通过联合学习对齐与翻译的神经机器翻译
Dzmitry Bahdanau Jacobs University Bremen, Germany
KyungHyun Cho, Yoshua Bengio* Université de Montréal
摘要
神经机器翻译是最近提出的一种机器翻译方法。与传统的统计机器翻译不同,神经机器翻译旨在构建一个单一的神经网络,通过联合调优以最大化翻译性能。最近提出的神经机器翻译模型通常属于编码器-解码器(encoder-decoder)家族,将源句子编码为一个固定长度的向量,解码器再从该向量生成翻译。在本文中,我们推测使用固定长度向量是提升这种基础编码器-解码器架构性能的瓶颈,并提出通过允许模型自动(软)搜索源句子中与预测目标词相关的部分来扩展该架构,而无需显式地将这些部分形成硬片段。通过这种新方法,我们在英法翻译任务上取得了与现有的最先进的基于短语的系统相当的翻译性能。此外,定性分析表明,模型找到的(软)对齐与我们的直觉非常吻合。
1 引言
神经机器翻译是一种新兴的机器翻译方法,由 Kalchbrenner 和 Blunsom (2013)、Sutskever 等人 (2014) 以及 Cho 等人 (2014b) 最近提出。与由许多单独调优的小子组件组成的传统基于短语的翻译系统(参见,例如,Koehn 等人,2003)不同,神经机器翻译试图构建并训练一个单一的、大型的神经网络,该网络读取一个句子并输出正确的翻译。
大多数提出的神经机器翻译模型属于编码器-解码器家族(Sutskever 等人,2014;Cho 等人,2014a),为每种语言配备一个编码器和一个解码器,或者涉及应用于每个句子的特定语言编码器,然后比较其输出(Hermann 和 Blunsom,2014)。编码器神经网络读取源句子并将其编码为一个固定长度的向量。解码器随后从编码后的向量输出翻译。整个编码器-解码器系统由语言对的编码器和解码器组成,通过联合训练以最大化给定源句子时正确翻译的概率。
这种编码器-解码器方法的一个潜在问题是,神经网络需要能够将源句子的所有必要信息压缩到一个固定长度的向量中。这可能使神经网络难以处理长句子,尤其是那些比训练语料库中的句子更长的句子。Cho 等人 (2014b) 表明,基础编码器-解码器的性能确实随着输入句子长度的增加而迅速下降。
为了解决这个问题,我们引入了编码器-解码器模型的扩展,该模型学习联合对齐和翻译。每当提出的模型生成翻译中的一个词时,它都会(软)搜索源句子中集中了最相关信息的一组位置。然后,模型基于与这些源位置相关联的上下文向量以及所有先前生成的目标词来预测目标词。
2 背景:神经机器翻译
从概率的角度来看,翻译等同于找到一个目标句子 ,使得在给定源句子 的条件下, 的条件概率最大化,即 。在神经机器翻译中,我们拟合一个参数化模型,利用平行训练语料库来最大化句子对的条件概率。一旦翻译模型学习到了条件分布,给定一个源句子,就可以通过搜索使条件概率最大化的句子来生成相应的翻译。
最近,许多论文提出了使用神经网络直接学习这种条件分布(参见,例如,Kalchbrenner 和 Blunsom,2013;Cho 等人,2014a;Sutskever 等人,2014;Cho 等人,2014b;Forcada 和 Neco,1997)。这种神经机器翻译方法通常由两个组件组成,第一个组件编码源句子 ,第二个组件解码为目标句子 。例如,(Cho 等人,2014a) 和 (Sutskever 等人,2014) 使用了两个循环神经网络 (RNN) 将变长源句子编码为固定长度向量,并将该向量解码为变长目标句子。
尽管是一种相当新的方法,但神经机器翻译已经显示出令人期待的结果。Sutskever 等人 (2014) 报告称,基于具有长短期记忆 (LSTM) 单元的 RNN 的神经机器翻译在英法翻译任务上达到了接近传统基于短语的机器翻译系统的最先进性能。将神经组件添加到现有的翻译系统中,例如,对短语表中的短语对进行评分 (Cho 等人,2014a) 或对候选翻译进行重排序 (Sutskever 等人,2014),已经能够超越之前的最先进性能水平。
2.1 RNN 编码器-解码器
在此,我们简要描述由 Cho 等人 (2014a) 和 Sutskever 等人 (2014) 提出的基础框架,即 RNN 编码器-解码器,我们在此基础上构建了一种能够同时学习对齐和翻译的新颖架构。
