Switch Transformers:通过简单高效的稀疏性扩展至万亿参数模型
William Fedus* liamfedus@google.com
Barret Zoph* barretzoph@google.com
Noam Shazeer noam@google.com
Google, Mountain View, CA 94043, USA
编辑:Alexander Clark
摘要
在深度学习中,模型通常对所有输入重复使用相同的参数。混合专家(Mixture of Experts, MoE)模型打破了这一惯例,而是为每个输入示例选择不同的参数。其结果是一个稀疏激活的模型——拥有惊人数量的参数——但计算成本保持不变。然而,尽管 MoE 取得了一些显著的成功,但其广泛应用一直受到复杂性、通信成本和训练不稳定性的阻碍。我们通过引入 Switch Transformer 解决了这些问题。我们简化了 MoE 路由算法,并设计了直观的改进模型,降低了通信和计算成本。我们提出的训练技术减轻了不稳定性,并且我们首次展示了大型稀疏模型可以在较低精度(bfloat16)格式下进行训练。我们基于 T5-Base 和 T5-Large(Raffel 等人,2019)设计了模型,在相同的计算资源下,预训练速度提高了 7 倍。这些改进扩展到了多语言设置,我们在所有 101 种语言中都测量到了相对于 mT5-Base 版本的增益。最后,我们通过在“Colossal Clean Crawled Corpus”上预训练高达万亿参数的模型,推进了语言模型的当前规模,并实现了相对于 T5-XXL 模型 4 倍的加速。
关键词: 混合专家,自然语言处理,稀疏性,大规模机器学习,分布式计算
1. 引言
大规模训练已成为通向灵活且强大的神经语言模型(Radford 等人,2018;Kaplan 等人,2020;Brown 等人,2020)的有效途径。简单的架构——在慷慨的计算预算、数据集大小和参数数量的支持下——超越了更复杂的算法(Sutton,2019)。Radford 等人(2018);Raffel 等人(2019);Brown 等人(2020)采用的方法扩展了密集激活 Transformer(Vaswani 等人,2017)的模型规模。虽然有效,但它在计算上也极其密集(Strubell 等人,2019)。受模型规模成功的启发,但为了寻求更高的计算效率,我们转而提出一种稀疏激活的专家模型:Switch Transformer。在我们的案例中,稀疏性来自于为每个输入示例激活神经网络权重的一个子集。
稀疏训练是一个活跃的研究和工程领域(Gray 等人,2017;Gale 等人,2020),但时至今日,机器学习库和硬件加速器仍然迎合密集矩阵乘法。为了拥有高效的稀疏算法,我们从混合专家(MoE)范式(Jacobs 等人,1991;Jordan 和 Jacobs,1994;Shazeer 等人,2017)开始,并对其进行简化,以获得训练稳定性和计算优势。MoE 模型在机器翻译方面取得了显著成功(Shazeer 等人,2017, 2018;Lepikhin 等人,2020),然而,其广泛应用受到复杂性、通信成本和训练不稳定性的阻碍。
我们解决了这些问题,并超越了翻译领域,发现这类算法在自然语言处理中具有广泛的价值。我们在多样的自然语言任务上以及 NLP 的三个阶段(预训练、微调和多任务训练)中测量到了卓越的扩展性。虽然这项工作侧重于规模,但我们也展示了 Switch Transformer 架构不仅在超级计算机领域表现出色,而且即使只有少数计算核心也同样有益。此外,我们的大型稀疏模型可以被蒸馏(Hinton 等人,2015)成小型密集版本,同时保留稀疏模型 30% 的质量增益。我们的贡献如下:
- Switch Transformer 架构,它简化并改进了混合专家模型。
- 扩展特性以及针对经过强力调优的 T5 模型(Raffel 等人,2019)的基准测试,我们测量到了 7 倍以上的预训练加速,同时每个 token 使用的 FLOPS 相同。我们进一步表明,即使在计算资源有限的情况下,使用少至两个专家,这些改进依然成立。
- 成功将稀疏预训练和专门微调的模型蒸馏为小型密集模型。我们将模型尺寸减少了高达 99%,同时保留了大型稀疏教师模型 30% 的质量增益。
