^d R Θ , n − m d = ( R Θ , m d ) ⊺ R Θ , n d R Θ d \boldsymbol{R}_{\Theta}^d R Θ d R Θ d \boldsymbol{R}_{\Theta}^d R Θ d
与以往工作中采用的加性位置嵌入方法(即公式 (3) 到 (10))相比,我们的方法是乘性的。此外,RoPE 通过旋转矩阵乘积自然地整合了相对位置信息,而不是在应用于自注意力时改变加性位置嵌入展开公式中的项。
3.3 RoPE 的特性
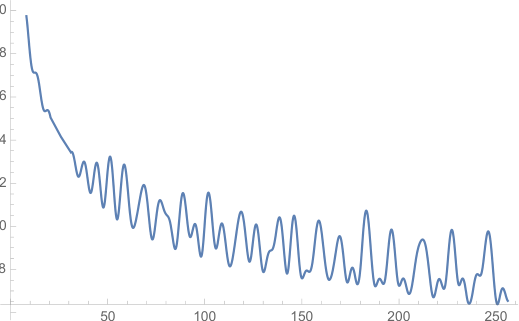
长期衰减 :遵循 Vaswani 等人 [2017],我们设置 θ i = 10000 − 2 i / d \theta_i = 10000^{-2i/d} θ i = 1000 0 − 2 i / d
RoPE 与线性注意力 :自注意力可以以更通用的形式重写。
Attention ( Q , K , V ) m = ∑ n = 1 N sim ( q m , k n ) v n ∑ n = 1 N sim ( q m , k n ) (17) \text{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_m = \frac{\sum_{n=1}^N \text{sim}(\boldsymbol{q}_m, \boldsymbol{k}_n)\boldsymbol{v}_n}{\sum_{n=1}^N \text{sim}(\boldsymbol{q}_m, \boldsymbol{k}_n)} \tag{17} Attention ( Q , K , V ) m = ∑ n = 1 N sim ( q m , k n ) ∑ n = 1 N sim ( q m , k n ) v n ( 17 ) 原始自注意力选择 sim ( q m , k n ) = exp ( q m ⊺ k n / d ) \text{sim}(\boldsymbol{q}_m, \boldsymbol{k}_n) = \exp(\boldsymbol{q}_m^\intercal \boldsymbol{k}_n / \sqrt{d}) sim ( q m , k n ) = exp ( q m ⊺ k n / d ) O ( N 2 ) O(N^2) O ( N 2 )
Attention ( Q , K , V ) m = ∑ n = 1 N ϕ ( q m ) ⊺ φ ( k n ) v n ∑ n = 1 N ϕ ( q m ) ⊺ φ ( k n ) (18) \text{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_m = \frac{\sum_{n=1}^N \phi(\boldsymbol{q}_m)^\intercal \varphi(\boldsymbol{k}_n)\boldsymbol{v}_n}{\sum_{n=1}^N \phi(\boldsymbol{q}_m)^\intercal \varphi(\boldsymbol{k}_n)} \tag{18} Attention ( Q , K , V ) m = ∑ n = 1 N ϕ ( q m ) ⊺ φ ( k n ) ∑ n = 1 N ϕ ( q m ) ⊺ φ ( k n ) v n ( 18 ) 其中 ϕ ( ⋅ ) , φ ( ⋅ ) \phi(\cdot), \varphi(\cdot) ϕ ( ⋅ ) , φ ( ⋅ ) ϕ ( x ) = φ ( x ) = elu ( x ) + 1 \phi(\boldsymbol{x}) = \varphi(\boldsymbol{x}) = \text{elu}(\boldsymbol{x}) + 1 ϕ ( x ) = φ ( x ) = elu ( x ) + 1 ϕ ( q i ) = softmax ( q i ) \phi(\boldsymbol{q}_i) = \text{softmax}(\boldsymbol{q}_i) ϕ ( q i ) = softmax ( q i ) φ ( k j ) = exp ( k j ) \varphi(\boldsymbol{k}_j) = \exp(\boldsymbol{k}_j) φ ( k j ) = exp ( k j )
Attention ( Q , K , V ) m = ∑ n = 1 N ( R Θ , m d ϕ ( q m ) ) ⊺ ( R Θ , n d φ ( k n ) ) v n ∑ n = 1 N ϕ ( q m ) ⊺ φ ( k n ) (19) \text{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_m = \frac{\sum_{n=1}^N (\boldsymbol{R}_{\Theta,m}^d \phi(\boldsymbol{q}_m))^\intercal (\boldsymbol{R}_{\Theta,n}^d \varphi(\boldsymbol{k}_n))\boldsymbol{v}_n}{\sum_{n=1}^N \phi(\boldsymbol{q}_m)^\intercal \varphi(\boldsymbol{k}_n)} \tag{19} Attention ( Q , K , V ) m = ∑ n = 1 N ϕ ( q m ) ⊺ φ ( k n ) ∑ n = 1 N ( R Θ , m d ϕ ( q m ) ) ⊺ ( R Θ , n d φ ( k n )) v n ( 19 ) 值得注意的是,我们保持分母不变以避免除以零的风险,并且分子中的求和可能包含负项。虽然公式 (19) 中每个值 v n \boldsymbol{v}_n v n