在编码器-解码器框架中,编码器读取输入句子,即向量序列 ,并将其编码为一个向量 。最常见的方法是使用 RNN,使得: 且 其中 是时间 的隐藏状态, 是从隐藏状态序列生成的向量。 和 是一些非线性函数。例如,Sutskever 等人 (2014) 使用 LSTM 作为 ,并令 。
解码器通常经过训练,在给定上下文向量 和所有先前预测的词 的情况下预测下一个词 。换句话说,解码器通过将联合概率分解为有序条件概率来定义翻译 上的概率: 其中 。使用 RNN,每个条件概率建模为: 其中 是一个非线性的、可能是多层的函数,用于输出 的概率, 是 RNN 的隐藏状态。值得注意的是,也可以使用其他架构,例如 RNN 和反卷积神经网络的混合体 (Kalchbrenner 和 Blunsom,2013)。
3 学习对齐与翻译
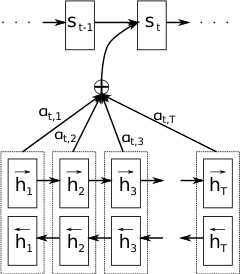
在本节中,我们提出了一种用于神经机器翻译的新颖架构。新架构由作为编码器的双向 RNN(第 3.2 节)和在解码翻译时模拟搜索源句子的解码器(第 3.1 节)组成。
3.1 解码器:通用描述
在新模型架构中,我们将式 (2) 中的每个条件概率定义为: 其中 是时间 的 RNN 隐藏状态,计算方式为: 需要注意的是,与现有的编码器-解码器方法(参见式 (2))不同,这里的概率是针对每个目标词 以不同的上下文向量 为条件的。
上下文向量 取决于编码器将输入句子映射到的注释序列 。每个注释 包含关于整个输入序列的信息,并重点关注输入序列中第 个词周围的部分。我们将在下一节详细解释如何计算这些注释。
上下文向量 随后计算为这些注释 的加权和: 每个注释 的权重 计算如下: 其中 是一个对齐模型,它对输入位置 附近的信息与输出位置 处的输出匹配程度进行评分。该分数基于 RNN 的隐藏状态 (在输出 之前,式 (4))和输入句子的第 个注释 。
我们将对齐模型 参数化为一个前馈神经网络,该网络与所提出系统的所有其他组件联合训练。注意,与传统机器翻译不同,对齐不被视为潜在变量。相反,对齐模型直接计算软对齐,这允许代价函数的梯度通过反向传播。该梯度可用于联合训练对齐模型以及整个翻译模型。
我们可以将取所有注释加权和的方法理解为计算期望注释,其中期望是在可能的对齐上进行的。令 为目标词 与源词 对齐或由其翻译的概率。那么,第 个上下文向量 就是所有注释在概率 下的期望注释。
概率 或其关联的能量 反映了注释 相对于前一个隐藏状态 在决定下一个状态 和生成 时的重要性。直观上,这在解码器中实现了一种注意力机制。解码器决定关注源句子的哪些部分。通过让解码器拥有注意力机制,我们减轻了编码器将源句子中的所有信息编码为固定长度向量的负担。通过这种新方法,信息可以分布在整个注释序列中,解码器可以相应地选择性地检索这些信息。
3.2 编码器:用于注释序列的双向 RNN
式 (1) 中描述的常规 RNN 按顺序读取输入序列 ,从第一个符号 到最后一个符号 。然而,在所提出的方案中,我们希望每个词的注释不仅能总结前面的词,还能总结后面的词。因此,我们建议使用双向 RNN (BiRNN, Schuster 和 Paliwal, 1997),该模型最近已成功应用于语音识别(参见,例如,Graves 等人,2013)。
BiRNN 由前向和后向 RNN 组成。前向 RNN 按顺序读取输入序列(从 到 )并计算前向隐藏状态序列 。后向 RNN 以相反顺序读取序列(从 到 ),从而产生后向隐藏状态序列 。
我们通过连接前向隐藏状态 和后向隐藏状态 来获得每个词 的注释,即 。通过这种方式,注释 包含了前面词和后面词的总结。由于 RNN 倾向于更好地表示最近的输入,注释 将集中在 周围的词上。此注释序列随后被解码器和对齐模型用于计算上下文向量(式 (5)–(6))。
参见图 1 以获取所提出模型的图形说明。
4 实验设置
我们评估了所提出的英法翻译任务方法。我们使用 ACL WMT ’14 提供的双语平行语料库。作为比较,我们还报告了 Cho 等人 (2014a) 最近提出的 RNN 编码器-解码器的性能。我们对两个模型使用相同的训练程序和相同的数据集。
4.1 数据集
WMT ’14 包含以下英法平行语料库:Europarl (61M 词)、新闻评论 (5.5M)、UN (421M) 以及两个分别包含 90M 和 272.5M 词的爬取语料库,总计 850M 词。遵循 Cho 等人 (2014a) 中描述的程序,我们使用 Axelrod 等人 (2011) 的数据选择方法将组合语料库的大小减少到 348M 词。除了提到的平行语料库外,我们不使用任何单语数据,尽管可能使用更大的单语语料库来预训练编码器。我们将 news-test-2012 和 news-test-2013 连接起来作为开发(验证)集,并在 WMT ’14 的测试集(news-test-2014)上评估模型,该测试集包含 3003 个训练数据中不存在的句子。