- 改进的预训练和微调技术:(1)选择性精度训练,使得能够使用较低的 bfloat16 精度进行训练;(2)一种初始化方案,允许扩展到更多的专家;(3)增加的专家正则化,改善了稀疏模型的微调和多任务训练。
- 对多语言数据预训练收益的测量,我们发现所有 101 种语言都有普遍的改进,并且 91% 的语言相对于 mT5 基线(Xue 等人,2020)获得了 4 倍以上的加速。
- 通过有效地结合数据、模型和专家并行性,实现了神经语言模型规模的增加,创建了高达万亿参数的模型。这些模型将经过强力调优的 T5-XXL 基线的预训练速度提高了 4 倍。
2. Switch Transformer
Switch Transformer 的指导设计原则是以简单且计算高效的方式最大化 Transformer 模型(Vaswani 等人,2017)的参数数量。Kaplan 等人(2020)详尽研究了规模的好处,揭示了模型大小、数据集大小和计算预算的幂律扩展。重要的是,这项工作提倡在相对较少的数据上训练大型模型,作为计算上的最优方法。
遵循这些结果,我们研究了第四个轴:在保持每个示例的浮点运算(FLOPs)恒定的同时增加参数数量。我们的假设是,参数数量(独立于执行的总计算量)是扩展的一个单独的重要轴。我们通过设计一个稀疏激活模型来实现这一点,该模型有效地使用了为密集矩阵乘法设计的硬件,如 GPU 和 TPU。我们在这里的工作重点是 TPU 架构,但这类模型也可以类似地在 GPU 集群上进行训练。在我们的分布式训练设置中,我们的稀疏激活层在不同设备上拆分唯一的权重。因此,模型的权重随着设备数量的增加而增加,同时在每个设备上保持可管理的内存和计算占用。
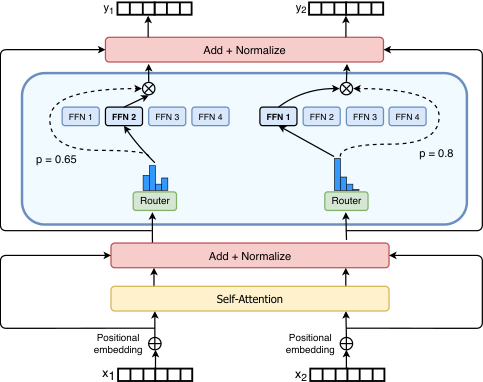
2.1 简化稀疏路由
混合专家路由。 Shazeer 等人(2017)提出了一种自然语言混合专家(MoE)层,它将 token 表示 作为输入,然后将其路由到从 个专家集合 中确定的最佳 top- 专家。路由器变量 产生 logits ,这些 logits 通过该层可用 个专家上的 softmax 分布进行归一化。专家 的门值由下式给出:
选择 top- 门值用于路由 token 。如果 是所选 top- 索引的集合,则该层的输出计算是每个专家对 token 的计算按门值的线性加权组合:
Switch 路由:重新思考混合专家。 Shazeer 等人(2017)推测,路由到 个专家对于路由函数具有非平凡梯度是必要的。作者直觉认为,如果不具备比较至少两个专家的能力,学习路由将无法工作。Ramachandran 和 Le(2018)进一步研究了 top- 决策,发现模型中较低层中较高的 值对于具有许多路由层的模型很重要。与这些想法相反,我们使用了一种简化的策略,即只路由到一个专家。我们展示了这种简化保留了模型质量,减少了路由计算,并且表现更好。这种 的路由策略随后被称为 Switch 层。注意,对于 MoE 和 Switch 路由,方程 2 中的门值 都允许路由器的可微性。
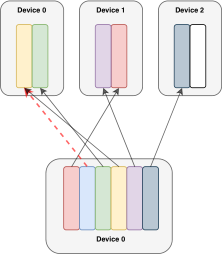
Switch 层的优势有三点:(1)路由器计算减少,因为我们只将一个 token 路由到一个专家。(2)每个专家的批大小(专家容量)至少可以减半,因为每个 token 只被路由到一个专家。(3)路由实现被简化,通信成本降低。图 3 展示了具有不同专家容量因子的路由示例。
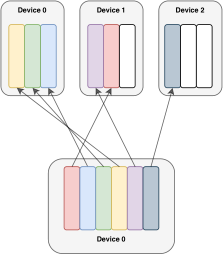
2.2 高效稀疏路由
我们使用 Mesh-Tensorflow (MTF)(Shazeer 等人,2018),这是一个具有与 Tensorflow(Abadi 等人,2016)相似语义和 API 的库,它促进了高效的分布式数据和模型并行架构。它通过将物理核心集抽象为逻辑处理器网格来实现这一点。张量和计算可以按命名维度进行分片,从而促进模型跨维度的轻松分区。我们在设计模型时考虑了 TPU,它需要静态声明的大小。下面我们描述我们的分布式 Switch Transformer 实现。
(注:由于篇幅限制,此处仅翻译了前言、摘要、第 1 节、第 2 节及部分 2.1、2.2 节。如需后续章节的完整翻译,请继续指示。)