3.4 理论解释
3.4.1 二维下 RoPE 的推导
在 d = 2 d=2 d = 2 x q , x k \boldsymbol{x}_q, \boldsymbol{x}_k x q , x k m m m n n n
q m = f q ( x q , m ) , k n = f k ( x k , n ) , (20) \begin{aligned}
\boldsymbol{q}_m &= f_q(\boldsymbol{x}_q, m), \\
\boldsymbol{k}_n &= f_k(\boldsymbol{x}_k, n),
\end{aligned} \tag{20} q m k n = f q ( x q , m ) , = f k ( x k , n ) , ( 20 ) 其中 q m \boldsymbol{q}_m q m k n \boldsymbol{k}_n k n g g g f { q , k } f_{\{q,k\}} f { q , k }
q m ⊺ k n = ⟨ f q ( x m , m ) , f k ( x n , n ) ⟩ = g ( x m , x n , n − m ) , (21) \boldsymbol{q}_m^\intercal \boldsymbol{k}_n = \langle f_q(\boldsymbol{x}_m, m), f_k(\boldsymbol{x}_n, n) \rangle = g(\boldsymbol{x}_m, \boldsymbol{x}_n, n - m), \tag{21} q m ⊺ k n = ⟨ f q ( x m , m ) , f k ( x n , n )⟩ = g ( x m , x n , n − m ) , ( 21 ) 我们进一步要求满足以下初始条件:
q = f q ( x q , 0 ) , k = f k ( x k , 0 ) , (22) \begin{aligned}
\boldsymbol{q} &= f_q(\boldsymbol{x}_q, 0), \\
\boldsymbol{k} &= f_k(\boldsymbol{x}_k, 0),
\end{aligned} \tag{22} q k = f q ( x q , 0 ) , = f k ( x k , 0 ) , ( 22 ) 这可以被解读为编码了空位置信息的向量。给定这些设置,我们尝试寻找 f q , f k f_q, f_k f q , f k
f q ( x q , m ) = R q ( x q , m ) e i Θ q ( x q , m ) , f k ( x k , n ) = R k ( x k , n ) e i Θ k ( x k , n ) , g ( x q , x k , n − m ) = R g ( x q , x k , n − m ) e i Θ g ( x q , x k , n − m ) , (23) \begin{aligned}
f_q(\boldsymbol{x}_q, m) &= R_q(\boldsymbol{x}_q, m)e^{i\Theta_q(\boldsymbol{x}_q,m)}, \\
f_k(\boldsymbol{x}_k, n) &= R_k(\boldsymbol{x}_k, n)e^{i\Theta_k(\boldsymbol{x}_k,n)}, \\
g(\boldsymbol{x}_q, \boldsymbol{x}_k, n - m) &= R_g(\boldsymbol{x}_q, \boldsymbol{x}_k, n - m)e^{i\Theta_g(\boldsymbol{x}_q,\boldsymbol{x}_k,n-m)},
\end{aligned} \tag{23} f q ( x q , m ) f k ( x k , n ) g ( x q , x k , n − m ) = R q ( x q , m ) e i Θ q ( x q , m ) , = R k ( x k , n ) e i Θ k ( x k , n ) , = R g ( x q , x k , n − m ) e i Θ g ( x q , x k , n − m ) , ( 23 ) 其中 R f , R g R_f, R_g R f , R g Θ f , Θ g \Theta_f, \Theta_g Θ f , Θ g f { q , k } f_{\{q,k\}} f { q , k } g g g
R q ( x q , m ) R k ( x k , n ) = R g ( x q , x k , n − m ) , Θ k ( x k , n ) − Θ q ( x q , m ) = Θ g ( x q , x k , n − m ) , (24) \begin{aligned}