在常规分词后,我们使用每种语言中最频繁的 30,000 个词的简表来训练我们的模型。任何未包含在简表中的词都被映射为特殊标记 ([UNK])。我们不对数据应用任何其他特殊预处理,例如小写化或词干提取。
4.2 模型
我们训练两种类型的模型。第一种是 RNN 编码器-解码器 (RNNencdec, Cho 等人, 2014a),另一种是所提出的模型,我们将其称为 RNNsearch。我们对每个模型训练两次:首先使用长度不超过 30 个词的句子(RNNencdec-30, RNNsearch-30),然后使用长度不超过 50 个词的句子(RNNencdec-50, RNNsearch-50)。
RNNencdec 的编码器和解码器各有 1000 个隐藏单元。RNNsearch 的编码器由前向和后向循环神经网络 (RNN) 组成,每个网络有 1000 个隐藏单元。其解码器有 1000 个隐藏单元。在这两种情况下,我们都使用具有单个 maxout (Goodfellow 等人, 2013) 隐藏层的多层网络来计算每个目标词的条件概率 (Pascanu 等人, 2014)。
我们使用小批量随机梯度下降 (SGD) 算法以及 Adadelta (Zeiler, 2012) 来训练每个模型。每个 SGD 更新方向使用 80 个句子的小批量计算。我们对每个模型进行了大约 5 天的训练。
模型训练完成后,我们使用束搜索 (beam search) 来寻找近似最大化条件概率的翻译(参见,例如,Graves, 2012; Boulanger-Lewandowski 等人, 2013)。Sutskever 等人 (2014) 使用此方法从他们的神经机器翻译模型中生成翻译。
有关实验中使用的模型架构和训练程序的更多详细信息,请参阅附录 A 和 B。
5 结果
5.1 定量结果
在表 1 中,我们列出了以 BLEU 分数衡量的翻译性能。从表中可以清楚地看出,在所有情况下,所提出的 RNNsearch 都优于传统的 RNNencdec。更重要的是,当仅考虑由已知词组成的句子时,RNNsearch 的性能与传统的基于短语的翻译系统 (Moses) 一样高。考虑到 Moses 除了我们用于训练 RNNsearch 和 RNNencdec 的平行语料库外,还使用了单独的单语语料库(418M 词),这是一个重大的成就。


所提出方法背后的动机之一是基础编码器-解码器方法中使用了固定长度的上下文向量。我们推测这种限制可能导致基础编码器-解码器方法在处理长句子时表现不佳。在图 2 中,我们看到 RNNencdec 的性能随着句子长度的增加而急剧下降。另一方面,RNNsearch-30 和 RNNsearch-50 对句子长度都更加稳健。特别是 RNNsearch-50,即使在长度为 50 或以上的句子中也没有表现出性能下降。所提出模型相对于基础编码器-解码器的这种优越性进一步得到了 RNNsearch-30 甚至优于 RNNencdec-50 的事实的证实(参见表 1)。
| 模型 | 全部 | 无 UNK |
|---|---|---|
| RNNencdec-30 | 13.93 | 24.19 |
| RNNsearch-30 | 21.50 | 31.44 |
| RNNencdec-50 | 17.82 | 26.71 |
| RNNsearch-50 | 26.75 | 34.16 |
| RNNsearch-50* | 28.45 | 36.15 |
| Moses | 33.30 | 35.63 |
表 1:在测试集上计算的训练模型的 BLEU 分数。第二列和第三列分别显示了所有句子的分数,以及在自身和参考翻译中没有任何未知词的句子上的分数。注意,RNNsearch-50 训练时间更长,直到开发集上的性能停止提升。(◦) 当仅评估没有未知词的句子时,我们不允许模型生成 [UNK] 标记(最后一列)。*
5.2 定性分析
5.2.1 对齐
所提出的方法提供了一种直观的方式来检查生成的翻译中的词与源句子中的词之间的(软)对齐。这是通过可视化式 (6) 中的注释权重 来完成的,如图 3 所示。每个图中矩阵的每一行表示与注释相关联的权重。从中我们可以看到在生成目标词时,源句子中的哪些位置被认为更重要。
我们可以从图 3 的对齐中看到,英语和法语之间的词对齐在很大程度上是单调的。我们在每个矩阵的对角线沿线看到了很强的权重。然而,我们也观察到了一些非平凡的、非单调的对齐。形容词和名词在法语和英语中的排序通常不同,我们在图 3 (a) 中看到了一个例子。从该图中,我们看到模型正确地将短语 [European Economic Area] 翻译为 [zone économique européenne]。RNNsearch 能够正确地将 [zone] 与 [Area] 对齐,跳过了两个词([European] 和 [Economic]),然后一次回看一个词来完成整个短语 [zone économique européenne]。
软对齐相对于硬对齐的优势是显而易见的,例如,从图 3 (d) 中可以看出。考虑源短语 [the man],它被翻译为 [l’homme]。任何硬对齐都会将 [the] 映射到 [l’] 并将 [man] 映射到 [homme]。这对翻译没有帮助,因为必须考虑 [the] 后面的词来确定它应该被翻译为 [le]、[la]、[les] 还是 [l’]。我们的软对齐通过让模型同时查看 [the] 和 [man] 自然地解决了这个问题,在这个例子中,我们看到模型能够正确地将 [the] 翻译为 [l’]。我们在图 3 中展示的所有案例中都观察到了类似的行为。软对齐的另一个好处是它自然地处理不同长度的源短语和目标短语,而不需要以反直觉的方式将某些词映射到或从无处([NULL])映射(参见,例如,Koehn, 2010 的第 4 章和第 5 章)。
5.2.2 长句子
从图 2 可以清楚地看出,所提出的模型 (RNNsearch) 在翻译长句子方面比传统模型 (RNNencdec) 好得多。这很可能是因为 RNNsearch 不需要完美地将长句子编码为固定长度的向量,而只需要准确地编码围绕特定词的输入句子部分。
作为一个例子,考虑测试集中的这个源句子: An admitting privilege is the right of a doctor to admit a patient to a hospital or a medical centre to carry out a diagnosis or a procedure, based on his status as a health care worker at a hospital.
RNNencdec-50 将此句子翻译为: Un privilege d’admission est le droit d’un médecin de reconnaître un patient à l’hôpital ou un centre médical d’un diagnostic ou de prendre un diagnostic en fonction de son état de santé.
RNNencdec-50 正确翻译了源句子直到 [a medical center]。然而,从那里开始(下划线部分),它偏离了源句子的原始含义。例如,它将源句子中的 [based on his status as a health care worker at a hospital] 替换为 [en fonction de son état de santé](“基于他的健康状况”)。
另一方面,RNNsearch-50 生成了以下正确的翻译,保留了输入句子的全部含义,没有遗漏任何细节: Un privilège d’admission est le droit d’un médecin d’admettre un patient à un hôpital ou un centre médical pour effectuer un diagnostic ou une procédure, selon son statut de travailleur des soins de santé à l’hôpital.
让我们考虑测试集中的另一个句子: This kind of experience is part of Disney’s efforts to "extend the lifetime of its series and build new relationships with audiences via digital platforms that are becoming ever more important," he added.