R_q(\boldsymbol{x}_q, m)R_k(\boldsymbol{x}_k, n) &= R_g(\boldsymbol{x}_q, \boldsymbol{x}_k, n - m), \\
\Theta_k(\boldsymbol{x}_k, n) - \Theta_q(\boldsymbol{x}_q, m) &= \Theta_g(\boldsymbol{x}_q, \boldsymbol{x}_k, n - m),
\end{aligned} \tag{24} R q ( x q , m ) R k ( x k , n ) Θ k ( x k , n ) − Θ q ( x q , m ) = R g ( x q , x k , n − m ) , = Θ g ( x q , x k , n − m ) , ( 24 ) 以及相应的初始条件:
q = ∥ q ∥ e i θ q = R q ( x q , 0 ) e i Θ q ( x q , 0 ) , k = ∥ k ∥ e i θ k = R k ( x k , 0 ) e i Θ k ( x k , 0 ) , (25) \begin{aligned}
\boldsymbol{q} &= \|\boldsymbol{q}\|e^{i\theta_q} = R_q(\boldsymbol{x}_q, 0)e^{i\Theta_q(\boldsymbol{x}_q,0)}, \\
\boldsymbol{k} &= \|\boldsymbol{k}\|e^{i\theta_k} = R_k(\boldsymbol{x}_k, 0)e^{i\Theta_k(\boldsymbol{x}_k,0)},
\end{aligned} \tag{25} q k = ∥ q ∥ e i θ q = R q ( x q , 0 ) e i Θ q ( x q , 0 ) , = ∥ k ∥ e i θ k = R k ( x k , 0 ) e i Θ k ( x k , 0 ) , ( 25 ) 其中 ∥ q ∥ , ∥ k ∥ \|\boldsymbol{q}\|, \|\boldsymbol{k}\| ∥ q ∥ , ∥ k ∥ θ q , θ k \theta_q, \theta_k θ q , θ k q \boldsymbol{q} q k \boldsymbol{k} k
接下来,我们在公式 (24) 中设置 m = n m = n m = n
\begin{aligned}
R_q(\boldsymbol{x}_q, m)R_k(\boldsymbol{x}_k, m) &= R_g(\boldsymbol{x}_q, \boldsymbol{x}_k, 0) = R_q(\boldsymbol{x}_q, 0)R_k(\boldsymbol{x}_k, 0) = \|\boldsymbol{q}\|\|\boldsymbol{k}\|, \tag{26a} \\
\Theta_k(\boldsymbol{x}_k, m) - \Theta_q(\boldsymbol{x}_q, m) &= \Theta_g(\boldsymbol{x}_q, \boldsymbol{x}_k, 0) = \Theta_k(\boldsymbol{x}_k, 0) - \Theta_q(\boldsymbol{x}_q, 0) = \theta_k - \theta_q. \tag{26b}
\end{aligned}
一方面,从公式 (26a) 可以直接形成 R f R_f R f
R q ( x q , m ) = R q ( x q , 0 ) = ∥ q ∥ R k ( x k , n ) = R k ( x k , 0 ) = ∥ k ∥ R g ( x q , x k , n − m ) = R g ( x q , x k , 0 ) = ∥ q ∥ ∥ k ∥ (27) \begin{aligned}
R_q(\boldsymbol{x}_q, m) &= R_q(\boldsymbol{x}_q, 0) = \|\boldsymbol{q}\| \\
R_k(\boldsymbol{x}_k, n) &= R_k(\boldsymbol{x}_k, 0) = \|\boldsymbol{k}\| \\
R_g(\boldsymbol{x}_q, \boldsymbol{x}_k, n - m) &= R_g(\boldsymbol{x}_q, \boldsymbol{x}_k, 0) = \|\boldsymbol{q}\|\|\boldsymbol{k}\|