RNNencdec-50 的翻译是: Ce type d’expérience fait partie des initiatives du Disney pour "prolonger la durée de vie de ses nouvelles et de développer des liens avec les lecteurs numériques qui deviennent plus complexes.
与前面的例子一样,RNNencdec 在生成大约 30 个词后开始偏离源句子的实际含义(参见下划线短语)。在那之后,翻译质量下降,出现了诸如缺少右引号之类的基本错误。
同样,RNNsearch-50 能够正确翻译这个长句子: Ce genre d’expérience fait partie des efforts de Disney pour "prolonger la durée de vie de ses séries et créer de nouvelles relations avec des publics via des plateformes numériques de plus en plus importantes", a-t-il ajouté.
结合已经呈现的定量结果,这些定性观察证实了我们的假设,即 RNNsearch 架构能够比标准 RNNencdec 模型实现更可靠的长句子翻译。
在附录 C 中,我们提供了由 RNNencdec-50、RNNsearch-50 和 Google Translate 生成的更多长源句子翻译样本,以及参考翻译。
6 相关工作
6.1 学习对齐
Graves (2013) 最近在手写合成的背景下提出了类似的方法,将输出符号与输入符号对齐。手写合成是一项任务,模型被要求生成给定字符序列的手写体。在他的工作中,他使用高斯核混合来计算注释的权重,其中每个核的位置、宽度和混合系数是从对齐模型中预测出来的。更具体地说,他的对齐被限制为预测位置,使得位置单调增加。
与我们的方法的主要区别在于,在 (Graves, 2013) 中,注释权重的模式只向一个方向移动。在机器翻译的背景下,这是一个严重的限制,因为生成语法正确的翻译通常需要(长距离)重排序(例如,英德翻译)。
另一方面,我们的方法需要为翻译中的每个词计算源句子中每个词的注释权重。这个缺点在翻译任务中并不严重,因为大多数输入和输出句子只有 15–40 个词。然而,这可能会限制所提出方案在其他任务中的适用性。
6.2 机器翻译的神经网络
自 Bengio 等人 (2003) 引入神经概率语言模型(该模型使用神经网络来建模给定固定数量前导词的词的条件概率)以来,神经网络已被广泛用于机器翻译。然而,神经网络的作用在很大程度上仅限于为现有的统计机器翻译系统提供单一特征,或对现有系统提供的候选翻译列表进行重排序。
例如,Schwenk (2012) 提出使用前馈神经网络来计算源短语和目标短语对的分数,并将该分数用作基于短语的统计机器翻译系统中的附加特征。最近,Kalchbrenner 和 Blunsom (2013) 以及 Devlin 等人 (2014) 报告了成功使用神经网络作为现有翻译系统的子组件。传统上,训练为目标端语言模型的神经网络已被用于对候选翻译列表进行重新评分或重排序(参见,例如,Schwenk 等人,2006)。
尽管上述方法被证明可以提高相对于最先进机器翻译系统的翻译性能,但我们对设计基于神经网络的全新翻译系统的更宏伟目标更感兴趣。因此,我们在本文中考虑的神经机器翻译方法是对这些早期工作的彻底背离。我们的模型不是将神经网络用作现有系统的一部分,而是独立工作,直接从源句子生成翻译。
7 结论
传统的神经机器翻译方法,称为编码器-解码器方法,将整个输入句子编码为一个固定长度的向量,从中解码出翻译。基于 Cho 等人 (2014b) 和 Pouget-Abadie 等人 (2014) 报告的近期实证研究,我们推测使用固定长度上下文向量对于翻译长句子是有问题的。
在本文中,我们提出了一种解决此问题的新颖架构。我们扩展了基础编码器-解码器,让模型在生成每个目标词时(软)搜索一组输入词或由编码器计算的它们的注释。这使模型无需将整个源句子编码为固定长度的向量,也让模型仅关注与生成下一个目标词相关的信息。这对神经机器翻译系统在长句子上产生良好结果的能力产生了重大的积极影响。与传统的机器翻译系统不同,翻译系统的所有部分,包括对齐机制,都是为了产生正确翻译的更好对数概率而联合训练的。
我们在英法翻译任务上测试了所提出的模型,称为 RNNsearch。实验表明,所提出的 RNNsearch 显著优于传统的编码器-解码器模型 (RNNencdec),无论句子长度如何,并且对源句子的长度更加稳健。从我们调查 RNNsearch 生成的(软)对齐的定性分析中,我们能够得出结论,该模型能够在生成正确翻译的同时,将每个目标词与源句子中的相关词或它们的注释正确对齐。
也许更重要的是,所提出的方法实现了与现有基于短语的统计机器翻译相当的翻译性能。考虑到所提出的架构或整个神经机器翻译家族直到今年才被提出,这是一个惊人的结果。我们相信这里提出的架构是迈向更好的机器翻译和更广泛地理解自然语言的有希望的一步。
留给未来的挑战之一是更好地处理未知词或罕见词。这将是模型被更广泛使用并匹配所有上下文中当前最先进机器翻译系统性能所必需的。
致谢
作者感谢 Theano 的开发者 (Bergstra 等人, 2010; Bastien 等人, 2012)。我们感谢以下机构对研究资助和计算支持的支持:NSERC、Calcul Québec、Compute Canada、Canada Research Chairs 和 CIFAR。Bahdanau 感谢 Planet Intelligent Systems GmbH 的支持。我们还要感谢 Felix Hill、Bart van Merrienboer、Jean Pouget-Abadie、Coline Devin 和 Tae-Ho Kim。
参考文献
(此处省略参考文献列表,保持原论文格式)
附录 A 模型架构
A.1 架构选择
第 3 节中提出的方案是一个通用框架,人们可以在其中自由定义,例如,循环神经网络 (RNN) 的激活函数 和对齐模型 。在此,我们描述了我们在本文实验中所做的选择。
A.1.1 循环神经网络
对于 RNN 的激活函数 ,我们使用 Cho 等人 (2014a) 最近提出的门控隐藏单元。门控隐藏单元是传统简单单元(如元素级 )的替代方案。这种门控单元类似于 Hochreiter 和 Schmidhuber (1997) 早先提出的长短期记忆 (LSTM) 单元,与它共享更好地建模和学习长期依赖关系的能力。这通过在展开的 RNN 中具有导数乘积接近 1 的计算路径成为可能。这些路径允许梯度轻松向后流动,而不会受到太多消失效应的影响 (Hochreiter, 1991; Bengio 等人, 1994; Pascanu 等人, 2013a)。因此,可以使用 LSTM 单元代替此处描述的门控隐藏单元,正如 Sutskever 等人 (2014) 在类似背景下所做的那样。
采用 个门控隐藏单元的 RNN 的新状态 计算为: 其中 是元素级乘法, 是更新门的输出(见下文)。所提出的更新状态 计算为: 其中 是词 的 维嵌入, 是重置门的输出(见下文)。当 表示为 1-of-K 向量时, 仅仅是嵌入矩阵 的一列。只要可能,我们省略偏置项以使方程不那么杂乱。
更新门 允许每个隐藏单元保持其先前的激活,重置门 控制应该重置先前状态的多少和什么信息。我们通过以下方式计算它们: 其中 是逻辑 S 型函数。
在解码器的每一步,我们计算输出概率(式 (4))作为多层函数 (Pascanu 等人, 2014)。我们使用单个 maxout 单元隐藏层 (Goodfellow 等人, 2013) 并使用 softmax 函数归一化输出概率(每个词一个)(参见式 (6))。
A.1.2 对齐模型
设计对齐模型时应考虑到模型需要为每个长度为 和 的句子对评估 次。为了减少计算量,我们使用单层多层感知器,使得: 其中 , 和 是权重矩阵。由于 不依赖于 ,我们可以提前预计算它以最小化计算成本。
A.2 模型的详细描述
A.2.1 编码器
在本节中,我们详细描述实验中使用的所提出模型 (RNNsearch) 的架构(参见第 4–5 节)。从这里开始,为了增加可读性,我们省略所有偏置项。
模型将 1-of-K 编码的词向量源句子作为输入: 并输出 1-of-K 编码的词向量翻译句子: 其中 和 分别是源语言和目标语言的词汇量。 和 分别表示源句子和目标句子的长度。
首先,计算双向循环神经网络 (BiRNN) 的前向状态: 其中 是词嵌入矩阵。, 是权重矩阵。 和 分别是词嵌入维度和隐藏单元数量。 如常是逻辑 S 型函数。
后向状态 的计算方式类似。与权重矩阵不同,我们在前向和后向 RNN 之间共享词嵌入矩阵 。