\end{aligned} \tag{27} R q ( x q , m ) R k ( x k , n ) R g ( x q , x k , n − m ) = R q ( x q , 0 ) = ∥ q ∥ = R k ( x k , 0 ) = ∥ k ∥ = R g ( x q , x k , 0 ) = ∥ q ∥∥ k ∥ ( 27 ) 这解释了径向函数 R q , R k R_q, R_k R q , R k R g R_g R g Θ q ( x q , m ) − θ q = Θ k ( x k , m ) − θ k \Theta_q(\boldsymbol{x}_q, m) - \theta_q = \Theta_k(\boldsymbol{x}_k, m) - \theta_k Θ q ( x q , m ) − θ q = Θ k ( x k , m ) − θ k Θ f : = Θ q = Θ k \Theta_f := \Theta_q = \Theta_k Θ f := Θ q = Θ k Θ f ( x { q , k } , m ) − θ { q , k } \Theta_f(\boldsymbol{x}_{\{q,k\}}, m) - \theta_{\{q,k\}} Θ f ( x { q , k } , m ) − θ { q , k } m m m x { q , k } \boldsymbol{x}_{\{q,k\}} x { q , k } ϕ ( m ) \phi(m) ϕ ( m )
Θ f ( x { q , k } , m ) = ϕ ( m ) + θ { q , k } , (28) \Theta_f(\boldsymbol{x}_{\{q,k\}}, m) = \phi(m) + \theta_{\{q,k\}}, \tag{28} Θ f ( x { q , k } , m ) = ϕ ( m ) + θ { q , k } , ( 28 ) 此外,通过将 n = m + 1 n = m + 1 n = m + 1
ϕ ( m + 1 ) − ϕ ( m ) = Θ g ( x q , x k , 1 ) + θ q − θ k , (29) \phi(m + 1) - \phi(m) = \Theta_g(\boldsymbol{x}_q, \boldsymbol{x}_k, 1) + \theta_q - \theta_k, \tag{29} ϕ ( m + 1 ) − ϕ ( m ) = Θ g ( x q , x k , 1 ) + θ q − θ k , ( 29 ) 由于 RHS 是一个与 m m m ϕ ( m ) \phi(m) ϕ ( m )
ϕ ( m ) = m θ + γ , (30) \phi(m) = m\theta + \gamma, \tag{30} ϕ ( m ) = m θ + γ , ( 30 ) 其中 θ , γ ∈ R \theta, \gamma \in \mathbb{R} θ , γ ∈ R θ \theta θ
f q ( x q , m ) = ∥ q ∥ e i θ q + m θ + γ = q e i ( m θ + γ ) , f k ( x k , n ) = ∥ k ∥ e i θ k + n θ + γ = k e i ( n θ + γ ) . (31) \begin{aligned}
f_q(\boldsymbol{x}_q, m) &= \|\boldsymbol{q}\|e^{i\theta_q+m\theta+\gamma} = \boldsymbol{q}e^{i(m\theta+\gamma)}, \\
f_k(\boldsymbol{x}_k, n) &= \|\boldsymbol{k}\|e^{i\theta_k+n\theta+\gamma} = \boldsymbol{k}e^{i(n\theta+\gamma)}.
\end{aligned} \tag{31} f q ( x q , m ) f k ( x k , n ) = ∥ q ∥ e i θ q + m θ + γ = q e i ( m θ + γ ) , = ∥ k ∥ e i θ k + n θ + γ = k e i ( n θ + γ ) . ( 31 ) 注意我们不对公式 (22) 的 f q f_q f q f k f_k f k f q ( x m , 0 ) f_q(\boldsymbol{x}_m, 0) f q ( x m , 0 ) f k ( x n , 0 ) f_k(\boldsymbol{x}_n, 0) f k ( x n , 0 )
q = f q ( x m , 0 ) = W q x n , k = f k ( x n , 0 ) = W k x n . (32) \begin{aligned}
\boldsymbol{q} &= f_q(\boldsymbol{x}_m, 0) = \boldsymbol{W}_q \boldsymbol{x}_n, \\
\boldsymbol{k} &= f_k(\boldsymbol{x}_n, 0) = \boldsymbol{W}_k\boldsymbol{x}_n.
\end{aligned} \tag{32} q k = f q ( x m , 0 ) = W q x n , = f k ( x n , 0 ) = W k x n . ( 32 ) 然后,我们只需在最终解的公式 (31) 中设置 γ = 0 \gamma = 0 γ = 0
f q ( x m , m ) = ( W q x m ) e i m θ , f k ( x n , n ) = ( W k x n ) e i n θ . (33) \begin{aligned}
f_q(\boldsymbol{x}_m, m) &= (\boldsymbol{W}_q \boldsymbol{x}_m)e^{im\theta}, \\
f_k(\boldsymbol{x}_n, n) &= (\boldsymbol{W}_k \boldsymbol{x}_n)e^{in\theta}.
\end{aligned} \tag{33} f q ( x m , m ) f k ( x n , n ) = ( W q x m ) e im θ , = ( W k x n ) e in θ . ( 33 ) 3.4.2 旋转矩阵乘法的计算高效实现
利用公式 (15) 中 R Θ , m d \boldsymbol{R}_{\Theta,m}^d R Θ , m d R Θ d \boldsymbol{R}_{\Theta}^d R Θ d x ∈ R d \boldsymbol{x} \in \mathbb{R}^d x ∈ R d
R Θ , m d x = ( x 1 x 2 x 3 x 4 ⋮ x d − 1 x d ) ⊗ ( cos m θ 1 cos m θ 1 cos m θ 2 cos m θ 2 ⋮ cos m θ d / 2 cos m θ d / 2 ) + ( − x 2 x 1 − x 4 x 3 ⋮ − x d x d − 1 ) ⊗ ( sin m θ 1 sin m θ 1 sin m θ 2 sin m θ 2 ⋮ sin m θ d / 2 sin m θ d / 2 ) (34) \boldsymbol{R}_{\Theta,m}^d \boldsymbol{x} = \begin{pmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \\ \vdots \\ x_{d-1} \\ x_d \end{pmatrix} \otimes \begin{pmatrix} \cos m\theta_1 \\ \cos m\theta_1 \\ \cos m\theta_2 \\ \cos m\theta_2 \\ \vdots \\ \cos m\theta_{d/2} \\ \cos m\theta_{d/2} \end{pmatrix} + \begin{pmatrix} -x_2 \\ x_1 \\ -x_4 \\ x_3 \\ \vdots \\ -x_d \\ x_{d-1} \end{pmatrix} \otimes \begin{pmatrix} \sin m\theta_1 \\ \sin m\theta_1 \\ \sin m\theta_2 \\ \sin m\theta_2 \\ \vdots \\ \sin m\theta_{d/2} \\ \sin m\theta_{d/2} \end{pmatrix} \tag{34} R Θ , m d x = x 1 x 2 x 3 x 4 ⋮ x d − 1 x d ⊗ cos m θ 1 cos m θ 1 cos m θ 2 cos m θ 2 ⋮ cos m θ d /2 cos m θ d /2 + − x 2 x 1 − x 4 x 3 ⋮ − x d x d − 1 ⊗ sin m θ 1 sin m θ 1 sin m θ 2 sin m θ 2 ⋮ sin m θ d /2 sin m θ d /2 ( 34 )
3.4.3 RoPE 的长期衰减
我们可以将向量 q = W q x m \boldsymbol{q} = \boldsymbol{W}_q \boldsymbol{x}_m q = W q x m k = W k x n \boldsymbol{k} = \boldsymbol{W}_k \boldsymbol{x}_n k = W k x n
( R Θ , m d W q x m ) ⊺ ( R Θ , n d W k x n ) = Re [ ∑ i = 0 d / 2 − 1 q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ e i ( m − n ) θ i ] (35) (\boldsymbol{R}_{\Theta,m}^d \boldsymbol{W}_q \boldsymbol{x}_m)^\intercal (\boldsymbol{R}_{\Theta,n}^d \boldsymbol{W}_k \boldsymbol{x}_n) = \text{Re} \left[ \sum_{i=0}^{d/2-1} \boldsymbol{q}_{[2i:2i+1]} \boldsymbol{k}_{[2i:2i+1]}^* e^{i(m-n)\theta_i} \right] \tag{35} ( R Θ , m d W q x m ) ⊺ ( R Θ , n d W k x n ) = Re i = 0 ∑ d /2 − 1 q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ e i ( m − n ) θ i ( 35 ) 其中 q [ 2 i : 2 i + 1 ] \boldsymbol{q}_{[2i:2i+1]} q [ 2 i : 2 i + 1 ] q \boldsymbol{q} q 2 i 2i 2 i 2 i + 1 2i+1 2 i + 1 h i = q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ h_i = \boldsymbol{q}_{[2i:2i+1]} \boldsymbol{k}_{[2i:2i+1]}^* h i = q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ S j = ∑ i = 0 j − 1 e i ( m − n ) θ i S_j = \sum_{i=0}^{j-1} e^{i(m-n)\theta_i} S j = ∑ i = 0 j − 1 e i ( m − n ) θ i h d / 2 = 0 h_{d/2} = 0 h d /2 = 0 S 0 = 0 S_0 = 0 S 0 = 0