我们连接前向和后向状态以获得注释 ,其中:
A.2.2 解码器
给定来自编码器的注释,解码器的隐藏状态 s_i计算为: $$s_i = (1 - z_i) \circ s_{i-1} + z_i \circ \tilde{s}_i$$ 其中 $$\tilde{s}_i = \tanh(W E y_{i-1} + U [r_i \circ s_{i-1}] + C c_i)$$ $$z_i = \sigma(W_z E y_{i-1} + U_z s_{i-1} + C_z c_i)$$ $$r_i = \sigma(W_r E y_{i-1} + U_r s_{i-1} + C_r c_i)$$EW, W_z, W_r \in \mathbb{R}^{n \times m}U, U_z, U_r \in \mathbb{R}^{n \times n}C, C_z, C_r \in \mathbb{R}^{n \times 2n}mns_0s_0 = \tanh(W_s \overleftarrow{h}_1)W_s \in \mathbb{R}^{n \times n}$。
上下文向量 在每一步由对齐模型重新计算: 其中 且 是源句子中的第 个注释(参见式 (7))。, 和 是权重矩阵。注意,如果我们固定 为 ,该模型就变成了 RNN 编码器-解码器 (Cho 等人, 2014a)。
利用解码器状态 、上下文 和上一个生成的词 ,我们定义目标词 的概率为: 其中 且 是向量 的第 个元素,计算方式为: ,, 和 是权重矩阵。这可以理解为具有深度输出 (Pascanu 等人, 2014) 和单个 maxout 隐藏层 (Goodfellow 等人, 2013) 的结构。
A.2.3 模型大小
对于本文中使用的所有模型,隐藏层大小 为 1000,词嵌入维度 为 620,深度输出中的 maxout 隐藏层大小 为 500。对齐模型中的隐藏单元数量 为 1000。
B 训练程序
B.1 参数初始化
我们将循环权重矩阵 和 初始化为随机正交矩阵。对于 和 ,我们通过从均值为 0、方差为 的高斯分布中采样每个元素来初始化它们。 的所有元素和所有偏置向量均初始化为零。任何其他权重矩阵均通过从均值为 0、方差为 的高斯分布中采样来初始化。
B.2 训练
我们使用了随机梯度下降 (SGD) 算法。Adadelta (Zeiler, 2012) 被用于自动调整每个参数的学习率( 且 )。我们明确地将代价函数梯度的 范数在每次超过预定义阈值 1 时归一化为该阈值 (Pascanu 等人, 2013b)。每个 SGD 更新方向均使用 80 个句子的小批量进行计算。
在每次更新时,我们的实现所需的时间与小批量中最长句子的长度成正比。因此,为了最大限度地减少计算浪费,在每第 20 次更新之前,我们检索 1600 个句子对,根据长度对它们进行排序,并将它们分成 20 个小批量。训练数据在训练前被打乱一次,并以这种方式按顺序遍历。
在表 2 中,我们提供了与训练实验中使用的所有模型相关的统计数据。
| 模型 | 更新次数 () | 轮数 | 小时数 | GPU | 训练 NLL | 开发 NLL |
|---|---|---|---|---|---|---|
| RNNenc-30 | 8.46 | 6.4 | 109 | TITAN BLACK | 28.1 | 53.0 |
| RNNenc-50 | 6.00 | 4.5 | 108 | Quadro K-6000 | 44.0 | 43.6 |
| RNNsearch-30 | 4.71 | 3.6 | 113 | TITAN BLACK | 26.7 | 47.2 |
| RNNsearch-50 | 2.88 | 2.2 | 111 | Quadro K-6000 | 40.7 | 38.1 |
| RNNsearch-50* | 6.67 | 5.0 | 252 | Quadro K-6000 | 36.7 | 35.2 |
表 2:训练统计数据及相关信息。每次更新对应使用单个小批量更新一次参数。一轮(Epoch)是对训练集的一次遍历。NLL 是训练集或开发集中句子的平均条件对数概率。注意句子长度各不相同。
C 长句子的翻译
(此处为表 3 的内容,展示了 RNNenc-50、RNNsearch-50 和 Google Translate 对长句子的翻译对比,内容已在正文中引用)