∑ i = 0 d / 2 − 1 q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ e i ( m − n ) θ i = ∑ i = 0 d / 2 − 1 h i ( S i + 1 − S i ) = − ∑ i = 0 d / 2 − 1 S i + 1 ( h i + 1 − h i ) . (36) \sum_{i=0}^{d/2-1} \boldsymbol{q}_{[2i:2i+1]} \boldsymbol{k}_{[2i:2i+1]}^* e^{i(m-n)\theta_i} = \sum_{i=0}^{d/2-1} h_i(S_{i+1} - S_i) = -\sum_{i=0}^{d/2-1} S_{i+1}(h_{i+1} - h_i). \tag{36} i = 0 ∑ d /2 − 1 q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ e i ( m − n ) θ i = i = 0 ∑ d /2 − 1 h i ( S i + 1 − S i ) = − i = 0 ∑ d /2 − 1 S i + 1 ( h i + 1 − h i ) . ( 36 ) 因此,
∣ ∑ i = 0 d / 2 − 1 q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ e i ( m − n ) θ i ∣ = ∣ ∑ i = 0 d / 2 − 1 S i + 1 ( h i + 1 − h i ) ∣ ≤ ∑ i = 0 d / 2 − 1 ∣ S i + 1 ∣ ∣ ( h i + 1 − h i ) ∣ ≤ ( max i ∣ h i + 1 − h i ∣ ) ∑ i = 0 d / 2 − 1 ∣ S i + 1 ∣ (37) \begin{aligned}
\left| \sum_{i=0}^{d/2-1} \boldsymbol{q}_{[2i:2i+1]} \boldsymbol{k}_{[2i:2i+1]}^* e^{i(m-n)\theta_i} \right| &= \left| \sum_{i=0}^{d/2-1} S_{i+1}(h_{i+1} - h_i) \right| \\
&\leq \sum_{i=0}^{d/2-1} |S_{i+1}||(h_{i+1} - h_i)| \\
&\leq \left( \max_i |h_{i+1} - h_i| \right) \sum_{i=0}^{d/2-1} |S_{i+1}|
\end{aligned} \tag{37} i = 0 ∑ d /2 − 1 q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ e i ( m − n ) θ i = i = 0 ∑ d /2 − 1 S i + 1 ( h i + 1 − h i ) ≤ i = 0 ∑ d /2 − 1 ∣ S i + 1 ∣∣ ( h i + 1 − h i ) ∣ ≤ ( i max ∣ h i + 1 − h i ∣ ) i = 0 ∑ d /2 − 1 ∣ S i + 1 ∣ ( 37 ) 注意,通过设置 θ i = 10000 − 2 i / d \theta_i = 10000^{-2i/d} θ i = 1000 0 − 2 i / d 1 d / 2 ∑ i = 1 d / 2 ∣ S i ∣ \frac{1}{d/2} \sum_{i=1}^{d/2} |S_i| d /2 1 ∑ i = 1 d /2 ∣ S i ∣ m − n m-n m − n
4 实验与评估
我们按如下方式评估所提出的 RoFormer 在各种 NLP 任务上的表现。我们首先在机器翻译任务(第 4.1 节)中验证所提出方案的性能。然后,我们在预训练阶段(第 4.2 节)将我们的 RoPE 实现与 BERT(Devlin 等人 [2019])进行比较。基于预训练模型,我们在第 4.3 节中进一步对来自 GLUE 基准(Singh 等人 [2018])的不同下游任务进行了评估。此外,我们在第 4.4 节中使用所提出的 RoPE 与 PerFormer(Choromanski 等人 [2020])的线性注意力进行了实验。最后,第 4.5 节包含了针对中文数据的额外测试。所有实验均在配备 4 x V100 GPU 的两台云服务器上运行。
4.1 机器翻译
我们首先展示 RoFormer 在序列到序列语言翻译任务上的性能。
4.1.1 实验设置
我们选择标准的 WMT 2014 英德数据集(Bojar 等人 [2014]),该数据集包含约 450 万个句子对。我们将其与基于 Transformer 的基线替代方案(Vaswani 等人 [2017])进行比较。
4.1.2 实现细节
我们对基线模型(Vaswani 等人 [2017])的自注意力层进行了一些修改,以使 RoPE 能够融入其学习过程。我们复制了英德翻译的设置,使用基于联合源和目标字节对编码(BPE)(Sennrich 等人 [2015])的 37k 词汇表。在评估过程中,通过平均最后 5 个检查点获得单个模型。结果使用束搜索(beam search),束大小为 4,长度惩罚为 0.6。我们在 fairseq 工具包(MIT 许可证)(Ott 等人 [2019])中实现了该实验。我们的模型使用 Adam 优化器进行优化,其中 β 1 = 0.9 , β 2 = 0.98 \beta_1 = 0.9, \beta_2 = 0.98 β 1 = 0.9 , β 2 = 0.98 1 e − 7 1e-7 1 e − 7 5 e − 4 5e-4 5 e − 4
4.1.3 结果
我们在相同的设置下训练基线模型和我们的 RoFormer,并将结果报告在表 (1) 中。可以看出,与基线 Transformer 相比,我们的模型提供了更好的 BLEU 分数。
模型 BLEU Transformer-base (Vaswani 等人 [2017]) 27.3 RoFormer 27.5
表 1:所提出的 RoFormer 在 WMT 2014 英德翻译任务上与基线替代方案(Vaswani 等人 [2017])相比提供了更好的 BLEU 分数。
4.2 预训练语言建模
第二个实验旨在验证我们的提议在学习上下文表示方面的性能。为此,我们在预训练步骤中用我们的 RoPE 替换了 BERT 原有的正弦位置编码。
4.2.1 实验设置
我们使用来自 Huggingface Datasets 库(Apache 许可证 2.0)的 BookCorpus(Zhu 等人 [2015])和 Wikipedia Corpus(Foundation [2021])进行预训练。语料库进一步以 8:2 的比例划分为训练集和验证集。我们使用训练过程中的掩码语言建模(MLM)损失值作为评估指标。我们采用著名的 BERT(Devlin 等人 [2019])作为我们的基线模型。注意,我们在实验中使用了 bert-base-uncased。
4.2.2 实现细节
对于 RoFormer,我们用我们提出的 RoPE 替换了基线模型自注意力块中的正弦位置编码,并根据公式 (16) 实现自注意力。我们以 64 的批大小和 512 的最大序列长度训练 BERT 和 RoFormer 100k 步。使用 AdamW(Loshchilov 和 Hutter [2017])作为优化器,学习率为 1e-5。
4.2.3 结果
预训练期间的 MLM 损失如图 (3) 左图所示。与原始 BERT 相比,RoFormer 收敛更快。
4.3 在 GLUE 任务上的微调
与之前的实验一致,我们在各种 GLUE 任务上微调了我们预训练的 RoFormer 的权重,以评估其在下游 NLP 任务上的泛化能力。
4.3.1 实验设置
我们查看了来自 GLUE 的几个数据集,即 MRPC(Dolan 和 Brockett [2005])、SST-2(Socher 等人 [2013])、QNLI(Rajpurkar 等人 [2016])、STS-B(Al-Natsheh [2017])、QQP(Chen 等人 [2018b])和 MNLI(Williams 等人 [2018])。我们使用 MRPC 和 QQP 数据集的 F1 分数、STS-B 的斯皮尔曼相关系数以及其余任务的准确率作为评估指标。
4.3.2 实现细节
我们使用 Huggingface Transformers 库(Apache 许可证 2.0)(Wolf 等人 [2020])对上述每个下游任务进行 3 个 epoch 的微调,最大序列长度为 512,批大小为 32,学习率为 2, 3, 4, 5e-5。遵循 Devlin 等人 [2019],我们报告验证集上的最佳平均结果。
模型 MRPC SST-2 QNLI STS-B QQP MNLI(m/mm) BERT (Devlin 等人 [2019]) 88.9 93.5 90.5 85.8 71.2 84.6/83.4 RoFormer 89.5 90.7 88.0 87.0 86.4 80.2/79.8
表 2:通过在下游 GLUE 任务上微调比较 RoFormer 和 BERT。
4.3.3 结果
微调任务的评估结果报告在表 (2) 中。可以看出,RoFormer 在六个数据集中的三个上显著优于 BERT,且改进相当可观。
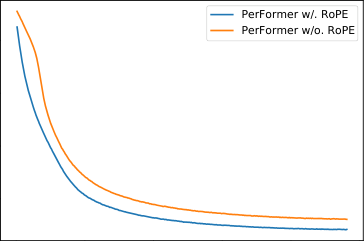
4.4 带有 RoPE 的 Performer
Performer(Choromanski 等人 [2020])引入了一种替代的注意力机制——线性注意力,旨在避免随输入序列长度缩放的二次计算成本。如第 3.3 节所述,所提出的 RoPE 可以轻松地在 PerFormer 模型中实现,以实现相对位置编码,同时保持其在线性自注意力中的缩放复杂度。我们通过语言建模的预训练任务展示了其性能。
4.4.1 实现细节
我们在 Enwik8 数据集(Mahoney [2006])上进行了测试,该数据集来自包含标记、特殊字符和除英语外其他语言文本的英语维基百科。我们将 RoPE 整合到具有 768 维度和 12 个头的 12 层基于字符的 PerFormer 中2 ^2 2
4.4.2 结果
如图 (3) 右图所示,在相同的训练步数下,将 RoPE 替换到 Performer 中会导致更快的收敛和更低的损失。这些改进,加上线性复杂度,使 Performer 更具吸引力。
4.5 中文数据评估
除了英语数据的实验外,我们还展示了中文数据的额外结果。为了验证 RoFormer 在长文本上的性能,我们对长度超过 512 个字符的长文档进行了实验。
4.5.1 实现
在这些实验中,我们通过用我们提出的 RoPE 替换绝对位置嵌入,对 WoBERT(Su [2020])进行了一些修改。作为与其他中文预训练 Transformer 模型(即 BERT(Devlin 等人 [2019])、WoBERT(Su [2020])和 NEZHA(Wei 等人 [2019]))的交叉比较,我们将它们的标记化级别和位置嵌入信息列在表 (3) 中。
模型 BERT (Devlin 等人 [2019]) WoBERT (Su [2020]) NEZHA (Wei 等人 [2019]) RoFormer 标记化级别 char word char word 位置嵌入 abs. abs. rel. RoPE
表 3:我们的 RoFormer 与其他中文预训练模型的交叉比较。'abs' 和 'rel' 分别标注绝对位置嵌入和相对位置嵌入。
4.5.2 预训练
我们在从中文维基百科、新闻和论坛收集的约 34GB 数据上预训练 RoFormer。预训练分多个阶段进行,改变批大小和最大输入序列长度,以适应各种场景。如表 (4) 所示,RoFormer 的准确率随着序列长度上限的增加而提高,这证明了 RoFormer 处理长文本的能力。我们声称这是所提出的 RoPE 具有出色泛化能力的属性。
阶段 最大序列长度 批大小 训练步数 损失 准确率 1 512 256 200k 1.73 65.0% 2 1536 256 12.5k 1.61 66.8% 3 256 256 120k 1.75 64.6% 4 128 512 80k 1.83 63.4% 5 1536 256 10k 1.58 67.4% 6 512 512 30k 1.66 66.2%
表 4:RoFormer 在中文数据集上的预训练策略。训练过程分为多个连续阶段。在每个阶段,我们使用最大序列长度和批大小的特定组合来训练模型。
4.5.3 下游任务与数据集
我们选择中文 AI 与法律 2019 相似案例匹配(CAIL2019-SCM)(Xiao 等人 [2019])数据集来说明 RoFormer 处理长文本的能力,即语义文本匹配。CAIL2019-SCM 包含 8964 个由中华人民共和国最高人民法院发布的案例三元组。输入三元组,记为 (A, B 和 C),是三个案例的事实描述。任务是在预定义的相似度度量下预测 (A, B) 对是否比 (A, C) 对更接近。注意,由于文档长度(即大多超过 512 个字符),现有方法大多无法在 CAIL2019-SCM 数据集上表现显著。我们基于著名的 6:2:2 比例划分训练集、验证集和测试集。
2 ^2 2 https://github.com/lucidrains/performer-pytorch 的代码(MIT 许可证)。
4.5.4 结果
我们将预训练的 RoFormer 模型应用于具有不同输入长度的 CAIL2019-SCM。该模型与在相同预训练数据上预训练的 BERT 和 WoBERT 模型进行了比较,如表 (5) 所示。在短文本截断(即 512)下,RoFormer 的结果与 WoBERT 相当,并且略好于 BERT 实现。然而,当将最大输入文本长度增加到 1024 时,RoFormer 以 1.5% 的绝对改进优于 WoBERT。
模型 验证集 测试集 BERT-512 64.13% 67.77% WoBERT-512 64.07% 68.10% RoFormer-512 64.13% 68.29% RoFormer-1024 66.07% 69.79%
表 5:CAIL2019-SCM 任务上的实验结果。第一列中的数字表示最大截断序列长度。结果以百分比准确率表示。
4.5.5 工作局限性
尽管我们提供了理论基础以及有希望的实验论证,但我们的方法受到以下事实的限制:
尽管我们在数学上将二维子空间下的相对位置关系格式化为旋转,但缺乏关于为什么它比结合其他位置编码策略的基线模型收敛更快的详尽解释。
尽管我们已经证明了我们的模型对于词元间积具有良好的长期衰减特性(第 3.3 节),这与现有的位置编码机制相似,但我们的模型在长文本上表现出优于同类模型的性能,我们尚未提出一个忠实的解释。
我们提出的 RoFormer 建立在基于 Transformer 的基础设施之上,这需要硬件资源进行预训练。
5 结论
在这项工作中,我们提出了一种新的位置嵌入方法,该方法在自注意力中结合了显式的相对位置依赖关系,以增强 Transformer 架构的性能。我们的理论分析表明,相对位置可以使用自注意力中的向量积自然地形式化,绝对位置信息通过旋转矩阵进行编码。此外,我们在数学上说明了所提出的方法应用于 Transformer 时的优势特性。最后,在英语和中文基准数据集上的实验表明,我们的方法促进了预训练中的更快收敛。实验结果还表明,我们提出的 RoFormer 可以在长文本任务上实现更好的性能。
参考文献
[此处省略参考文献列表,格式同原论文]